我如何來到這裡?
我最初接觸到 依賴反轉原則 是在 1994 年左右,由 Robert (Uncle Bob) Martin 介紹的。它與大多數 SOLID 原則 一樣,陳述起來很簡單,但應用起來卻很深入。以下是我在實際專案中使用的一些近期應用;我討論的所有內容都已於 2012 年 6 月投入生產,截至 2013 年年中仍持續生產中。其中一些可以追溯到更早之前,但一直不斷地被使用,這提醒了我基礎知識的重要性。
DIP 的概要
表達依賴反轉原則的方法有很多
抽象不應依賴於細節
程式碼應依賴於同層級或更高層級抽象的事物
高層級政策不應依賴於低層級細節
在與網域相關的抽象中擷取低層級依賴關係
這些原則的共同點在於從系統的一部份到另一部份的觀點;努力讓依賴關係朝向更高層級(更接近網域)的抽象。
網域分析:柏拉圖理想主義的問題
我在 90 年代初期正式接觸到網域分析。第一個對我影響很大的來源是 物件導向開發:融合方法 。
當時,我獨立於所考慮的問題進行網域分析。在那十年後,我逐漸得出結論,如果考慮問題,網域分析會更有效。為什麼?因為最終一切事物都以多種方式與其他事物相關。網域分析是一種 建模 形式。對我來說,建模的一項關鍵在於,你只考慮重要的細節。你如何決定什麼是重要的?只考慮與你想要完成的事項相關的網域部份。
這裡有一個先有雞還是先有蛋的問題。領域是由問題告知的,反之亦然。系統邊界也發揮了作用。為了處理所有這些相互依賴性,我們進行三角測量。當我們開始對問題、領域和系統邊界有更好的了解時,我們就能更好地考慮任何特定抽象的適當性。
在本文中,當我提到領域時,我的意思是受某些功能集限制的領域,而不是存在於此類上下文之外的神話領域。從某種意義上說,這是 YAGNI 應用於領域分析。
為何要關心依賴性?
依賴性是一種風險。例如,如果我的系統需要安裝 Java Runtime Environment (JRE),而沒有安裝,我的系統將無法工作。我的系統可能還需要某種作業系統。如果使用者透過網路存取系統,則需要使用者有瀏覽器。其中一些依賴性由你控制或限制,其他則你可以忽略。例如,
在 JRE 需求的情況下,你可以確保部署環境已安裝適當版本的 JRE。或者,如果環境是固定的,你可以調整程式碼以符合 JRE。你可以使用 Puppet 等工具控制環境,以從更簡單、已知的啟動映像建立環境。無論如何,儘管後果嚴重,但透過幾個選項來減輕後果,這一點是眾所周知的。(我個人偏好 CD 範圍的末端。)
當你的系統使用 String 類別時,你可能不會反轉該依賴性。例如,如果你將 String 視為原語(嚴格來說不是,但足夠接近),那麼操作多個 String 就開始類似於 原語迷戀 。如果你在 String 周圍引入一個類型,並新增對這些 String 的使用有意義的方法,而不是僅公開 String 方法,那麼只要結果類型比 String 更接近你的領域,這就開始看起來像一種依賴性反轉。
對於瀏覽器來說,如果您想要現代化的體驗,將很難支援所有瀏覽器。您可以嘗試允許所有瀏覽器和版本、限制支援相對現代的瀏覽器或引入功能降級。這種依賴關係很複雜,可能需要多方面的解決方法。
依賴關係代表風險。處理該風險需要一些成本。透過經驗、試驗和錯誤,或團隊的集體智慧,您可以選擇明確減輕該風險,或不減輕。
反轉與什麼相比?
反轉是方向的逆轉,但與什麼相比的逆轉?結構化分析與設計 的設計部分。
在結構化分析與設計中,我們從高階問題開始,並將其分解成較小的部分。對於仍然「太大」的任何較小部分,我們會繼續將其分解。高階概念/需求/問題被分解成越來越小的部分。高階設計以這些越來越小的部分來描述,因此它直接依賴於較小且更詳細的部分。這也稱為自上而下的設計。考慮這個問題描述(有點理想化和簡化,但否則在野外發現)
報告節能
收集資料
開啟連線
執行 SQL
轉譯結果集
計算基準線
決定基準線群組
專案時間序列資料
計算日期範圍
產品報告
決定非基準線群組
專案時間序列資料
計算資料範圍
計算基準線的增量
格式化結果
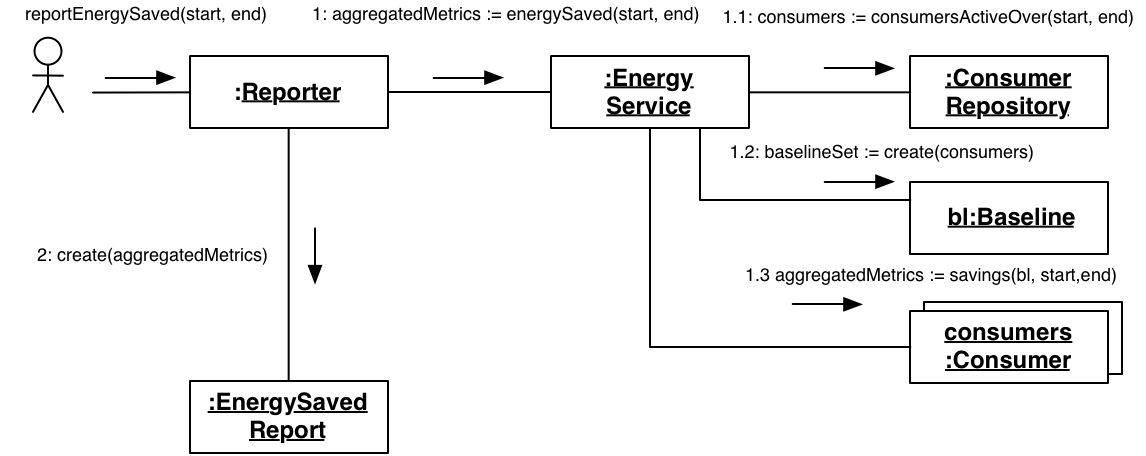
報告節能的業務需求取決於資料收集,而資料收集取決於執行 SQL。請注意,依賴關係遵循問題如何分解。某件事越詳細,越有可能改變。我們有一個高階想法,取決於可能會改變的事物。此外,這些步驟對較高層級的變更極為敏感,這是一個問題,因為需求往往會改變。我們希望相對於這種分解方式反轉依賴關係。
將其與自下而上的組成進行對比。您可以找到網域中存在的邏輯概念,並將它們組合起來以達成高階目標。例如,我們有許多使用電力的東西,我們稱它們為消費者。我們對它們了解不多,所以我們將透過消費者儲存庫 來了解它們。我們在網域中有一個稱為基準線的東西,需要有東西來決定它。消費者可以計算他們的能源使用量,然後我們可以比較基準線與所有消費者使用的能源,以確定節能
雖然我們最初所做的工作可能相同,但在這種重新構想中,只要多花一點功夫,就有機會引入不同的方式來完成細節
將儲存庫切換為不同的儲存機制,其介面中未提及 SQL,因此我們可以使用內存解決方案、NoSql 解決方案或 RESTful 服務。
不要建立基準,而是使用抽象工廠。 這將提供支援多種基準計算,這實際上反映了特定網域的現實情況。
在您閱讀本文時,您可能會注意到所有這些內容中都有一些開放封閉原則 的概念。它肯定相關。最初,將您的問題分解為網域建議的邏輯區塊。隨著系統的發展,請使用這些區塊或以某種方式擴充它們以容納其他場景。
這一切是什麼意思?
