
打造 Boba AI
建構 LLM 驅動的生成式應用程式時學到的一些經驗和模式
我們正在建構一個名為「Boba」的實驗性 AI 副駕駛,用於產品策略和生成式構思。在此過程中,我們學到了一些有用的經驗,說明如何建構這類應用程式,並將這些經驗制定成模式。這些模式讓應用程式能協助使用者更有效地與大型語言模型 (LLM) 互動,編排提示以獲得更好的結果,協助使用者在複雜的對話流程中導航,並整合 LLM 無法取得的知識。
2023 年 6 月 29 日

Farooq 是 Thoughtworks 加拿大分公司的產品策略負責人。作為一位專精的通才,擁有產品管理、策略和軟體開發的實務經驗,Farooq 喜歡與客戶合作,解決介於設計、業務和技術之間的困難問題。
Boba 是產品策略和生成式構思的實驗性 AI 副駕駛,旨在擴充創意構思流程。這是一個由 LLM 驅動的應用程式,我們正在建構它以了解
- 如何設計和建構超越聊天機器人的生成式體驗,並由 LLM 驅動
- 如何使用 AI 來擴充我們的產品和策略流程,並進行構思
AI 副駕駛是指一種由人工智慧驅動的助理,旨在協助使用者執行各種任務,通常在不同的脈絡中提供指導、支援和自動化。其應用範例包括導航系統、數位助理和軟體開發環境。我們喜歡將副駕駛視為一個有效的合作夥伴,使用者可以與它合作執行特定領域的任務。
作為 AI 副駕駛的 Boba 旨在擴充策略構思和概念產生的早期階段,而這些階段高度仰賴發散性思考的快速循環(也稱為生成式構思)。我們通常透過與同儕、客戶和主題專家密切合作來實作生成式構思,以便我們能制定和測試創新的想法,以解決客戶的工作、痛點和收穫。這引發了一個問題,如果 AI 也能參與相同的流程呢?如果我們能與 AI 合作,更快地產生和評估更多更好的想法呢?Boba 開始透過使用 OpenAI 的 LLM 來產生想法和回答問題,以擴充並加速創意思考流程。對於 Boba 的第一個原型,我們決定專注於以下功能的基本版本
1. 研究訊號和趨勢:搜尋網路上的文章和新聞,協助你回答定性的研究問題,例如
- 飯店產業目前如何使用生成式 AI?
- 零售商在 2023 年及以後面臨哪些關鍵挑戰?
- 製藥公司如何使用 AI 來加速藥物發現?
- 從 Nike 最近的收益電話會議中獲得了哪些關鍵見解?
- Reddit 上的人如何看待 Lululemon 的產品?
2. 創意矩陣:創意矩陣是一種概念化方法,用於激發不同類別或維度交匯處的新想法。這包括陳述一個策略提示,通常作為一個「我們如何」問題,然後為每個維度交匯處的想法的每個組合/排列回答這個問題。例如
- 策略提示:「我們如何使用生成式 AI 來轉型財富管理?」
- 維度 1 - 價值鏈階段:客戶收購、財務規劃、投資組合構建、投資執行、績效監控、風險管理、報告和溝通
- 維度 2 - 不同角色:針對員工、客戶、合作夥伴
3. 情境建構:情境建構是通過研究商業、文化和技術變化的信號來產生面向未來的故事的過程。情境用於在情境化敘述中社交化學習,激發不同的產品思維,進行彈性/可取性測試和/或告知策略規劃。例如,你可以提示 Boba 以下內容,並根據不同的時間範圍和樂觀主義和現實主義水平獲得一系列未來情境
- 「酒店業使用生成式 AI 來轉變客人體驗」
- 「輝瑞使用生成式 AI 加速藥物發現」
- 「向我展示 10 年後支付的未來」
4. 策略構思:使用「致勝策略」框架,根據策略提示和可能的未來情境集思廣益「在哪裡競爭」和「如何獲勝」的選擇。例如,你可以提示它
- Nike 如何使用生成式 AI 來轉型其商業模式?
- 環球郵報如何增加讀者數量和參與度?
5. 概念生成:根據策略提示(例如「我們如何」問題),生成多個產品或功能概念,其中包括價值主張和要測試的假設。
- 我們如何讓旅行對老年人更方便?
- 我們如何讓購物更具社交性?
6. 故事板:根據簡單的提示或基於當前或未來狀態情境的詳細敘述生成視覺故事板。主要特點是
- 生成插圖場景來描述你的客戶旅程
- 自訂樣式和插圖
- 直接從生成的情境生成故事板
使用 Boba
