當我們和 Thoughtworks 的同事開始進行敏捷專案時,我們意識到需要解決如何演化資料庫以支援這種架構演化的問題。我們大約在 2000 年開始一個專案,其資料庫最終包含約 600 個表格。在進行這個專案時,我們開發了允許輕鬆變更架構和移轉現有資料的技術。這使我們的資料庫能夠完全靈活且可演化。我們在本文的早期版本中描述了這些技術,這些描述激勵了其他團隊和工具組。從那時起,我們在全球數百個專案中使用並進一步開發了這些技術,從小型團隊到大型跨國工作計畫。我們一直打算更新本文,現在我們有機會適當地更新它。
Jen 實作一個新的故事
為了了解所有這些運作方式,讓我們概述開發人員 (Jen) 編寫一些程式碼來實作新的使用者故事時會發生什麼事。故事指出使用者應該能夠查看、搜尋和更新庫存中產品的位置、批次和序號。查看資料庫架構後,Jen 看到目前庫存表格中沒有這些欄位,只有一個單一的 inventory_code 欄位,它是這三個欄位的串接。她必須將這個單一程式碼拆分為三個獨立的欄位:location_code、batch_number 和 serial_number。
以下是她的執行步驟
- 在現有架構中新增欄位至
inventory 表格
- 撰寫資料移轉指令碼,以將資料從現有的
inventory_code 欄位拆分,並更新 location_code、batch_number 和 serial_number 欄位。
- 變更應用程式程式碼以使用新的欄位
- 變更任何資料庫程式碼,例如檢視、儲存程序和觸發器,以使用新欄位
- 變更任何基於
inventory_code 欄位的索引
- 提交此資料庫遷移指令碼和所有應用程式程式碼變更至版本控制系統
若要新增新欄位和遷移資料,Jen 會撰寫一個 SQL 遷移指令碼,她可以在目前的架構上執行。這將同時變更架構,並遷移清單中所有現有資料。
ALTER TABLE inventory ADD location_code VARCHAR2(6) NULL;
ALTER TABLE inventory ADD batch_number VARCHAR2(6) NULL;
ALTER TABLE inventory ADD serial_number VARCHAR2(10) NULL;
UPDATE inventory SET location_code = SUBSTR(product_inventory_code,1,6);
UPDATE inventory SET batch_number = SUBSTR(product_inventory_code,7,6);
UPDATE inventory SET serial_number = SUBSTR(product_inventory_code,11,10);
DROP INDEX uidx_inventory_code;
CREATE UNIQUE INDEX uidx_inventory_identifier