DIP 指的是抽象化,我注意到許多人將抽象化與下列項目混淆:
介面
抽象基底類別
作為約束條件提供的事物(例如,外部系統架構)
稱為需求的事物,陳述為解決方案
事實上,其中任何一項都可能具有誤導性
介面 — 看看 java.sql.Connection,將您的業務網域與 getAutoCommit()、createStatement() 和 getHoldability() 等方法進行比較。雖然這些方法對於資料庫連線來說可能是合理的,但它們與系統使用者想要執行的動作有何關聯?這種關聯充其量只是微弱的。
抽象基礎類別 — 抽象基礎類別與介面有相同的問題。如果方法對你的網域有意義,那可能沒問題。如果方法對軟體程式庫有意義,那可能就不行。例如,考慮 java.util.AbstractList。想像一個網域,其中包含歷史事件的持續增加的順序清單。在這個假設的網域中,從歷史記錄中remove() 項目永遠沒有意義。List 抽象,因為它解決的是一般問題,而不是你的問題,所以至少提供了這項對你的網域沒有意義的功能。你可以對 AbstractList(或其他 List 類別)進行子類別化,但這樣做仍然會公開一種方法(可能有多種),而這種方法對你使用該類別沒有意義。一旦你屈服並允許客戶端看到不必要的方法,你可能會同時違反 DIP 和 Liskov 替換原則。
約束/需求 — 當我們被賦予工作時,這項工作是否提供了動機和目標,還是談論如何解決問題?你的需求是否談論必須使用面向訊息的中介軟體進行整合,或更新哪些資料庫欄位才能完成工作?即使你獲得了 actor 目標的說明,這些目標是否只是重述目前的現況流程,而你可以在其中建構一個系統,從一開始就消除了對這些處理程序的需求?
你的意思是依賴性反轉,對嗎?
2004 年,Martin Fowler 發表了一篇關於依賴性注入 (DI) 和控制反轉 (IoC) 的文章 。DIP 與 DI 或 IoC 相同嗎?不,但它們可以很好地搭配使用。當 Robert Martin 首次討論 DIP 時,他將其等同於 開放封閉原則 和 Liskov 替換原則 的一級組合,足夠重要,可以保證它有自己的名稱。以下是使用一些範例對所有三個術語的概要
依賴性注入
依賴注入是關於一個物件如何得知另一個依賴物件。例如,在《大富翁》中,玩家會擲一對骰子。想像一個軟體玩家需要將 roll() 訊息傳送給一對軟體骰子。玩家物件如何取得骰子物件的參考?想像遊戲告訴玩家 takeATurn(:Dice) 並給予玩家骰子。遊戲告訴玩家輪到他並傳遞骰子,這是一個方法層級依賴注入的範例。想像一個系統,其中 Player 類別表達對 Dice 的需求,並且它會由某種所謂的 IoC 容器(例如 Spring)自動連線。我在 2013 年第一季所參與的系統就是一個最近的範例。它涉及 Spring 設定檔的使用。我們有 4 個命名設定檔:demo、test、qa、prod。預設設定檔是 demo,它會將系統設定為使用 10 個模擬裝置並啟用某些測試點。test 設定檔會將系統設定為不使用模擬裝置,並啟用測試點。qa 和 prod 都會將系統設定為透過行動網路連線到真實裝置,而且不會載入測試點,這表示如果生產元件嘗試使用測試點,系統將無法啟動。另一個範例來自一個涉及混合 Java 和 C++ 的應用程式。如果系統是透過 JVM 啟動,則會設定為模擬 C++ 層。如果它改為透過 C++ 啟動,然後再啟動 JVM,則系統會設定為使用 C++ 層。這些都是依賴注入的類型。
控制反轉
控制反轉是關於誰發起訊息。你的程式碼會呼叫架構,還是將某些東西插入架構,然後再由架構呼叫回來?這也稱為好萊塢法則 ;不要呼叫我,我會呼叫你。例如,當你為 Swing 建立一個 ButtonListener 時,你會提供一個介面的實作。當按鈕被按下時,Swing 會注意到並呼叫回你提供的程式碼。想像一個使用多個玩家建立的《大富翁》系統。遊戲會協調玩家之間的互動。當輪到某個玩家時,遊戲可能會詢問玩家是否有任何移動前的動作,例如賣出房屋或旅館,然後遊戲會根據骰子的點數移動玩家(在現實世界中,物理玩家會擲骰子並移動他的代幣,但這是桌上遊戲而非電腦遊戲的產物,也就是說,它是對正在發生的事情的現象描述,而非本體描述)。請注意,遊戲知道玩家何時可以做出決定並提示玩家,而不是由玩家做出決定。最後一個範例,Spring Message bean 或 JEE Message Bean 是註冊到容器的介面實作。當訊息到達佇列時,容器會呼叫 bean 來處理訊息,容器甚至會根據 bean 的回應移除訊息或不移除訊息。