Boba 是一個網頁應用程式,它在人類使用者和大型語言模型(目前為 GPT 3.5)之間進行互動。一個 LLM 的簡單網頁前端只提供使用者與 LLM 對話的能力。這很有幫助,但這表示使用者需要學習如何有效地與 LLM 互動。即使在 LLM 引起公眾興趣的短時間內,我們已經了解到,建構提示以從 LLM 獲得有用答案需要相當的技巧,因此產生了「提示工程師」的概念。像 Boba 這樣的副駕駛應用程式會新增一系列結構化對話的 UI 元素。這允許使用者提出天真的提示,應用程式可以處理這些提示,使用會從 LLM 產生更好回應的元素來豐富簡單的要求。
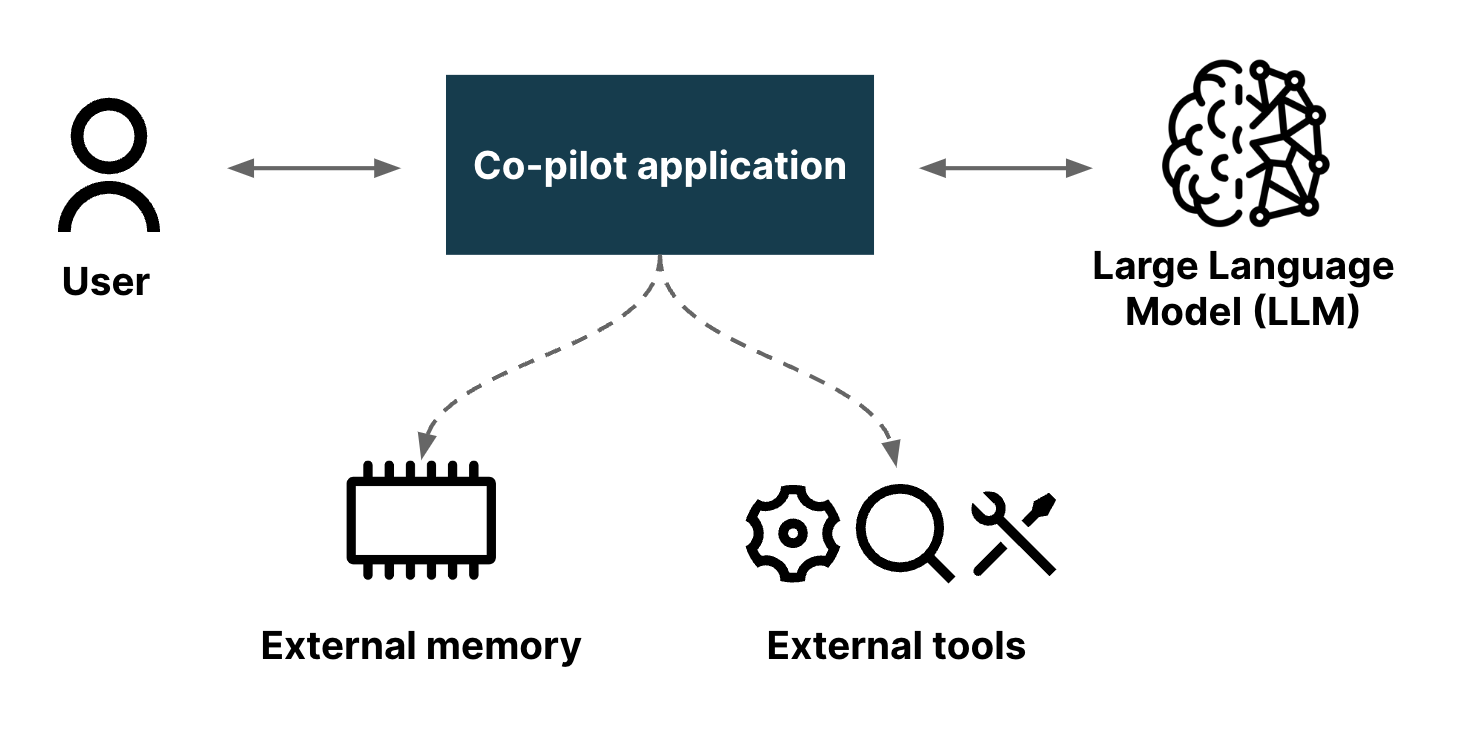
Boba 可以協助許多產品策略任務。我們不會在這裡描述所有任務,只會說明足夠的內容,讓您了解 Boba 的功能,並為本文後面的模式提供背景。
當使用者導覽至 Boba 應用程式時,他們會看到類似以下內容的初始畫面
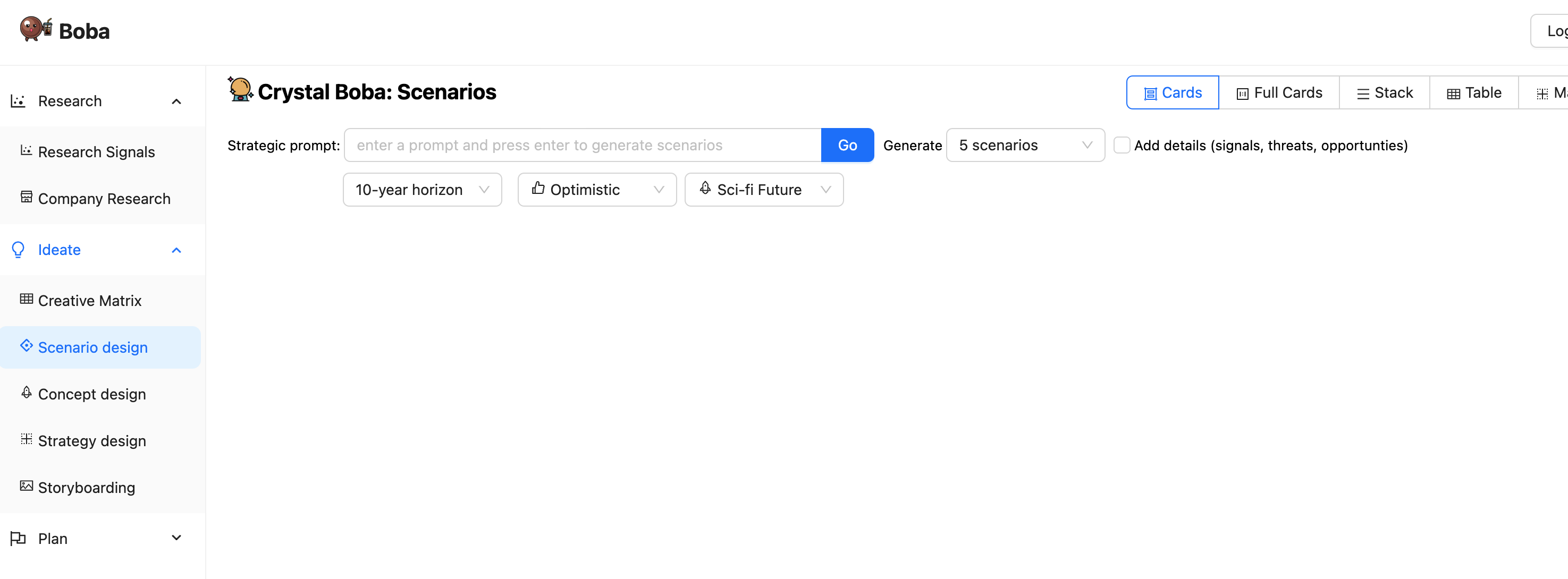
左面板列出 Boba 支援的各種產品策略任務。按一下其中一個會將主面板變更為該任務的 UI。對於其他螢幕截圖,我們將忽略左側的任務面板。
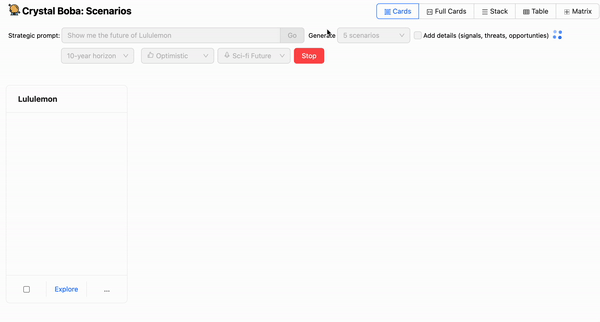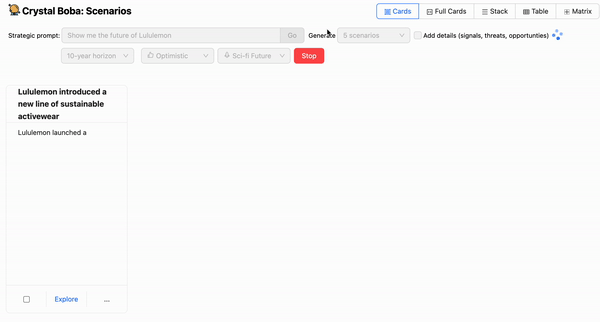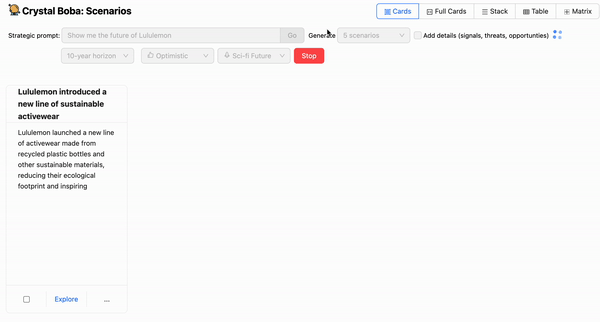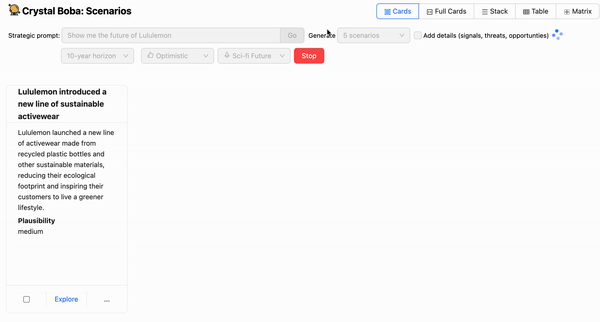
上述螢幕截圖會檢視情境設計任務。這會邀請使用者輸入提示,例如「向我展示零售業的未來」。
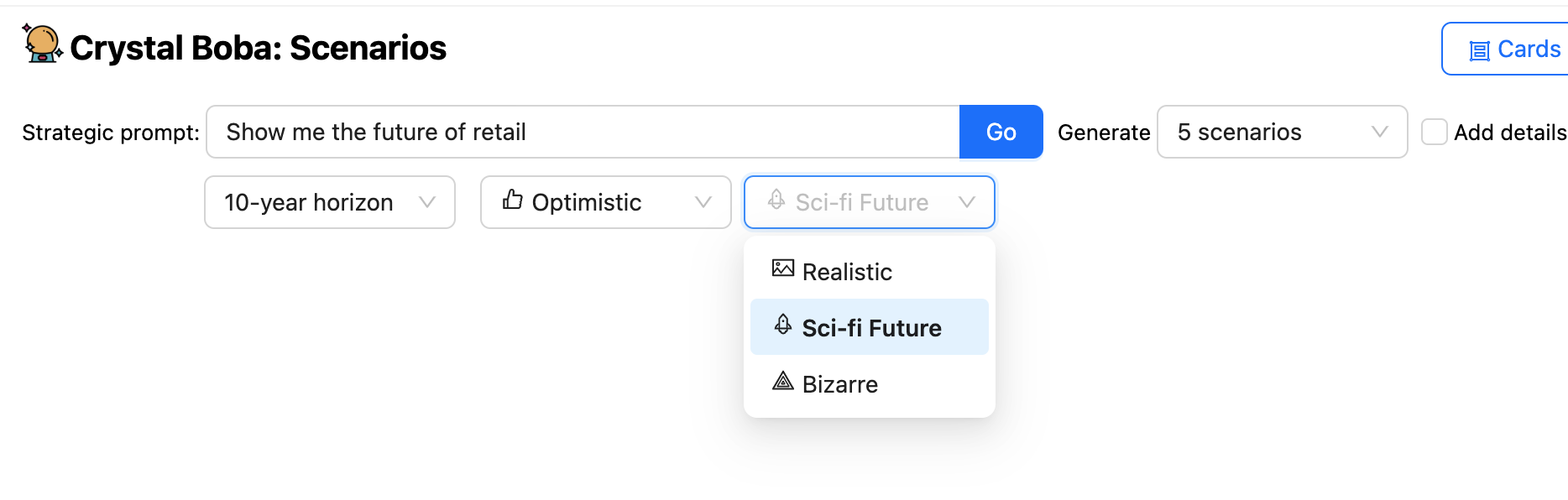
UI 除了提示之外還提供許多下拉式選單,讓使用者可以建議時間範圍和預測的性質。然後,Boba 會要求 LLM 產生情境,使用 範本提示 來使用情境建構任務的一般知識和使用者在 UI 中的選取,來豐富使用者的提示。
Boba 會從 LLM 收到 結構化回應,並將結果顯示為每個情境的 UI 元素組。
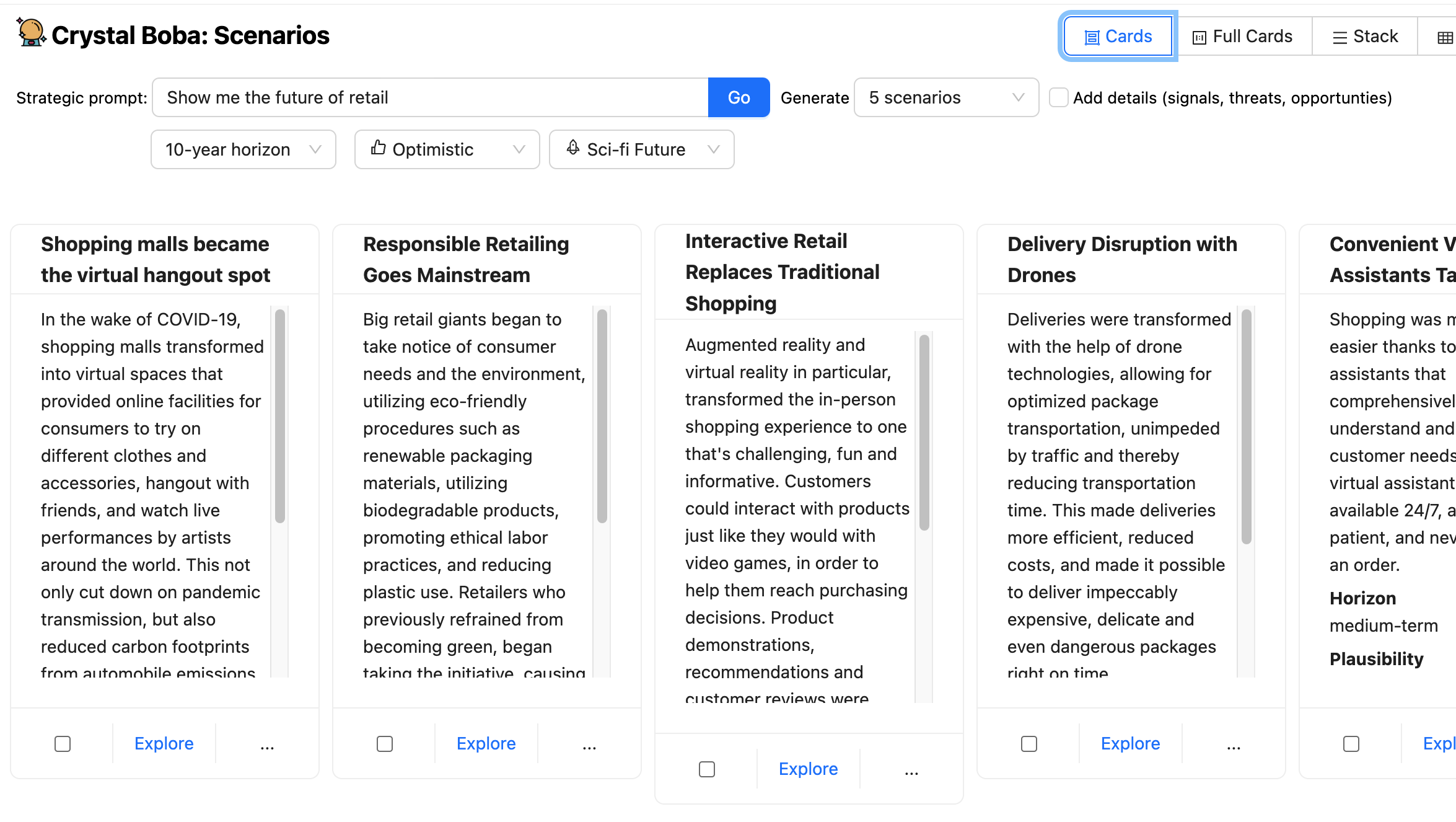
然後,使用者可以選取其中一個情境並按下探索按鈕,開啟一個新的面板,其中包含進一步的提示,以便與 Boba 進行 脈絡對話。
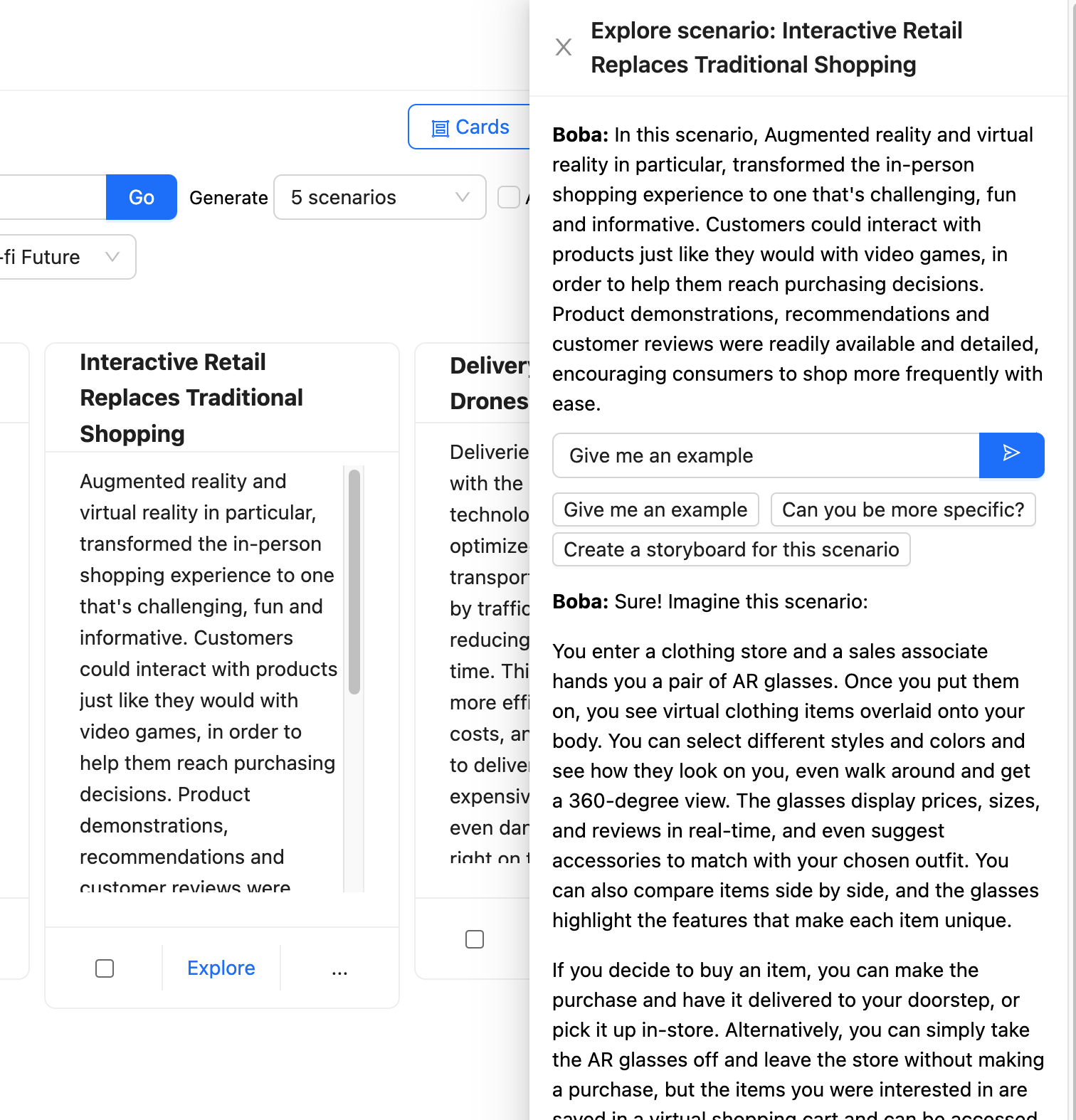
Boba 會取得此提示,並針對所選情境的脈絡進行豐富化,然後再將其傳送給 LLM。
Boba 使用 選取並傳遞脈絡 來保留使用者與 LLM 互動的各個部分,讓使用者可以朝多個方向探索,而不必擔心為每個互動提供正確的脈絡。
使用 LLM 的難處之一在於,其訓練僅限於過去某個時間點前的資料,這使得它們無法處理最新資訊。Boba 有一個名為研究訊號的功能,它使用嵌入式外部知識將 LLM 與一般搜尋功能結合在一起。它會擷取提示式研究查詢,例如「飯店產業目前如何使用生成式 AI?」,將該查詢的豐富版本傳送至搜尋引擎,擷取建議的文章,然後將每篇文章傳送至 LLM 以進行摘要。
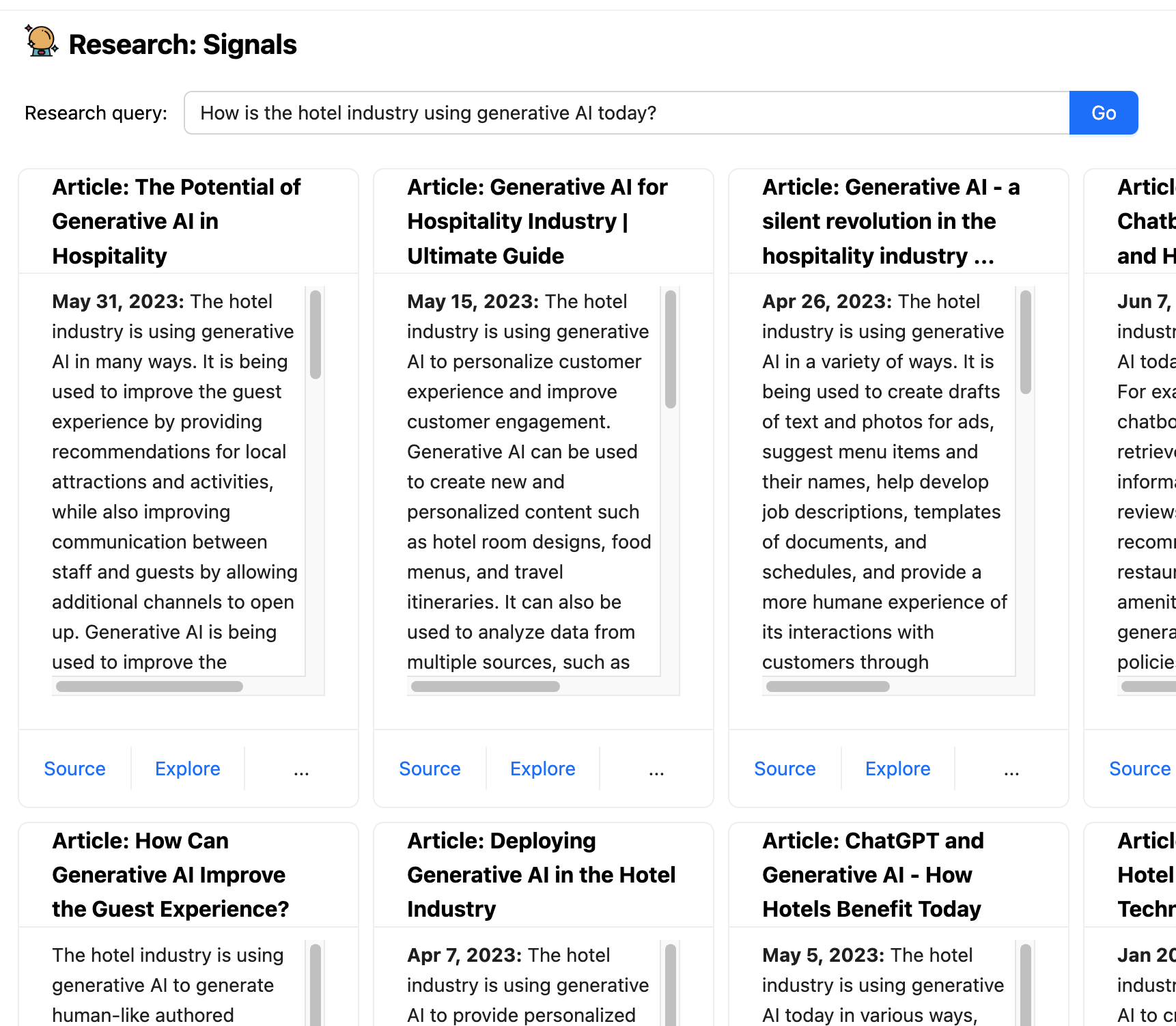
這是一個協同駕駛應用程式如何處理 LLM 單獨不適合的活動互動範例。這不僅提供最新資訊,我們還可以確保提供來源連結給使用者,而且這些連結不會是幻覺(只要搜尋引擎沒有服用錯誤的迷幻藥)。
建構生成式副駕駛應用程式的部分模式
在建構 Boba 時,我們學到了許多關於調解使用者與 LLM(特別是 Open AI 的 GPT3.5/4)之間對話的不同模式和方法。此模式清單並非詳盡無遺,且僅限於我們在建構 Boba 時學到的經驗。
範本提示
使用文字範本來豐富提示,並提供內容和結構
第一個也是最簡單的模式是將字串範本用於提示,也稱為串連。我們使用 Langchain,這是一個提供標準介面,用於鏈和端對端鏈的函式庫,可立即用於一般應用程式。如果您之前使用過 Javascript 範本引擎,例如 Nunjucks、EJS 或 Handlebars,Langchain 提供的正是如此,但專門設計用於一般提示工程工作流程,包括函式輸入變數、少量提示範本、提示驗證和更精密的提示可組合鏈的功能。
例如,若要在 Boba 中集思廣益潛在的未來場景,您可以輸入策略性提示,例如「展示支付的未來」或甚至是簡單的提示,例如公司名稱。使用者介面如下所示

推動此生成的提示範本看起來像這樣