ON inventory (location_code,batch_number,serial_number);
ALTER TABLE product_inventory DROP COLUMN inventory_code;
Jen 在其機器上的資料庫本機副本上執行此遷移指令碼。然後,她繼續更新應用程式程式碼以使用這些新欄位。在執行此操作時,她會針對此程式碼執行現有的測試套件,以偵測應用程式行為中的任何變更。某些測試(依賴於合併欄位的測試)需要更新。可能需要新增一些測試。一旦 Jen 完成所有這些工作,且應用程式在她的機器上所有測試都為綠色,Jen 會將她所有的變更推送到共用專案版本控制儲存庫(我們稱之為主線)。這些變更包括遷移指令碼和應用程式程式碼變更。
如果 Jen 不太熟悉進行此變更,她很幸運,因為這是一個常見的資料庫變更。因此,她可以在 資料庫重構手冊 中查詢,還有一個 線上摘要。
一旦變更在主線中,它們將會被 持續整合 伺服器擷取。它將在資料庫的主線副本上執行遷移指令碼,然後執行所有應用程式測試。如果全部為綠色,此程序將在整個 部署管線 中重複,包括 QA 和暫存環境。相同的程式碼最後會針對製作執行,現在更新實際資料庫的架構和資料。
像這樣的小型使用者故事只有一個資料庫遷移,較大的故事通常會細分為針對資料庫的每個變更的幾個獨立遷移。我們通常的規則是讓每個資料庫變更盡可能小。它越小,就越容易正確,並且任何錯誤都可以快速發現和除錯。像這樣的遷移很容易組成,所以最好做許多小的遷移。
應對變更
敏捷方法在 2000 年代初期廣受歡迎,它們最明顯的特徵之一是它們對變化的態度。在它們出現之前,關於軟體流程的大部分想法都是關於早期了解需求、簽署這些需求、使用需求作為設計的基礎、簽署它,然後進行建構。這是一個計畫驅動的循環,通常被稱為(通常帶有嘲諷意味)瀑布式方法
這種方法透過大量的前期工作來尋求將變更降到最低。一旦早期工作完成,變更就會造成重大問題。因此,如果需求發生變化,這種方法就會遇到麻煩,而需求變更對這種流程來說是一個大問題。
敏捷流程以不同的方式應對變更。它們尋求擁抱變更,允許變更甚至在開發專案的後期發生。變更受到控制,但流程的態度是盡可能地促成變更。部分原因是為了應對許多專案中需求的不穩定性,部分原因是為了透過幫助它們隨著競爭壓力而改變來更好地支援動態的商業環境。
為了讓這項工作順利進行,你需要對設計採取不同的態度。不要將設計視為一個階段,這個階段在你開始建構之前大多已完成,而是將設計視為一個持續的流程,與建構、測試甚至交付交織在一起。這是計畫設計和演化設計之間的對比。
敏捷方法的重要貢獻之一是它們提出了讓演化設計以受控方式運作的做法。因此,這些方法並非常見的混亂,這種混亂通常發生在設計未事先計畫時,而是提供了控制演化設計並使其實用的技術。
這種方法的重要部分是反覆開發,在專案生命週期中多次執行整個軟體生命週期。敏捷流程在每個反覆中執行完整的生命週期,並使用可運作、經過測試、整合的程式碼完成反覆,以滿足最終產品需求的一小部分。這些反覆很短,從幾個小時到幾個星期不等,技術較熟練的團隊使用較短的反覆。