依賴反轉原則
依賴反轉是關於程式碼所依賴物件的形狀。DIP 與 IoC 和 DI 有什麼關係?考慮一下,如果你使用 DI 來注入一個低抽象依賴,會發生什麼事?例如,我可以使用 DI 在大富翁遊戲中注入一個 JDBC 連線,這樣它就可以使用 SQL 陳述從 DB2 讀取大富翁棋盤。雖然這是 DI 的一個範例,但這是一個注入(可能)有問題的依賴的範例,因為它存在於遠低於我的問題領域的抽象層級。在大富翁的情況中,它是在 SQL 資料庫存在之前數十年所建立的,所以將它與 SQL 資料庫結合會引入一個不必要的、偶然的依賴。一個更好的注入到大富翁中的東西是棋盤儲存庫。這種儲存庫的介面適用於大富翁的領域,而不是以 SQL 連線的條款來描述。由於 IoC 是關於誰啟動呼叫順序,所以一個設計不良的回呼介面可能會將低階細節(架構)細節強制到您編寫的程式碼中,以插入架構。如果是這樣,請嘗試將大部分業務內容保留在回呼方法之外,而放在 POJO 中。
DI 是關於一個物件如何取得一個依賴。當一個依賴是由外部提供的,那麼系統正在使用 DI。IoC 是關於誰啟動呼叫。如果您的程式碼啟動一個呼叫,它不是 IoC,如果容器/系統/函式庫回呼到您提供給它的程式碼,它是 IoC。
另一方面,DIP 是關於從您的程式碼傳送到它呼叫的事物的訊息中抽象的層級。可以確定的是,將 DI 或 IoC 與 DIP 一起使用往往更具表現力、更強大且更符合領域,但它們是關於一個整體問題中不同的面向或力量。DI 是關於連線,IoC 是關於方向,而 DIP 是關於形狀。
接下來是什麼?
有了依賴反轉原則的定義,現在是時候繼續了解 DIP 在實際中的範例。以下是幾個範例,它們都有一個共同點;將依賴的抽象層級提高到更接近領域,並受到系統需求的限制。
彈性是有代價的
我做過且看過的一件常見事情是,透過新增比解決當前問題所需的更多方法來讓類別「更容易」使用。這可能源自「以防萬一」的想法,也許是源自於導致難以變更程式碼庫的實務歷史,這表示現在放入東西被認為比我們在需要時再新增來得容易。不幸的是,更多方法會導致更多撰寫不正確程式碼的方法、更多需要驗證的執行路徑、使用「更容易」介面時需要更多紀律等等。類別的表面積越大,正確使用該類別的可能性就越低。事實上,表面積越大,錯誤使用類別的可能性就越大,而不是正確使用它。
我該使用哪種槌子?
考慮記錄。雖然記錄不一定是執行 DevOps 的最佳方式,但它似乎是一種執行事情的常見做法。在我參與的最後幾個專案中,記錄最終成為一個問題。問題多種多樣
太多
太少
對於記錄某項內容的層級有分歧
對於要使用哪些記錄方法有分歧
對於要使用哪個記錄架構有分歧
不一致地使用 Logger 類別
在專案中使用的所有各種開源記錄程式庫中,記錄的組態不正確/不一致
不同的開源專案使用多個記錄架構
記錄訊息不一致,導致難以使用記錄
在此插入您的特定經驗...
雖然這不是一個全面的清單,但如果您曾經參與過中等規模的專案,卻沒有討論過其中一些主題,我會感到驚訝。
太多方法
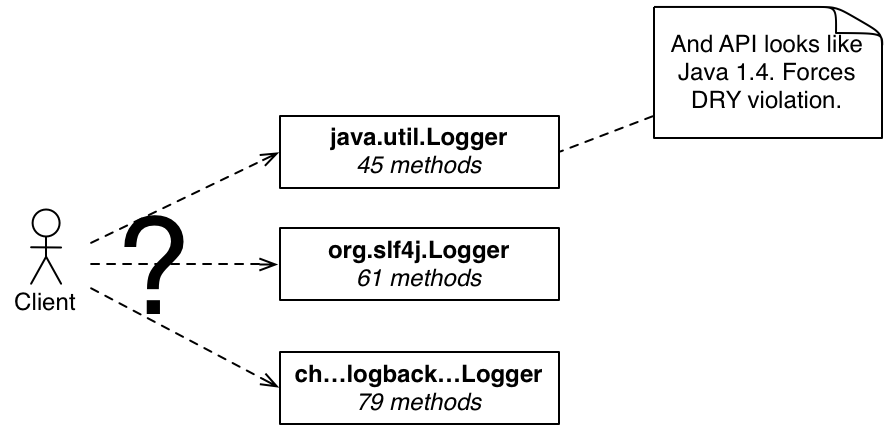
請參閱圖 2 。這包括 JDK 內建的 Logger 和其他兩個由多個開源專案使用的常見開源記錄架構。要關注的重點是每個類別中的方法數量。
讓我們只考慮 JDK 中的 Logger 類別。您是一位在團隊中工作的全新開發人員。希望您不是單獨工作,但如果您是,您可能會被告知「查看程式碼庫」,然後任由您自行發揮。當您需要進行一些記錄時,您會使用哪一個 log 方法?
首先,log 甚至是正確的方法嗎?您可以搜尋程式碼庫以尋找範例,您會採用找到的第一個範例,還是會檢查是否有多種方式?