You are a visionary futurist. Given a strategic prompt, you will create
{num_scenarios} futuristic, hypothetical scenarios that happen
{time_horizon} from now. Each scenario must be a {optimism} version of the
future. Each scenario must be {realism}.
Strategic prompt: {strategic_prompt}
正如您所想像的,LLM 的回應只會與提示本身一樣好,因此這就是需要良好提示工程的地方。雖然本文無意成為提示工程的入門,但您會注意到這裡有一些技術在發揮作用,例如從告訴 LLM採用角色開始,特別是富有遠見的未來學家。這是我們在應用程式的各個部分廣泛依賴的一種技術,用於產生更相關且有用的完成。
作為我們測試和學習提示工程工作流程的一部分,我們發現直接在 ChatGPT 中反覆運算提示,提供了從構想到實驗的最短路徑,並有助於快速建立對我們提示的信心。話雖如此,我們也發現我們在使用者介面上花費的時間遠遠多於 AI 本身(約 80%),特別是在設計提示時(約 20%)。
我們也盡可能讓提示範本保持簡單,不使用條件式陳述。當我們需要根據使用者輸入大幅調整提示時,例如當使用者按一下「新增詳細資訊(訊號、威脅、機會)」時,我們決定執行另一個提示範本,以避免提示範本過於複雜且難以維護。
結構化回應
指示 LLM 以結構化資料格式回應
你使用 LLM 建立的幾乎任何應用程式都很有可能需要剖析 LLM 的輸出,以建立一些結構化或半結構化資料,以便進一步代表使用者執行操作。對於 Boba,我們希望盡可能使用 JSON,因此我們嘗試了許多不同的變異,讓 GPT 回傳格式良好的 JSON。我們非常驚訝 GPT 根據提示中的說明,回傳格式良好的 JSON 的表現有多好且一致。例如,以下是情境產生回應說明的範例
You will respond with only a valid JSON array of scenario objects.
Each scenario object will have the following schema:
"title": <string>, //Must be a complete sentence written in the past tense
"summary": <string>, //Scenario description
"plausibility": <string>, //Plausibility of scenario
"horizon": <string>
我們同樣驚訝於它可以支援相當複雜的巢狀 JSON 架構,即使我們使用偽程式碼描述回應架構。以下是如何描述策略產生巢狀回應的範例
You will respond in JSON format containing two keys, "questions" and "strategies", with the respective schemas below:
"questions": [<list of question objects, with each containing the following keys:>]
"question": <string>,
"answer": <string>
"strategies": [<list of strategy objects, with each containing the following keys:>]
"title": <string>,
"summary": <string>,
"problem_diagnosis": <string>,
"winning_aspiration": <string>,
"where_to_play": <string>,
"how_to_win": <string>,
"assumptions": <string>
描述 JSON 回應架構的一個有趣副作用是,我們也可以推動 LLM 在輸出中提供更相關的回應。例如,對於創意矩陣,我們希望 LLM 考量許多不同的面向(提示、列、欄,以及每個想法在每列和每欄交會處對提示的回應)