儘管這些技術的使用和興趣日益增加,但最大的問題之一是如何讓演化設計適用於資料庫。長期以來,資料庫社群的人們認為資料庫設計是絕對需要前期計畫的事情。在開發後期變更資料庫架構往往會導致應用程式軟體出現廣泛的故障。此外,在部署後變更架構會導致痛苦的資料遷移問題。
在過去十幾年的過程中,我們參與了許多使用演化資料庫設計並使其運作的大型專案。有些專案涉及全球多個地點的 100 多人。其他專案涉及超過 50 萬行的程式碼、超過 500 個表格。有些在生產環境中有多個版本的應用程式,並且需要 24*7 全天候運作的應用程式。在這些專案中,我們看到了為期一個月和一周的反覆,較短的反覆運作得更好。以下我們描述的技術就是我們用來完成這項工作的技術。
自早期開始,我們便嘗試將這些技術擴展到更多專案,從更多案例中獲得更多經驗,而現在所有專案都使用這種方法。我們也從其他敏捷實務人員那裡獲得靈感、想法和經驗。
限制
在我們深入探討這些技術之前,重要的是要說明我們尚未解決演化式資料庫設計的所有問題。
我們有數百家零售商店的專案,每個商店都有自己的資料庫,所有資料庫都需要一起升級。然而,我們尚未探索在如此龐大的網站群組中進行大量自訂的情況。一個範例可能是允許自訂架構的小型企業應用程式,部署到數千家不同的小型公司。
我們越來越看到人們將多個架構用作單一資料庫環境的一部分。我們曾與使用少數幾個此類架構的專案合作,但尚未將其擴展到數十或數百個架構。這是我們預計在未來幾年內必須處理的情況。
我們不認為這些問題本質上是無法解決的。畢竟,當我們撰寫這篇文章的原始版本時,我們尚未解決 24*7 全天候運作時間或整合資料庫的問題。我們找到了處理這些問題的方法,並預期我們也會進一步推動演化式資料庫設計的極限。但在我們做到之前,我們不會聲稱我們可以解決此類問題。
實務
我們對演化式資料庫設計的方法取決於幾個重要的實務。
DBA 與開發人員密切合作
敏捷方法的原則之一是,具有不同技能和背景的人員需要非常緊密地合作。他們無法主要透過正式會議和文件進行溝通。相反地,他們需要隨時彼此交談並彼此合作。每個人都會受到此影響:分析師、專案經理、領域專家、開發人員...和資料庫管理員。
開發人員處理的每項任務都可能需要資料庫管理員的協助。開發人員和資料庫管理員都需要考量開發任務是否會對資料庫結構造成重大變更。如果是,開發人員需要諮詢資料庫管理員,以決定如何進行變更。開發人員知道需要哪些新功能,而資料庫管理員則對應用程式和其他周圍應用程式中的資料有全面的了解。許多時候,開發人員只會看到他們正在處理的應用程式,而不會看到架構中所有其他上游或下游的相依性。即使是單一資料庫應用程式,資料庫中也可能存在開發人員不知道的相依性。