這是一個微不足道的範例。它看起來微不足道。以下是我奉行的良好經驗法則
無 + 無 + 無 … 最終等於有。
-- Jerry Weinberg(改寫)
雖然這件事真的不是什麼大問題,但它不會是專案中唯一這樣的事。知道要使用哪種方法會稍微增加每個開發人員的負擔。它也增加了將人員新增到正在進行的專案或團隊中的難度。這種細節看似微不足道且不重要,最終會落入部落知識 的範疇。雖然擁有大量的部落知識 可能會對團隊身分有利,但導致不必要的差異性的事物可能不值得其代價。
效能考量
另一個論點是,隨著時間推移而變得較不重要,一開始可能不太明顯。考慮以下程式碼範例
Logger logger = Logger.getLogger(getClass().getName());
String message = String.format("%s-%s-%s", "part1", "part2", "part3");
logger.log(Level.INFO, message);
使用記錄器看似很直接,但它有一個問題:它會執行字串串接,而不論記錄器最終是否會在 INFO 層級記錄訊息。這會導致不必要的工作以及額外的垃圾回收。要「正確」撰寫這段程式碼,它應該更像這樣
Logger logger = Logger.getLogger(getClass().getName());
if (logger.isLoggable(Level.INFO)) {
String message = String.format("%s-%s-%s", "part1", "part2", "part3");
logger.log(Level.INFO, message);
}
負擔在於撰寫者必須記住這一點。想像一個具有多個記錄陳述式的系統進入點
這段程式碼將會被複製(或我們希望如此)
這種細節是附帶的,而不是必要的
這會增加檢視程式碼的心理負擔
喔,而且它違反了DRY 原則
如果您使用 Slf4j 等現代 API,其中一些問題已獲得解決,因為有方法可以採用不同數量的參數,並在串接之前執行檢查。這很好,但接著我們又回到有 50 多種方法可供選擇。我無法記起一個有超過 3 人的專案,其中沒有出現關於一致使用記錄器的討論,因此很明顯,方法數量已成為不必要的(附帶的)複雜性來源。
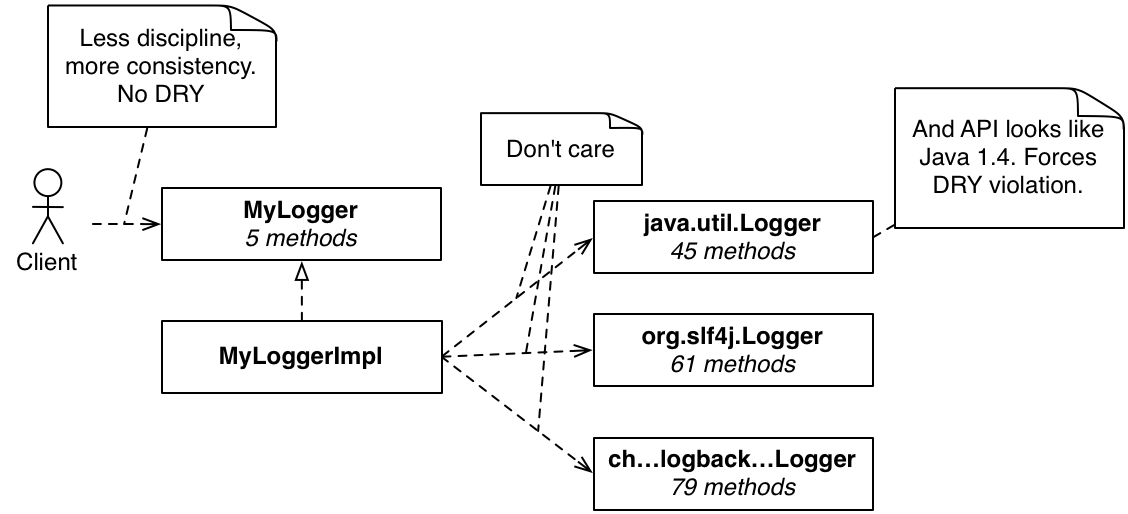
為了解決這個問題,我想要一些東西來減少重複和複雜性的需求。以下是我在許多專案中做過的一件事
使用這個新的記錄器現在不太可能造成問題
SystemLogger logger = SystemLoggerFactory.get(getClass());
logger.info("%s-%s-%s", "part1", "part2", "part3");
這個特定實作使用「現代」Java 1.5 功能
public void info(String message, Object... args) {
if (logger.isInfoEnabled()) {
logger.info(String.format(message, args));
}
}
Martin Fowler 稱這為 閘道 。我喜歡這個名稱,因為它喚起傳遞以及一件事與另一件事分開的概念。降低彈性會導致負擔稍微減輕,因此我們可以花時間思考下一個要撰寫的測試優先程式碼。
這個解決方案引進一個額外的呼叫方法,但呼叫方法的成本相較於消除錯誤執行的機會似乎非常值得。在現代執行階段,這個方法不會動態呼叫,它會最佳化為在沒有虛擬調用的情況下呼叫。我上次衡量方法呼叫(2008 年)時,每秒可以得到約 2,000,000,000 個,因此這個額外的負擔在我們可能會使用記錄器的系統中微不足道。額外的好處是,如果進行任何記錄組態,可以在一個地方管理,進而產生更 DRY 的程式碼。
結論
記錄程式庫的彈性很容易導致不一致的使用、更長的程式碼,或根據系統中記錄的狀態執行不必要工作的程式碼。從架構作者的角度來看,這很有道理。記錄在概念上可能存在於應用程式層級,但記錄架構的實作需要彈性足夠以支援多個 JVM 版本、各種用途,並成為所有人的一切。特定系統對記錄的使用可以選擇更專注且一致。記錄介面通常存在於比我的系統需要記錄器更低層級的抽象中。
解決方案抽象化,但那不是我的問題
使用 SQL 資料庫是您系統的必要部分嗎?實際需求是輸入您系統的資訊需要耐用嗎?多久?對哪些使用者?事實上,這些類型的問題過去比較容易,因為通常不會提出這些問題。
背景