透過提供包含輸出架構特定範例的少次提示,我們能夠讓 LLM 對每個想法「思考」正確的脈絡(脈絡為提示、列和欄)
You will respond with a valid JSON array, by row by column by idea. For example:
If Rows = "row 0, row 1" and Columns = "column 0, column 1" then you will respond
with the following:
[
{{
"row": "row 0",
"columns": [
{{
"column": "column 0",
"ideas": [
{{
"title": "Idea 0 title for prompt and row 0 and column 0",
"description": "idea 0 for prompt and row 0 and column 0"
}}
]
}},
{{
"column": "column 1",
"ideas": [
{{
"title": "Idea 0 title for prompt and row 0 and column 1",
"description": "idea 0 for prompt and row 0 and column 1"
}}
]
}},
]
}},
{{
"row": "row 1",
"columns": [
{{
"column": "column 0",
"ideas": [
{{
"title": "Idea 0 title for prompt and row 1 and column 0",
"description": "idea 0 for prompt and row 1 and column 0"
}}
]
}},
{{
"column": "column 1",
"ideas": [
{{
"title": "Idea 0 title for prompt and row 1 and column 1",
"description": "idea 0 for prompt and row 1 and column 1"
}}
]
}}
]
}}
]
我們也可以用更簡潔和一般的方式描述架構,但透過在範例中更詳細和具體,我們成功地將 LLM 回應的品質推向我們想要的方面。我們相信這是因為 LLM 以代碼思考,在輸出想法之前輸出(即重複)列和欄值,可以為產生的想法提供更準確的脈絡。
在撰寫本文時,OpenAI 發布了一個名為函式呼叫的新功能,它提供了達成回應格式化目標的不同方式。在這個方法中,開發人員可以將可呼叫函式簽章及其各自的架構描述為 JSON,並讓 LLM 回傳函式呼叫,其中各自的參數以符合該架構的 JSON 提供。這在當你想要呼叫外部工具時特別有用,例如執行網路搜尋或呼叫 API 以回應提示。Langchain 也提供類似的功能,但我認為他們很快就會在他們的外部工具 API 和 OpenAI 函式呼叫 API 之間提供原生整合。
即時進度
將回應串流到 UI,以便使用者可以監控進度
在 LLM 上實作圖形使用者介面時,您會發現的第一件事之一是,等待整個回應完成會花費太長的時間。我們在 ChatGPT 上沒有那麼明顯地注意到這一點,因為它會逐字串流回應。這是一個重要的使用者互動模式,需要記住,因為根據我們的經驗,使用者只能在等待一個旋轉指示器這麼長的時間後才會失去耐心。在我們的案例中,我們不希望使用者等待超過幾秒鐘才開始看到回應,即使它是一個部分回應。
因此,在實作副駕駛體驗時,我們強烈建議在執行需要幾秒鐘才能完成的提示期間顯示即時進度。在我們的案例中,這表示從 LLM 串流世代到 UI 的整個堆疊,即時進行。幸運的是,Langchain 和 OpenAI API 提供了執行此操作的能力
const chat = new ChatOpenAI({
temperature: 1,
modelName: 'gpt-3.5-turbo',
streaming: true,
callbackManager: onTokenStream ?