開發人員隨時可以找資料庫管理員,並要求配對以解決資料庫變更。透過配對,開發人員可以了解資料庫如何運作,而資料庫管理員則可以了解對資料庫的需求背景。對於大多數變更,如果開發人員擔心變更對資料庫的影響,他們必須找資料庫管理員。但是,資料庫管理員也會主動出擊。當他們看到他們認為可能會對資料產生重大影響的故事時,他們可以找相關的開發人員討論資料庫影響。資料庫管理員也可以在遷移提交到版本控制時進行檢閱。雖然還原遷移很麻煩,但我們再次從每次遷移都很小的做法中獲益,這使得還原變得更容易。
為了實現這一點,資料庫管理員必須讓自己容易親近且隨時可得。她需要讓開發人員可以輕鬆地過來幾分鐘並提出一些問題,也許在 Slack 頻道、HipChat 房間或開發人員使用的任何通訊媒體上。在設定專案空間時,請確保資料庫管理員和開發人員坐得靠近,以便他們可以輕鬆地聚在一起。確保資料庫管理員知道任何應用程式設計會議,以便他們可以輕鬆地參與。在許多環境中,我們看到人們在資料庫管理員和應用程式開發功能之間豎立障礙。這些障礙必須消除,才能讓演化的資料庫設計流程運作。
所有資料庫人工製品都與應用程式碼一起進行版本控制
開發人員從對所有成品使用版本控制中受益良多:應用程式程式碼、單元和功能測試,以及其他程式碼,例如用於建立環境的建置指令碼,以及用於建立環境的 Puppet 或 Chef 指令碼。
類似地,所有資料庫成品都應在版本控制中,在所有人都使用的相同儲存庫中。其好處如下
- 只有一個地方可以查看,讓專案中的任何人都可以更輕鬆地找到東西。
- 儲存每個資料庫變更,如果發生任何問題,可以輕鬆稽核。我們可以追蹤資料庫的每次部署,以了解架構和支援資料的確切狀態。
- 我們可以防止資料庫與應用程式不同步的部署,這會導致擷取和更新資料時發生錯誤。
- 我們可以輕鬆建立新的環境:用於開發、測試,當然還有生產。建立軟體執行版本的所需一切應位於單一儲存庫中,以便可以快速簽出並建置。
所有資料庫變更都是遷移
在許多組織中,我們看到一個流程,開發人員使用架構編輯工具和臨時 SQL 來對開發資料庫進行變更,以建立常駐資料。完成開發任務後,DBA 會將開發資料庫與生產資料庫進行比較,並在將軟體推廣到實際環境時對生產資料庫進行相應變更。但在生產時執行此操作很棘手,因為開發中變更的背景已遺失。不同的人員小組需要再次了解變更的目的。
為了避免這種情況,我們更喜歡在開發期間擷取變更,並將變更保留為一級成品,可以使用與應用程式程式碼變更相同的流程和控制對其進行測試和部署到生產環境。我們透過將資料庫的每個變更表示為資料庫遷移指令碼來執行此操作,該指令碼與應用程式程式碼變更一起進行版本控制。這些遷移指令碼包括:架構變更、資料庫程式碼變更、參考資料更新、交易資料更新,以及由錯誤造成的生產資料問題的修正。
以下變更會將 min_insurance_value 和 max_insurance_value 新增到 equipment_type 表格,並附帶一些預設值。
ALTER TABLE equipment_type ADD(
min_insurance_value NUMBER(10,2),
max_insurance_value NUMBER(10,2)
);
UPDATE equipment_type SET