上個世紀,我們擔心 ACID 交易。即使在那時,我們通常會以悲觀的 ACID 交易,與最後一個獲勝或物件版本控制等不太強大的東西進行交易,而後者是樂觀的。現在,隨著系統變得更大,我們已移至雲端和 NoSql 解決方案,並具有最終一致性,情況更加多樣化。
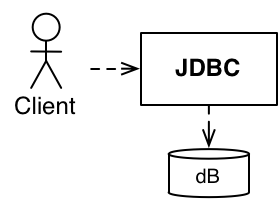
這與 Java 有何關係?我使用 JDK 1.0.2 處理並部署我的第一個應用程式。在那些日子裡,如果您想使用資料庫,它看起來像這樣
Java 棄權處理這個問題,而且您有供應商鎖定。或更糟的是,您撰寫程式碼來處理「任何」資料庫 - SQL 或物件導向。
Java 1.1 提供我們 JDBC。只要我們可以找到 JDBC 驅動程式,這就能改善我們對資料庫的使用
然而,儘管這使得使用資料庫更輕鬆,且供應商鎖定的情況較少,但這種抽象化會讓交易、準備好的陳述式等事項滲入您的網域。JDBC 提升了抽象化的層級,但層級仍然太低。
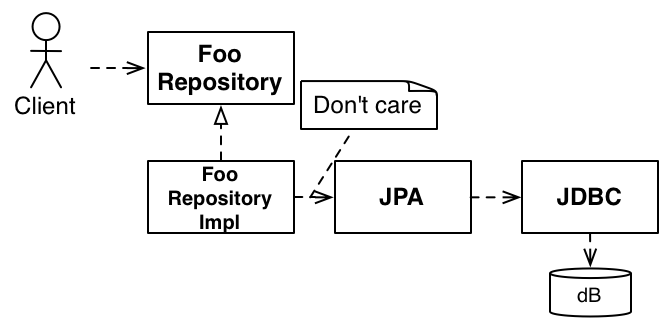
JDBC 有許多改進,然後是 JDO、ORM、Hibernate 和其他 ORM,以及最近的 JPA(我忽略了 Spring Data、Hades 等事項,因為它並未顯著改變情況)。值得注意的是,我們仍然有許多箭頭從系統指向資料庫。
如同記錄介面的討論,使用其中任何介面可能仍然違反 DIP。假設您並未撰寫資料庫,您的業務可能並不需要
將資料庫隱藏在與網域相關的某個東西後面
將一個 儲存庫
儲存庫是通往概念上(可能是實際上)大量的耐用物件集合的閘道。介面應包含對網域中使用者的目標有意義的方法,而不是對資料庫有意義的方法。如果剛好資料庫位於儲存庫的後方,則儲存庫將處理從對網域有意義的請求對映到對資料庫有意義的事項。讓抽象化的實作一次完成工作,而不是較低層級抽象化的所有使用者重複工作。
典型的介面可能包含基本的 CRUD 作業(假設網域呼叫它們),但隨後我們將新增對系統需求有意義的方法。也就是說,當我們透過新增新的使用案例、場景、使用者故事或待處理項目來擴充系統時,我們將延伸介面,使其支援系統的目前需求。不多也不少。
考慮一個處理火車時刻表的系統。在車站之間有許多預定的旅程。隨著時間推移,新的車站會被建造,其他車站會因維護而關閉,而車站之間的火車時刻表會因容量變化、配合季節性需求或推出促銷活動以吸引新業務而改變。火車時刻表會提前規劃好,然後新增到系統中以供未來啟用。系統需要定期找出不再相關的時刻表、即將啟用的時刻表,以及潛在的衝突,例如時刻表重疊或時刻表中的空白。
這是否表示對於給定的系統,我們只會針對給定的網域概念有一個儲存庫?也許。也許我們會根據考量,例如使用 受限的內容 ,建立多個儲存庫,或者我們可能會根據 介面隔離原則 來分割單一儲存庫介面。從 DIP 的觀點來看,重要的考量是介面存在於適當的抽象層級,以符合系統目前的需要。 什麼驅動了系統目前的需要?用例、使用者故事、場景、積壓項目。也就是說,您的參與者是誰,他們需要做什麼?
結論
當我們使用 JDBC 時,我們會使用一堆介面。介面是一種抽象。然而,雖然使用某種抽象通常有助於撰寫良好的程式碼,但這還不夠。抽象應該處於適合您網域的層級。像 JDBC 這樣的通用解決方案並不會試圖解決您的問題,它試圖解決一個通用的問題。這類似於記錄範例,其中有太多方法。JDBC 的功能解決了在使用資料庫時您可能需要處理的所有事情的完整範圍。典型的網域並不在乎所有這些問題,因此特定網域的消耗可以簡化以符合其需求。
不要接受既定的東西
到目前為止,範例一直都是關於用於解決系統某一部分的抽象層級。下一個範例沒有不同,但在實務上似乎被視為不同。當您獲得一個隱藏在需求中的解決方案時,會發生什麼事?
提供的解決方案
我們將從我所在團隊獲得的東西開始下一部分
以下是更詳細的說明
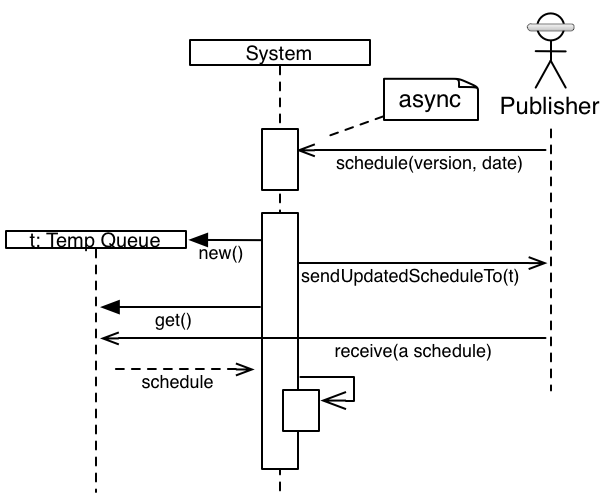
某些外部系統使用非同步發布/訂閱佇列廣播行程已更新的事實。
稍後,我們的系統需要接收該通知,並決定是否採取行動。例如,它可能已經有特定行程,因為行程可能會傳送多次。在此特定範例中,系統關注行程,因此會要求行程。
系統建立暫時佇列,系統將在此處要求發布者傳送完整行程。它會傳送非同步訊息給原始發布者(實際上會傳送至另一個佇列,並在同一個處理程序空間中處理)。
系統會在暫時佇列中等待行程傳送。它不會永遠封鎖,實際上會不時喚醒,以防系統決定在此整體程序進行中關閉。它也會在經過某些屬性驅動的分鐘數後放棄。
最終(順利進行),行程會抵達,而系統會收到行程。它會執行一些處理,然後系統會保留行程。
我們如何解決這個問題?