CallbackManager.fromHandlers({
async handleLLMNewToken(token) {
onTokenStream(token)
},
}) : undefined
});
這讓我們能夠提供建立更順暢使用者體驗所需的即時進度,包括在產生的想法不符合使用者期望時,停止產生中段的能力
然而,這樣做會為您的應用程式邏輯增加許多額外的複雜性,特別是在檢視和控制器上。在 Boba 的案例中,我們還必須執行 JSON 的盡力解析,並在執行 LLM 呼叫期間維護暫時狀態。在撰寫本文時,一些新的且有前途的函式庫正在推出,讓網路開發人員更容易執行此操作。例如,Vercel AI SDK 是用於建立邊緣就緒 AI 驅動的串流文字和聊天 UI 的函式庫。
選擇並傳遞脈絡
擷取並將相關內容資訊新增至後續動作
聊天介面的最大限制之一是使用者只能使用單執行緒內容:對話聊天視窗。在設計副駕駛體驗時,我們建議深入思考如何設計 UX 負擔,以便在選取的內容中執行動作,類似於我們在現實生活中指向某個事物,在動作或描述的內容中。
選擇並攜帶脈絡讓使用者縮小或擴大互動範圍以執行後續任務,也稱為任務脈絡。這通常是透過在使用者介面中選擇一個或多個元素,然後對它們執行動作來完成。例如,在 Boba 中,我們使用此模式讓使用者透過選擇一個概念(例如情境、策略或原型概念)來針對該概念進行更狹窄、更聚焦的對話,以及選擇和產生概念的變體。首先,使用者選擇一個概念(透過核取方塊明確選擇或透過按一下連結隱含選擇)
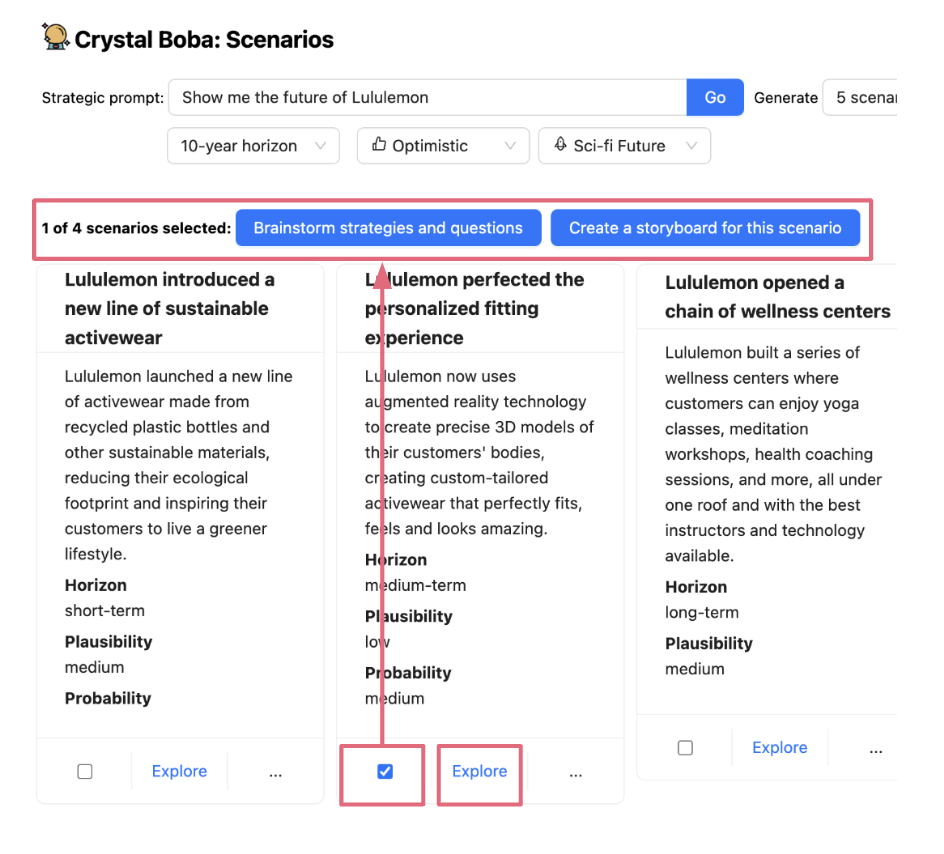
然後,當使用者對選擇執行動作時,選取的項目會作為脈絡傳遞到新任務中,例如當使用者按一下「為此情境集思廣益策略和問題」時,會作為策略產生的情境子提示,或當使用者按一下探索時,會作為自然語言對話的脈絡
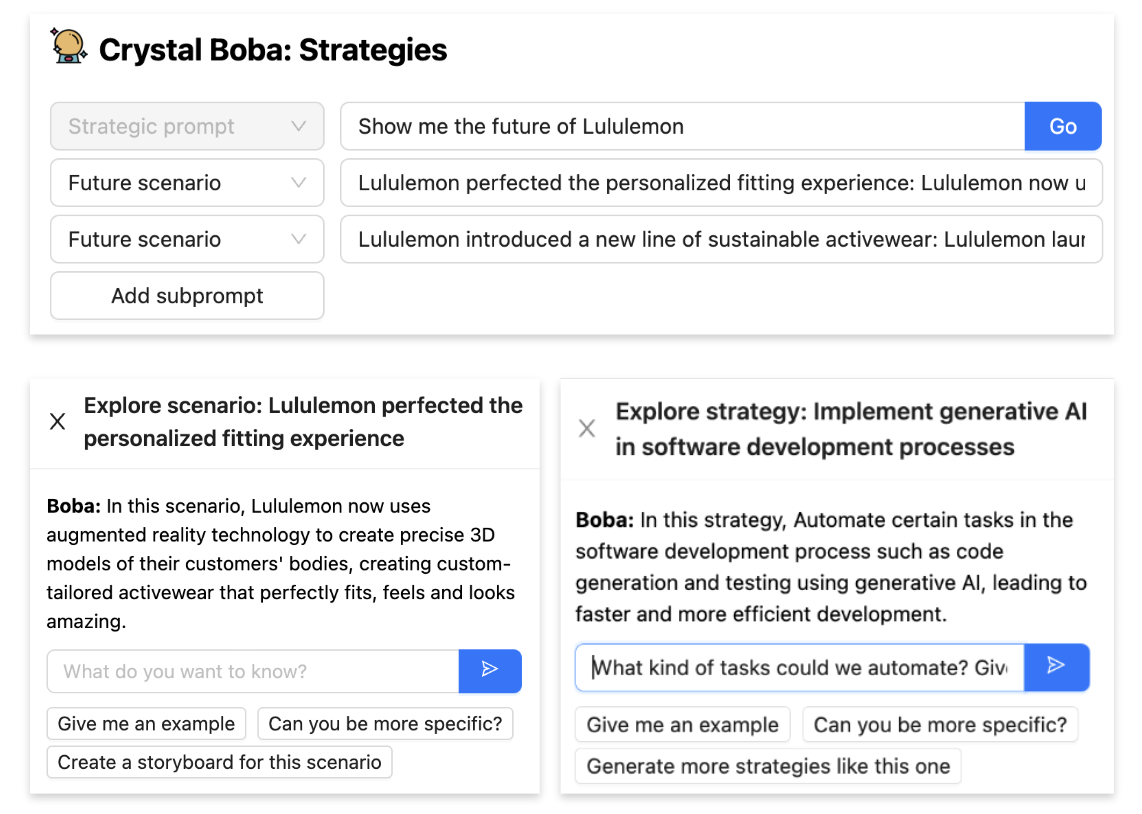
根據您希望為對話/互動區段建立的脈絡性質和長度,實作選擇並攜帶脈絡可能非常容易,也可能非常困難。當脈絡簡短且可以放入單一 LLM 脈絡視窗(LLM 支援的提示最大大小)時,我們可以單獨透過提示工程來實作它。例如,在 Boba 中,如上所示,您可以在一個概念上按一下「探索」,然後與 Boba 針對該概念進行對話。我們在後端實作此功能的方式是建立多則訊息聊天對話
const chatPrompt = ChatPromptTemplate.fromPromptMessages([
HumanMessagePromptTemplate.fromTemplate(contextPrompt),
HumanMessagePromptTemplate.fromTemplate("{input}"),
]);
const formattedPrompt = await chatPrompt.formatPromptValue({
input: input
})
實作選擇並攜帶脈絡的另一種技術是在提示中透過在標籤分隔符號內提供脈絡來執行此操作,如下所示。在這種情況下,使用者已選擇多個情境,並希望為這些情境產生策略(這是一種經常在情境建構和概念壓力測試中使用的技術)。我們希望傳遞到策略產生的脈絡是所選情境的集合
Your questions and strategies must be specific to realizing the following