min_insurance_value = 3000,
max_insurance_value = 10000000;
此變更會將一些常駐資料新增到 location 和 equipment_type 表格。
-- Create new warehouse locations #Request 497
INSERT INTO location (location_code, name , location_address_id,
created_by, created_dt)
VALUES ('PA-PIT-01', 'Pittsburgh Warehouse', 4567,
'APP_ADMIN' , SYSDATE);
INSERT INTO location (location_code, name , location_address_id,
created_by, created_dt)
VALUES ('LA-MSY-01', 'New Orleans Warehouse', 7134,
'APP_ADMIN' , SYSDATE);
-- Create new equipment_type #Request 562
INSERT INTO equipment_type (equipment_type_id, name,
min_insurance_value, max_insurance_value, created_by, created_dt)
VALUES (seq_equipment_type.nextval, 'Lift Truck',
40000, 4000000, 'APP_ADMIN', SYSDATE);
透過這種工作方式,我們絕不會使用架構編輯工具(例如 Navicat、DBArtisan 或 SQL Developer)來變更架構,我們也絕不會執行臨時 DDL 或 DML 來新增常駐資料或修正問題。除了應用程式軟體造成的資料庫更新外,所有變更都是由遷移進行的。
將遷移定義為 SQL 命令集是其中一部分,但為了適當地套用它們,我們需要一些額外的東西來管理它們。
- 每個遷移都需要一個唯一的識別。
- 我們需要追蹤已套用至資料庫的遷移
- 我們需要管理遷移之間的順序約束。在上面的範例中,我們必須先套用
ALTER TABLE 遷移,否則第二個遷移將無法插入設備類型。
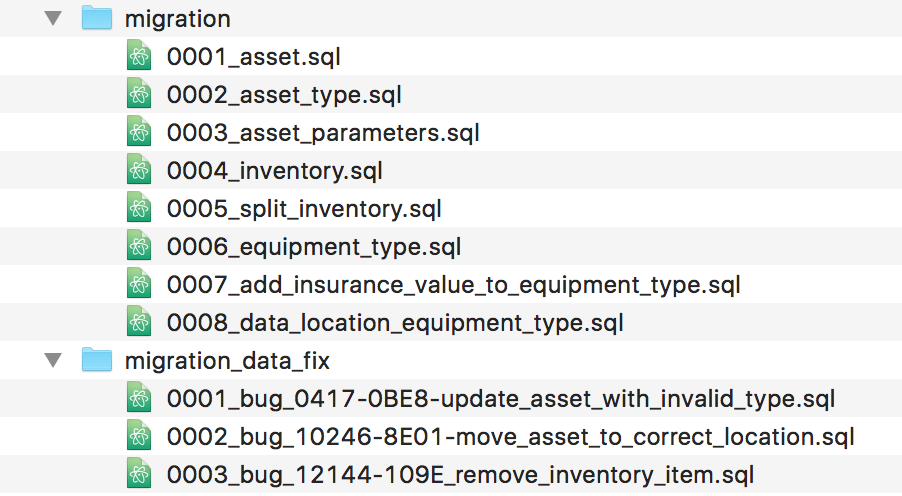
我們透過給予每個遷移一個順序編號來處理這些需求。這作為一個唯一的識別,並確保我們可以維護它們套用至資料庫的順序。當開發人員建立一個遷移時,她會將 SQL 放入專案版本控制儲存庫中遷移資料夾內的文字檔中。她會在遷移資料夾中尋找目前使用的最高編號,並使用該編號和說明來命名檔案。因此,較早的一對遷移可能會稱為 0007_add_insurance_value_to_equipment_type.sql 和 0008_data_location_equipment_type。