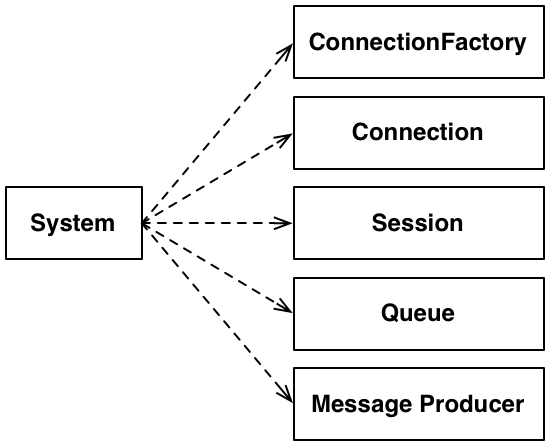
當時團隊正在處理這項工作時,我們有共用的配對工作站和開放的環境。我聽到處理問題的配對人員,並詢問他們是否直接依賴 JMX 或是否遵循 DIP(經過改寫,但為真實故事)。他們已經開始解決問題,將所有給定的條件視為必要條件,而這就是他們正在做的事
這是一個簡單、典型且熟悉的回應。有這麼多細節,很難看出實際上是什麼。在此問題中,非同步互動是必要的還是附帶的?在此特定案例中,整個機制是強加給我們的設計決策。雖然我們必須遵循它(這是一個合理的方法),但我們不必讓它的設計成為我們設計中不可磨滅的一部分。我建議在大多數情況下也是如此;一個稍微弱一點的準則是在未證明為其他情況之前,假設它是附帶的。
是否曾經有過非同步性之類的東西至關重要的案例?是的。想像一個工作流程,其中一個工作項目有一個或多個交接。也就是說,當我完成它時,你接手。我完成我的工作,然後完成。雖然我負責的最後一步已經完成,但給定項目的整體工作流程尚未完成。從概念上講,我為這種流程設計的介面看起來不會與一個人一次完成所有工作的介面相同。然而,設計背後的驅動力應受到領域的強烈影響。
在這種特定情況下,我們需要完成三件主要的事情:以原始形式取得行程、從 XML 轉換為行程,然後儲存它。第二和第三個步驟已經在一段時間前編寫好,所以當這項工作開始時,我們已經處理好取得。我們的系統從未需要原始原始表示,因此取得行程的結果比在系統中的其他地方看到 XML 表示更好。
快速設想一下,這變成了
請注意,對各種 JMS 介面的依賴性並未消失。它只是落後於另一層間接。我們的系統級別觀點是,我們有東西可以取得行程。它如何做到這一點完全留給具體的實作。事實上,我們最初在使用 Active MQ 的初始探索期間編寫了一個簡單的偽造 。稍後,我們還使用Mockito 為每個測試編寫存根 。
由此產生的高層次互動更容易理解
所有這些都變得重要,原因有以下幾個
取得 Tibco 權限需要一些時間,但我們很早就有了具體的範例
從原始格式轉換為行程確實需要一些額外的作業,我們可以在不等待的情況下完成
我們必須瞭解 Spring 3.x 的一些內部運作,在等待 Tibco 權限的同時,使用 ActiveMQ 這樣做可能使我們完成了 90%
我們無法控制 Tibco,它屬於另一個群組的責任(而且在政治上不會改變)——這是一個 DIP 將成為你朋友的巨大跡象。
我們正在實踐持續整合 ,這意味著我們經常執行測試,每天輕鬆超過 60 次:最多 5 對,多次簽入,多次開發人員執行,然後在每次簽入的建置方塊上,以及效能測試等。
測試佇列是共用的
測試佇列經常不可用,因為其他一些測試已填滿其緩衝區
測試佇列會有使用者可能會吞下所有訊息,這表示我們的測試可能會因為我們無法控制的事情而失敗
情況有多糟?
所有這些風險都使得能夠驗證我們的大部分邏輯與 Tibco 特定問題無直接關係變得至關重要。事實上,使用 JMS 的邏輯使 Tibco 和 ActiveMQ 之間的區別完全成為組態問題,而不是程式碼問題。當我們使用 ActiveMQ 時,我們指向一個正在處理的佇列。當我們使用 Tibco 時,我們會指向多個佇列中的其中一個,具體取決於我們是要使用 QA 佇列還是生產佇列。雖然存在一些差異(ActiveMQ 寬容一些),但我們設法編寫了一個處理這兩個函式庫的途徑。
如果這聽起來很吃重,那並非如此。實際的設計很直接。思考設計並非需要數天的努力,而是數分鐘。實作設計需要花費大量時間,但其中大部分是探索,因為我們許多人對 JMS 生疏(我對它總是生疏,我靠著 Google 活著)。
真正的勝利發生在幾個月後,我們在 QA 和生產複製品中讓它運作。在某個時間點,我們的系統在 QA 中停止運作,但它在所有其他環境中仍然運作,包括複製品生產環境。我們立即猜測佇列組態不同。我們詢問並得到保證,佇列組態相同。由於我們有測試,我們可以與某人合作,並在某人查看佇列時逐步執行我們的測試。我們盡職調查,最後表示雖然我們不確定這不是我們的問題,但我們盡可能確定,與使用一個 Tibco 執行個體或另一個執行個體相關的唯一可識別變數。大約一個半星期後,他們發現 QA 佇列組態不同。在所有這些進行時,我們的團隊並未停止處理這個整體問題的部分。
結論
通常會提供一個解決方案來實作,或解決方案受到現有外部環境考量限制。雖然你會撰寫程式碼來處理這些給定限制的具體事項,但這並不表示這些詳細資料應擴散到你的系統其他部分。將實作隱藏在一個地方,並提供從你的網域目標觀點撰寫的介面。將詳細資料掃到地毯下。
我昏迷了,現在是什麼時候?