potential future scenarios (if any)
<scenarios>
{scenarios_subprompt}
</scenarios>
但是,當您的脈絡超出 LLM 的脈絡視窗,或者如果您需要提供更複雜的過去互動鏈時,您可能必須使用外部短期記憶體,這通常涉及使用向量儲存(記憶體內或外部)。我們將在嵌入外部知識中提供如何執行類似操作的範例。
如果您想進一步瞭解在生成式應用程式中有效使用選擇和脈絡,我們強烈推薦 Notion 的 Linus Lee 在 LLMs in Production 會議上發表的演講:“超越聊天的生成式體驗”。
脈絡對話
允許在脈絡中與 LLM 直接對話。
這是 選擇和執行內容 的特殊情況。雖然我們希望 Boba 盡可能地跳脫聊天視窗互動模式,但我們發現提供使用者一個「後備」管道直接與 LLM 對話仍然非常有用。這讓我們能夠為我們在 UI 中不支援的互動提供對話體驗,並支援在文字自然語言對話對使用者來說最有意義的情況。
在以下範例中,使用者正在與 Boba 聊天,討論 Rogers Sportsnet 提供的個人化精華片段概念。完整的內容以聊天訊息的形式提及(「在這個概念中,探索你喜愛的運動世界...」),而使用者已要求 Boba 為這個概念建立使用者旅程。LLM 的回應以 Markdown 格式化並呈現
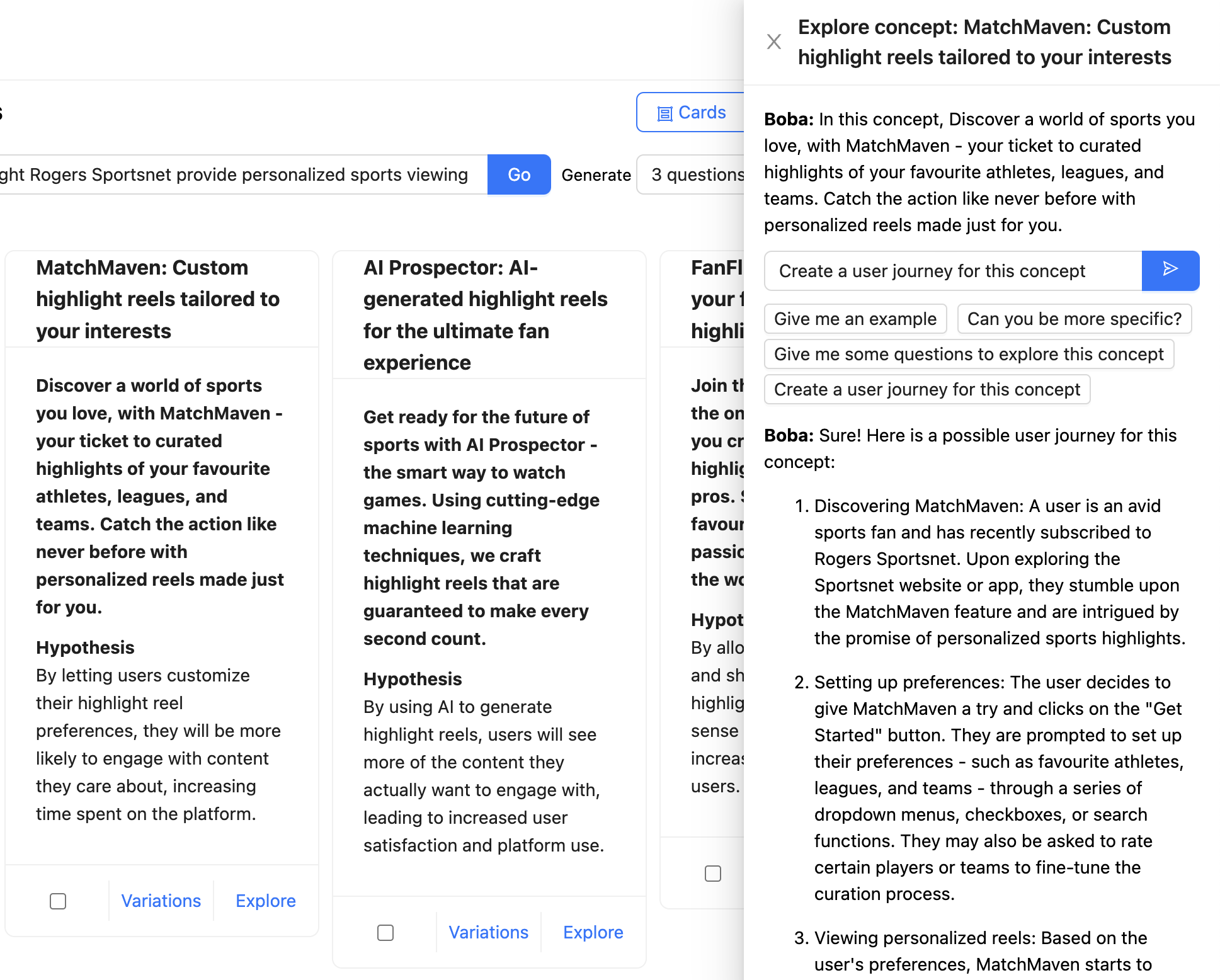
在設計生成式副駕駛體驗時,我們強烈建議支援應用程式的脈絡對話。務必提供使用者可以傳送給應用程式的有用訊息範例,讓他們知道可以參與哪些類型的對話。在 Boba 的情況中,如上方的螢幕截圖所示,這些範例以輸入方塊下的訊息範本提供,例如「你能更具體說明嗎?」
大聲思考
在回答時告訴 LLM 產生中間結果
儘管 LLM 實際上並不會「思考」,但值得比喻性地思考 OpenAI 的 Andrei Karpathy 的一句話:“LLM 以代幣『思考』。” 他的意思是,GPT 在嘗試立即回答問題時,比在給予更多時間(即更多代幣)「思考」時更容易產生推理錯誤。在建立 Boba 時,我們發現使用思考鏈 (CoT) 提示,或更具體地說,在回答之前要求提供推理鏈,有助於 LLM 推理出更高品質且更相關的回應。
在 Boba 的某些部分,例如策略和概念產生,我們要求 LLM 在產生想法(本例中為策略和概念)之前產生一組問題,以擴充使用者的輸入提示。
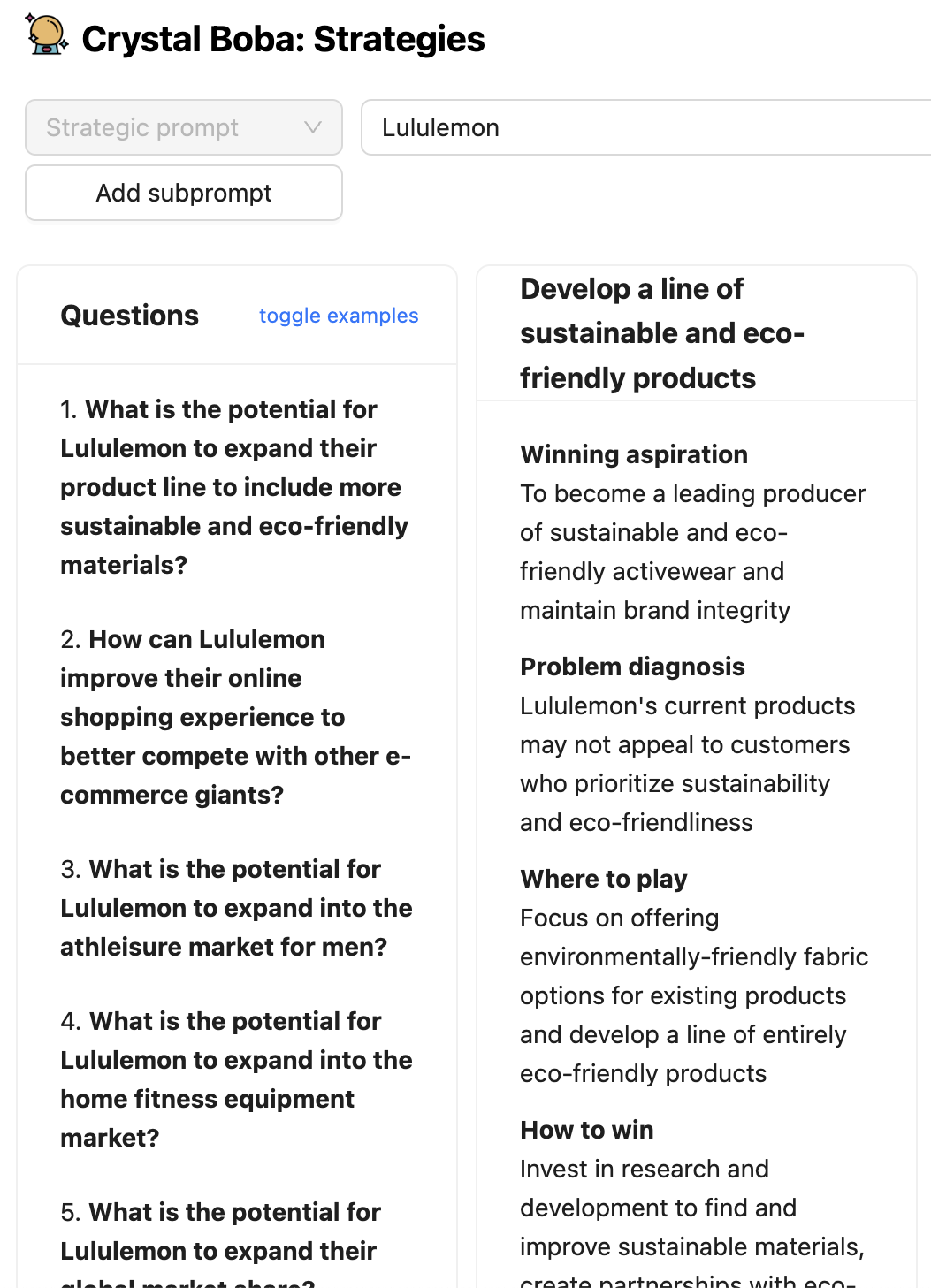
雖然我們顯示 LLM 產生的問題,但此模式同樣有效的變體是實作使用者不會接觸到的內部獨白。在這種情況下,我們會要求 LLM 思考他們的回應,並將該內部獨白放入回應的單獨部分,我們可以在顯示給使用者的結果中分析並忽略它。可以在 OpenAI 的 GPT 最佳實務指南 中找到此模式的更詳細說明,請參閱 給 GPT 時間「思考」 一節
作為生成式應用程式的使用者體驗模式,我們發現適時與使用者分享推理過程很有幫助,這樣使用者就能有額外的內容來反覆執行下一個動作或提示。例如,在 Boba 中,知道 Boba 想到的問題類型,可以讓使用者對要探索或不探索的不同領域有更多想法。它也允許使用者要求 Boba 在下一次反覆運算中排除某些類型的想法。如果你走這條路,我們建議建立一個 UI 範例來隱藏獨白或思考鏈,例如 Boba 上方顯示範例的切換功能。