你是否曾經處理過關心日期和時間的系統?你是如何取得目前日期的?你是如何處理時間流逝的?大多數系統都關心時間。在 Java 中,有許多方法可以取得目前日期和時間,但它們都傾向於使用它們執行的系統上的時間。
我這裡有你的行程
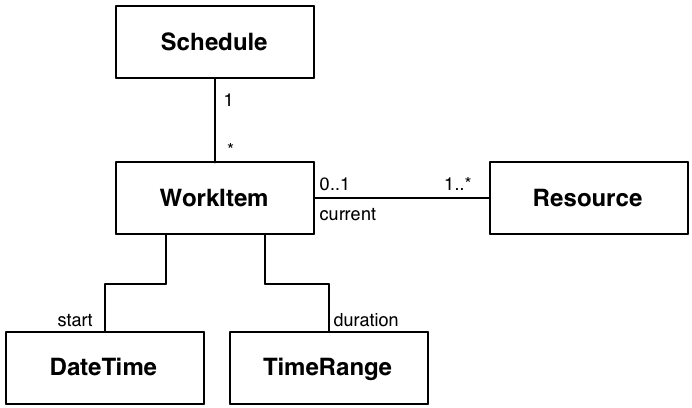
想像一個系統有許多工作項目,每個工作項目都使用一些資源。每個項目都排定要發生、正在發生或發生完畢。當兩個工作項目嘗試使用相同的資源時,將會發生衝突,你需要確保系統正確處理衝突。你將如何驗證你的系統能妥善管理衝突?
圖 14:工作項目需要獲得處理
網域細分
此說明中有一些關鍵概念:工作項目、衝突和時間
工作項目相對簡單,它們有名稱、說明、開始日期/時間、持續時間和一個或多個資源。
處理衝突聽起來像是一個有趣的議題,而且可能有多種處理衝突的方法。最初我們可能會採用先進先出,之後我們可能會採用類似先進先值等方法。無論如何,我們需要採用衝突解決的概念,並將其提升為系統中的首要事項。
到目前為止,一切都好。那麼時間呢?
時間是一個有趣的概念。我們大部分時間都將時間視為理所當然,如果我們有思考時間的話。如果我們什麼都不做,系統可能會有一個時間,時間會像牆上的時鐘一樣流逝。時間始終存在,其變化率似乎沒有太大的變化。然而,如果我們希望時間以不同於現實的速度移動怎麼辦?如果我們讓日期看起來與實際日期不同怎麼辦?跳過整段時間如何?關於時間的一個重點是它會在沒有使用者介入的情況下改變,但如果我們想要擁有時間怎麼辦?這甚至是什麼意思?
以不同的速度移動
你有一個時間敏感的系統,系統中的事件會在幾秒、幾分鐘、幾天內發生。你希望隨著時間推移觀察系統,但你不想在每小時頂端發生的事件之間等待一小時。
日期與目前日期不同
你正在使用真實的生產資料在測試環境中執行系統,而這些資料具有日期特定性。現在,這些日期在未來,但你希望看到如果日期是明天、前天一週,甚至是明年會發生什麼情況。你可以變更你的生產資料副本,或者你可以讓你的系統認為它是一個與實際日期不同的日期。
跳過整段時間
在你的系統中,事件會在離散的時間發生。你希望確保正確的事情在正確的時間發生。你可以確保這些事情根據你選擇執行系統的時間進行設定,或者你可以設定時間並觀察會發生什麼情況。
如何訓練你的時間領主
時間是否像其他商業概念?我們是否應該將時間視為一個值得一點尊重的頭等公民?那可能看起來是什麼樣子?那可能提供什麼?請參閱排程範例。
排程範例
功能: 處理排程衝突
作為操作員,我希望確保功能衝突由適當的政策管理。
背景
假設 並且 並且 並且 並且
情境: 沒有進行中的工作
情境: 一個進行中的項目
那麼
情境:
那麼 並且
情境:
那麼 並且
情境:
那麼
排程範例是為本文重新編寫的假設系統說明,它基於我處理過的許多實際系統。這些範例使用稱為 Gherkin 的語言撰寫,由稱為 Cucumber 的工具使用。使用這個特定的 特定領域語言 (DDD 和 BDD 社群稱為 普遍語言 ),我表達了一些排程系統應該如何運作的期望/事實/範例。
這系列範例嘗試說明在給定明確的起點和許多後續活動的情況下,系統中應該發生什麼事。例如,根據「沒有進行中的工作」範例,在 9:59 時,不應該有任何進行中的工作。稍後,在 10:01 時,其中一個工作項目應該開始進行。第一個衝突發生在 10:10,當時工作項目 Megatron_Torso 仍在執行,而 Megatron_Head 必須等待共用資源 3d_printer_1 的可用性。
這種系統驗證很常見,但這種方法並不常見。在這個領域中,時間很重要。對這個系統來說,大多數時間並不重要,只有基於工作排程的特定時間才重要。
哪些時間點很重要?範例中明確說明,有一個工作項目在 10:00 開始,持續 15 分鐘,另一個在 10:10 開始,持續 5 分鐘。若要驗證我的測試,可以使用類似 邊界測試 的方法,選擇重要時間點周圍的時間。
我見過更常見的做法是,選擇時間點更接近,然後等待事情發生。例如,我會使用 15 秒,而不是 15 分鐘。這種測試設定雖然常見,但指出系統並未掌握一個關鍵的領域概念:時間。
一個這樣做的範例
如果您選擇使用 Joda 時間,執行這種操作非常簡單。以下是一個簡單的 Java 類別,用於變更 Joda 時間產生的時間
@Component
public class BusinessDateTimeAdjuster {
public void resetToSystemTime() {
DateTimeUtils.setCurrentMillisSystem();
}
public void setTimeTo(int hour, int minute) {
DateTimeUtils.setCurrentMillisFixed(todayAt(hour, minute).getMillis());
}
DateTime todayAt(int hour, int minute) {
MutableDateTime dateTime = new MutableDateTime();
dateTime.setTime(hour, minute, 0, 0);
DateTime result = dateTime.toDateTime();
return result;
}
}
現在,類似以下的表達式:而營業時間為 9:59,我使用 Cucumber-jvm 執行此範例,執行下列方法
public class ScheduleSteps {
@Given("^the business time is " + TIME + "$")
public void the_business_time_is(int hour, int minute) {
setTimeTo(hour, minute);
}
private void setTimeTo(int hour, int minute) {
BusinessDateTimeFactory.setTimeTo(hour, minute);
scheduleSystemExample.recalculate();
}
}
public class BusinessDateTimeFactory {
public static DateTime now() {
return new DateTime();
}
public static void restoreSystemTime() {
DateTimeUtils.setCurrentMillisSystem();
}
public static DateTime todayAt(int hour, int minute) {
MutableDateTime dateTime = now().toMutableDateTime();
dateTime.setTime(hour, minute, 0, 0);
return dateTime.toDateTime();
}
public static void setTimeTo(int hour, int minute) {
DateTimeUtils.setCurrentMillisFixed(todayAt(hour, minute).getMillis());
}
}
此程式碼將時間設定為固定點。Cucumber-jvm 函式庫允許在測試前後執行掛鉤。在此情況下,測試後掛鉤將時間重設回系統時間。
實際上,引入營業時間等領域概念的想法聽起來可能需要大量工作,但實際上並非如此。我在專案後期執行過這種操作,即使在成熟的專案中,引入這種想法所花費的時間,也遠低於我在測試系統方面節省的時間。就資料點而言,引入一個簡單的日期工廠可能需要幾個小時(我會測試它,因為日期往往很囉嗦)。找出所有出現類似 new Date() 或其等效程式碼的地方,需要使用正規表示式和遞迴搜尋。我上次執行此操作時,程式碼中的 410 個地方可能需要 2 小時才能修復。因此,在成熟的系統上,需要半天。如果您使用 Joda 時間,甚至不需要修復呼叫 new DateTime() 的程式碼中的地方。雖然 Joda 時間讓這件事變得很簡單,但我也在 Java 中使用 Calendar 執行過此操作。這個想法聽起來很大,但實際上比實際執行和實作的工作範圍更廣泛。
結論
我們將許多事情視為固定不變。更糟糕的是,我們甚至沒有注意到關鍵概念,因為我們已經習慣於不思考它們。我不記得在哪裡遇到過這個想法。我認為這是多年前一個專案的觀察結果。我們在本地資料庫中使用生產資料的副本。生產資料具有日期規則。每隔一段時間,日期就不再是未來,而且我們也經常取得生產資料的新版本,日期不同(不同的問題)。我們在時間過後不斷「修復」日期,最後我終於發現,這種手動、重複且容易出錯的活動完全是浪費時間。我們正在變更日期,所以很明顯地,我們需要控制日期。我第一次嘗試時,花費的時間比半天稍長。從那以後,我在 5 個不同的生產中專案中執行過至少 5 次,現在這是我的早期工作,所以花費的時間很少。我和幾位 QA 人員發現這種功能很方便,而且可以節省大量時間。
然而,此範例說明我們的程式碼不需要依賴於時間這種看似真實的東西。更一般的想法是:如果某件事造成問題,請控制它。在此情況下,控制恰好受到函式庫的輕易支援,但如果您查看最後的程式碼範例,我仍然會引入 BusinessDateTimeFactory,以有一個單一的地方來擷取日期和時間的想法,然後依賴它。
結束
我們在實務中看過一些 DIP 的範例
將一個方法過多的笨重 API 馴服
移除程式庫抽象層級與網域之間的不匹配
拒絕外部限制,而該限制規定了特定溝通風格
控制時間本身
有些更明顯地應用 DIP,而其他一些看起來更像是符合其他設計原則。最後,哪個原則更適用於某個情況並不重要。Daniel Terhorst-North 在宣稱 所有軟體都是負債 時,很好地捕捉到了這個想法。作為一名開發人員,我的目標似乎是撰寫程式碼。然而,這就像問一位矯正醫師你是否需要矯正器。答案是肯定的,謝謝,我需要為我的船再付一筆頭期款。
我喜歡撰寫程式碼、學習新的程式語言,以及所有這些。然而,如果我正在努力解決問題,我必須記住軟體通常是達成目的的手段,而不是目的本身。這適用於設計原則以及敏捷實務。有意義的是記住工作的重點,然後讓背景決定有意義的事物。如果您正在尋找一種方法來建構特定問題的解決方案,那麼了解 DIP 會很方便。
更普遍地說,有助於我更快解決特定業務問題的原則和實務對該背景是有益的。它們可能不適用於其他背景。我傾向於處理長壽的系統,這些系統通常涉及依賴多個報告結構所完成的工作。這表示找出有問題的依賴關係,並使用 DIP 等設計原則將其控制住,往往是我不斷重複的主題。這些想法中的任何一個都可能對您的特定問題造成可怕的後果。
如果您碰巧正在處理某個 軟體半衰期 較短的事物,那麼對您的背景來說,最好的事情可能是直接依賴那些依賴關係。此外,如果您按照 Robert Martin 的定義實踐 TDD (僅撰寫自動化測試與 TDD 幾乎無關),那麼您可能能夠根據需要進行全面變更。在這種情況下,DIP 會通知重構,而不是事前設計。
找出依賴關係,然後確定是否值得明確處理它們,以及在何處處理它們的實務,是一項值得練習的技能。您可以將這些特定範例視為嘗試的事物、在您執行工作時要尋找的事物種類的指南,甚至是您可以採取的具體措施來控制您的依賴關係。這些範例,或 DIP 本身,是否有幫助或造成傷害,將取決於您嘗試解決的問題。







{kind=link}