反覆回應
提供用戶與副駕駛進行雙向互動的可能性
LLM 勢必會誤解使用者的意圖,或僅產生不符合使用者預期的回應。因此,您的生成式應用程式也會如此。ChatGPT 與傳統聊天機器人的最大區別在於靈活地反覆運算和調整對話方向的能力,進而提升回應的品質和相關性。
同樣地,我們相信生成式副駕駛體驗的品質取決於使用者與副駕駛進行流暢雙向互動的能力。這就是我們所稱的「回應反覆運算」模式。這可能涉及多種方法
- 更正提供給應用程式/LLM 的原始輸入
- 調整副駕駛回應給使用者的部分內容
- 提供回饋,引導應用程式朝不同方向發展
我們在 Boba 中實作「反覆運算回應」的一個範例是在分鏡腳本中。針對提示(簡短或詳細),Boba 可以產生視覺分鏡腳本,其中包含多個場景,每個場景都有敘事腳本和使用 Stable Diffusion 產生的影像。例如,以下是描述「未來飯店」體驗的部分分鏡腳本
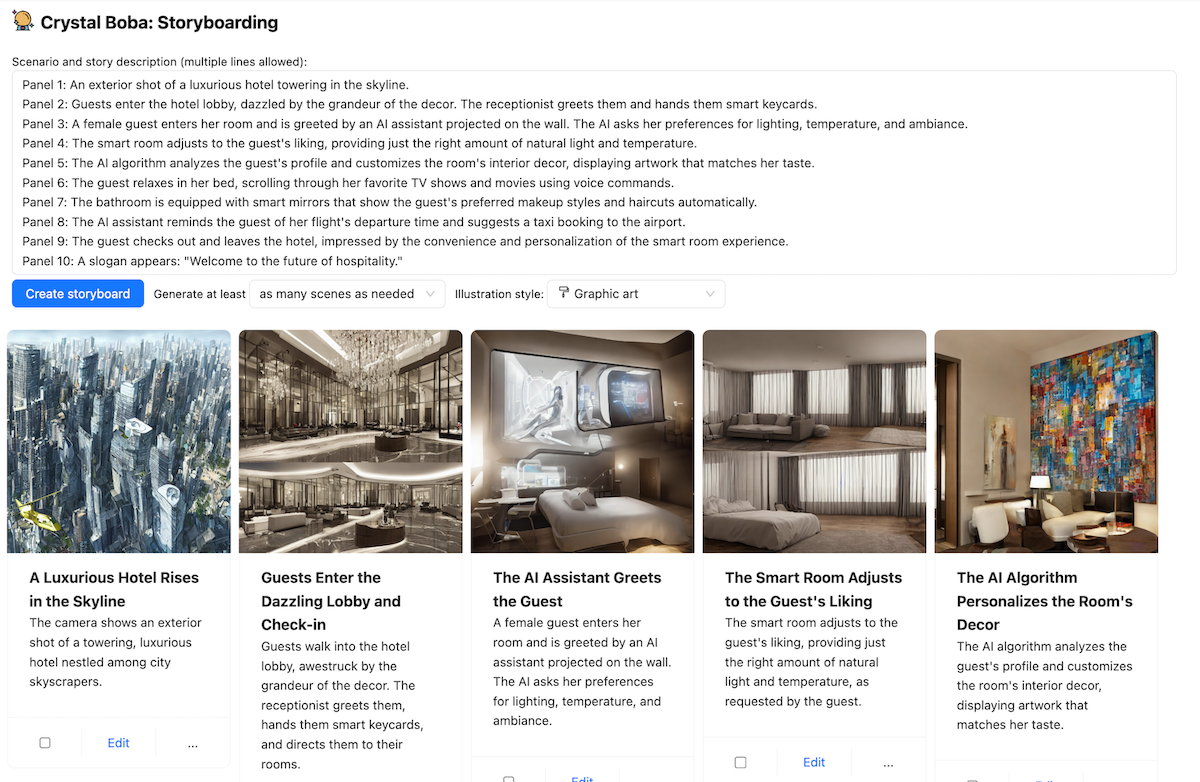
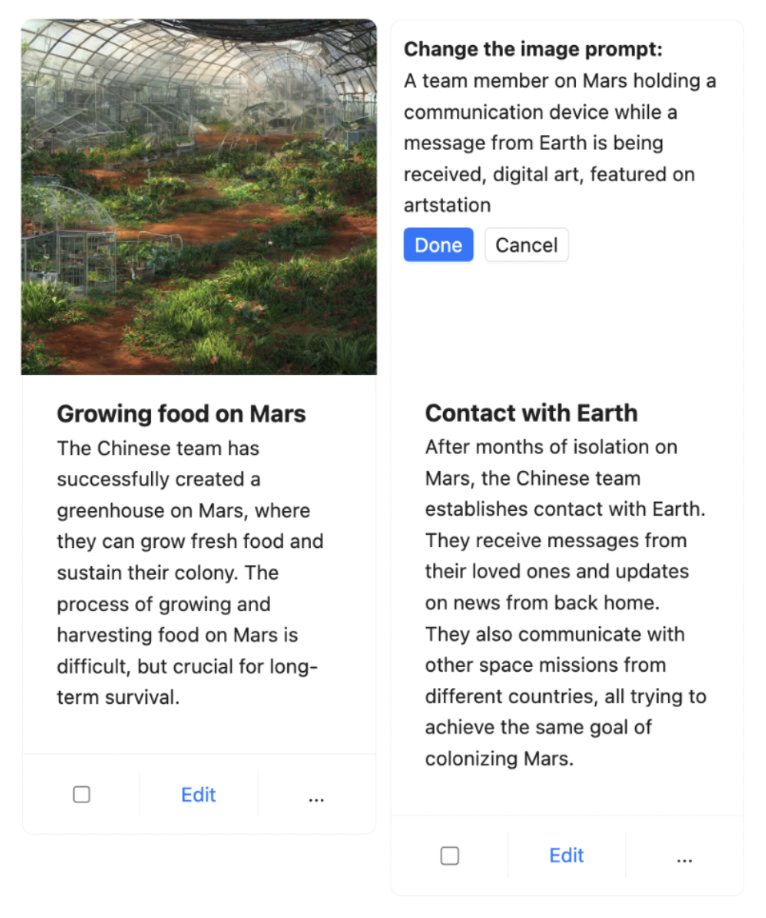
由於 Boba 使用 LLM 產生 Stable Diffusion 提示,因此我們不知道影像品質會如何,所以這個功能有點碰運氣。為了彌補這一點,我們決定提供使用者反覆運算影像提示的能力,以便他們可以調整特定場景的影像。使用者只需按一下影像、更新 Stable Diffusion 提示,然後按下「完成」,Boba 便會使用更新的提示產生新的影像,同時保留分鏡腳本的其餘部分
我們目前正在開發的另一個「反覆運算回應」範例是使用者提供回饋給 Boba 的功能,說明所產生點子的品質,這將結合「選擇並傳遞脈絡」和「反覆運算回應」。一種方法是在點子上按讚或按倒讚,讓 Boba 將該回饋納入新的或下一組建議中。另一種方法是以自然語言的形式提供對話式回饋。無論如何,我們希望以支援強化學習的方式進行(隨著您提供更多回饋,點子會變得更好)。一個很好的範例是 Github Copilot,它會將使用者忽略的程式碼建議降級,以排名下一組最佳程式碼建議。
我們相信這是實作有效生成式體驗最重要的模式之一,儘管它是一個通用的架構。具有挑戰性的部分是將回饋脈絡納入後續回應中,由於脈絡視窗的大小有限,這通常需要在您的應用程式中實作短期或長期記憶體。
嵌入式外部知識
將 LLM 與其他資訊來源結合,以存取 LLM 訓練集以外的資料
如本文稍早所提,你的生成式應用程式常常需要 LLM 結合外部工具(例如 API 呼叫)或外部記憶體(短期或長期)。當我們在 Boba 中實作研究功能時遇到了這個情況,該功能允許使用者根據網路上公開的資訊回答定性研究問題,例如「飯店產業現今如何使用生成式 AI?」
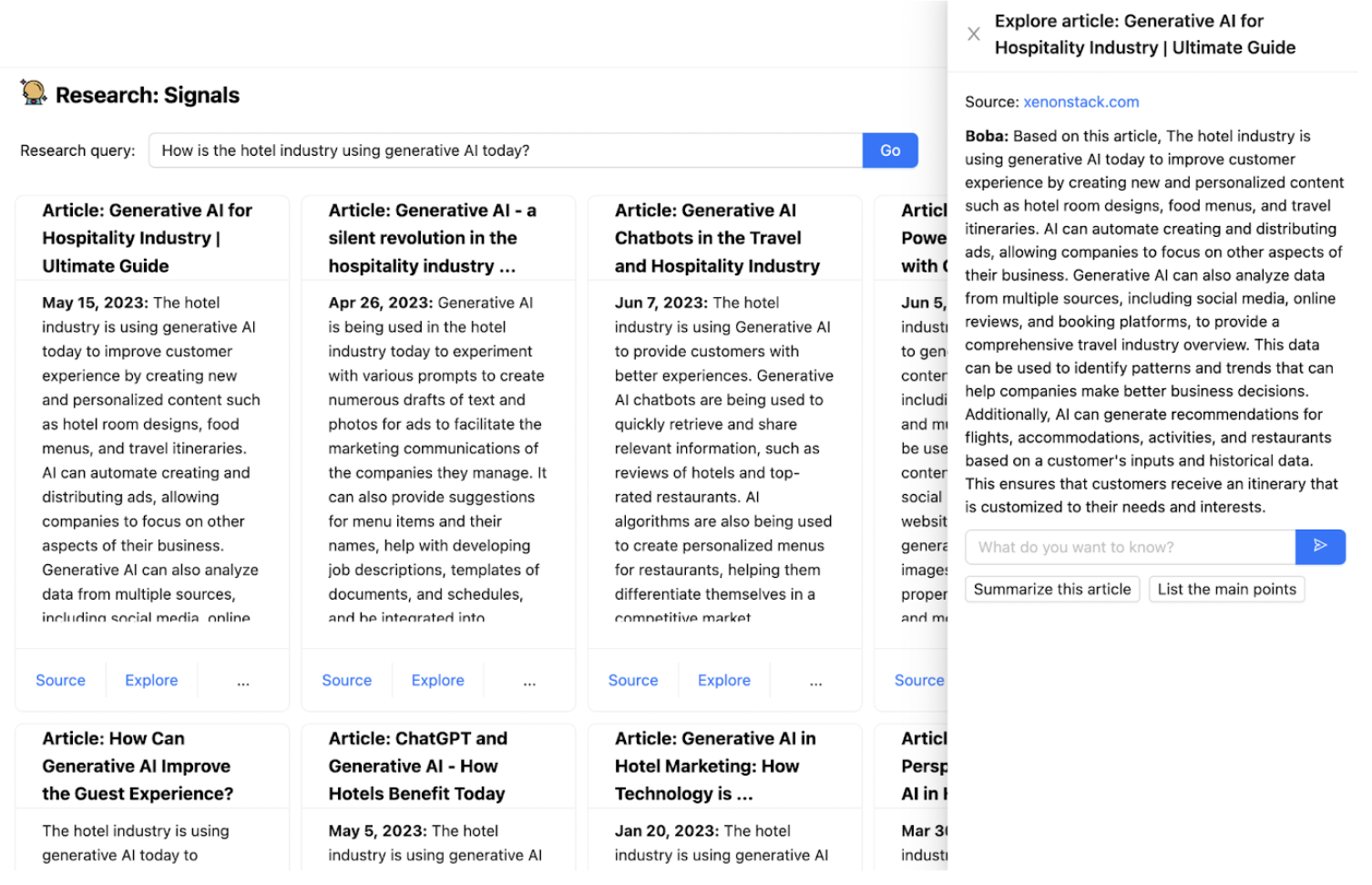
為實作此功能,我們必須「裝備」LLM,使用 Google 作為外部網路搜尋工具,並賦予 LLM 閱讀可能很長且不符合提示脈絡視窗的文章的能力。我們也希望 Boba 能夠與使用者討論使用者找到的任何相關文章,這需要實作一種短期記憶體形式。最後,我們希望提供使用者適當的連結和參考,用於回答使用者的研究問題。
我們在 Boba 中實作此功能的方式如下
- 使用 Google SERP API 根據使用者的查詢執行網路搜尋,並取得前 10 篇文章(搜尋結果)
- 使用 Extract API 閱讀每篇文章的完整內容
- 將每篇文章的內容儲存在短期記憶體中,特別是記憶體中的向量儲存區。向量儲存區的嵌入是使用 OpenAI API 產生的,並根據每篇文章的區塊(相對於嵌入整篇文章本身)產生。
- 產生使用者的搜尋查詢嵌入
- 使用搜尋查詢的嵌入查詢向量儲存區
- 提示 LLM 以自然語言回答使用者的原始查詢,同時將向量儲存區查詢的結果作為脈絡加到 LLM 提示中。
這聽起來可能像很多步驟,但這正是使用 Langchain 等工具可以加速你的流程的地方。特別是,Langchain 有個稱為 VectorDBQAChain 的端對端鏈,使用它來執行問答只需在 Boba 中撰寫幾行程式碼
const researchArticle = async (article, prompt) => {
const model = new OpenAI({});
const text = article.text;
const textSplitter = new RecursiveCharacterTextSplitter({ chunkSize: 1000 });
const docs = await textSplitter.createDocuments([text]);
const vectorStore = await HNSWLib.fromDocuments(docs, new OpenAIEmbeddings());
const chain = VectorDBQAChain.fromLLM(model, vectorStore);
const res = await chain.call({
input_documents: docs,
query: prompt + ". Be detailed in your response.",
});
return { research_answer: res.text };
};
文章文字包含文章的完整內容,這可能不符合單一提示。因此,我們執行上述步驟。如你所見,我們使用稱為 HNSWLib(階層式可導航小世界)的記憶體中向量儲存區。HNSW 圖形是向量相似性搜尋中效能最佳的索引之一。然而,對於更大規模的使用案例和/或長期記憶體,我們建議使用外部向量資料庫,例如 Pinecone 或 Weaviate。
我們也可以使用 Langchain 的外部工具 API 來執行 Google 搜尋,進一步簡化我們的流程,但我們決定不這麼做,因為它將過多決策外包給 Langchain,而且我們得到的結果參差不齊、速度慢且難以解析。實作外部工具的另一種方法是使用 Open AI 最近發布的函式呼叫 API,我們在本文稍早提到過。
總之,我們結合了兩種不同的技術來實作嵌入式外部知識
- 使用外部工具:使用 Google SERP 搜尋和閱讀文章,並擷取 API
- 使用外部記憶體:使用記憶體內向量儲存 (HNSWLib) 的短期記憶體
未來計畫和模式
到目前為止,我們僅透過 Boba 原型初步了解產品策略和生成式構想的生成式副駕駛可能包含哪些內容。關於建置由 LLM 驅動的生成式副駕駛應用程式的技術,還有很多東西需要學習和分享,我們希望在未來幾個月內完成。這是從事這類新應用程式和體驗的令人興奮時刻,我們相信許多原則、模式和實務還有待發現!
重大修訂
2023 年 6 月 29 日:首次發布