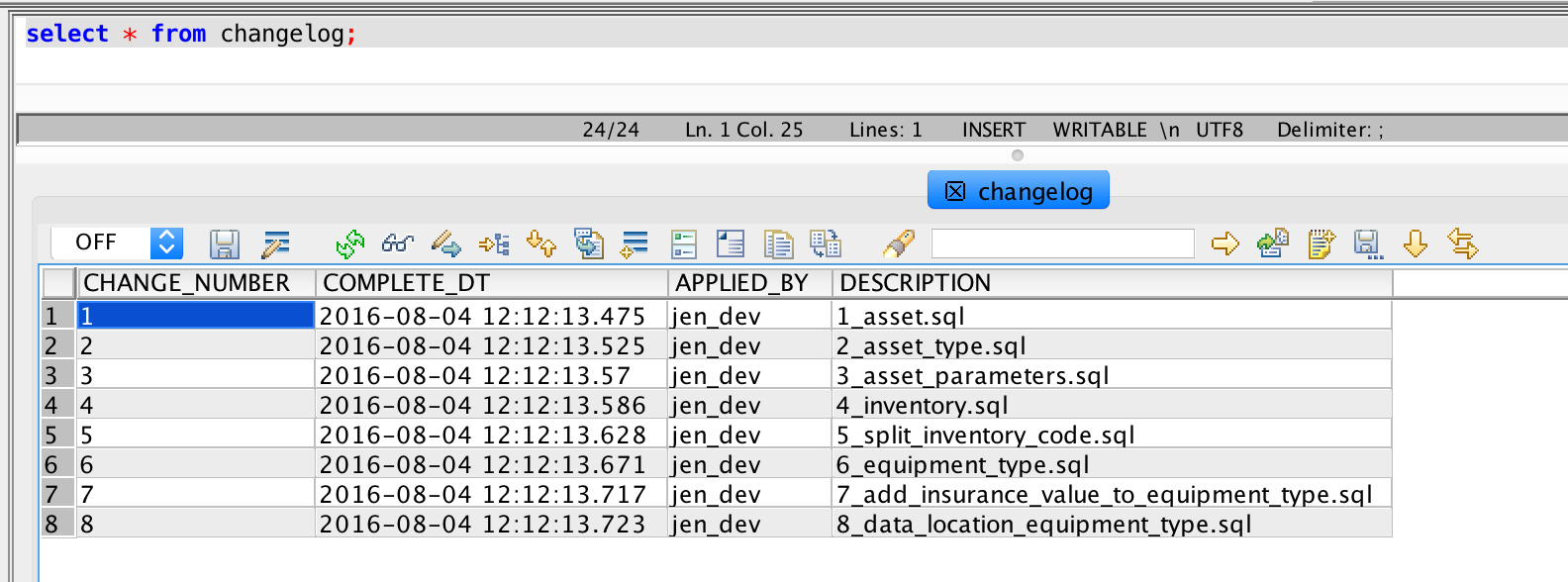
為了追蹤遷移套用至資料庫的狀況,我們使用一個變更記錄表。資料庫遷移架構通常會建立這個表格,並在每次套用遷移時自動更新它。這樣資料庫可以隨時回報它與哪個遷移同步。如果我們不使用這種架構,畢竟當我們開始執行這項工作時它們並不存在,我們會使用指令碼自動執行這項工作。
透過這個編號配置,我們可以追蹤變更,因為它們套用至我們管理的許多資料庫。
其中一些資料遷移可能必須比與新功能相關的遷移更頻繁地發布,在這種情況下,我們發現擁有獨立的遷移儲存庫或資料夾來處理與資料相關的錯誤修正很有用。
這些資料夾中的每個資料夾都可以由資料庫遷移工具(例如 Flyway、dbdeploy、MyBatis 或類似的工具)分別追蹤,並使用一個獨立的表格來儲存遷移編號。在 Flyway 中的屬性 flyway.table 用於變更儲存遷移元資料的表格名稱
每個人都取得自己的資料庫執行個體
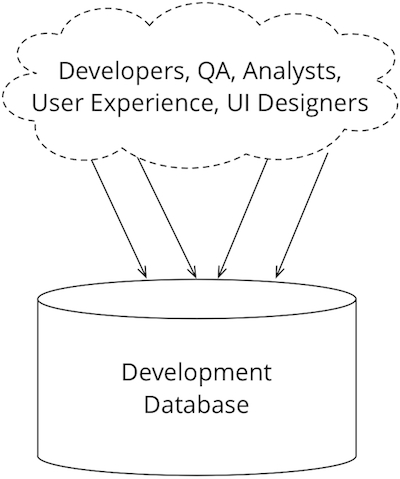
大多數開發組織共用單一開發資料庫,由組織中的所有成員使用。也許會為 QA 或分段使用個別資料庫,但概念是限制執行中的資料庫數量。像這樣共用資料庫是資料庫執行個體難以設定和管理的結果,導致組織將數量減至最低。在這種情況下,誰可以變更架構的控制措施有所不同,有些地方要求所有變更都必須透過 DBA 團隊進行,其他地方則允許任何開發人員變更開發資料庫的架構,而 DBA 會在變更推廣至下游時介入。
當我們開始使用敏捷資料庫專案時,我們注意到應用程式開發人員通常遵循模式,在程式碼的私人工作副本中工作。人們透過嘗試來學習,因此在程式設計術語中,開發人員會試驗如何實作特定功能,並可能在選定一個之前進行多次嘗試。能夠在私人工作區中進行試驗,並在情況更穩定時推送到共用區域非常重要。如果每個人都在共用區域中工作,那麼他們會不斷以半完成的變更互相干擾。儘管我們偏好持續整合,其中整合發生在不超過數小時後,但私人工作副本仍然很重要。版本控制系統支援這項工作,允許開發人員獨立工作,同時支援將其工作整合到主線副本中。
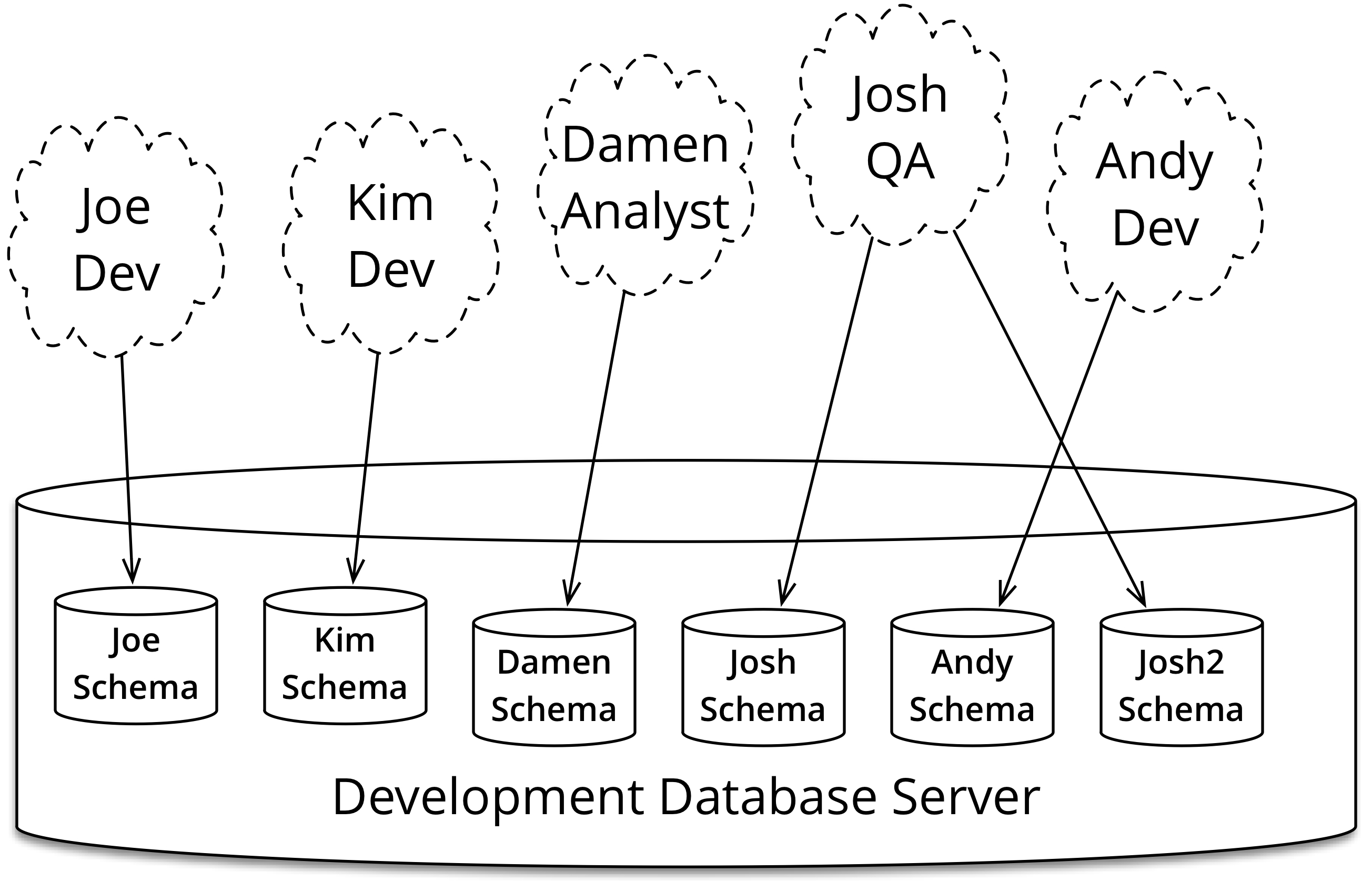
這個個別工作適用於檔案,但也可以適用於資料庫。每個開發人員都會取得自己的資料庫執行個體,他們可以自由修改,而不會影響其他人的工作。當他們準備好時,他們可以推送並共用其變更,我們將在下一節中看到。
這些個別資料庫可以是共用伺服器上的個別架構,或更常見的是,在開發人員的筆電或工作站上執行的個別資料庫。十年前,資料庫授權成本可能使個別資料庫執行個體的費用過於昂貴,但現在很少會這樣,特別是因為開源資料庫越來越受歡迎。我們發現,在開發人員機器上執行的虛擬機器中執行資料庫很方便。我們使用 Vagrant 和 Infrastructure As Code 定義資料庫 VM 的建置,因此開發人員不需要知道設定資料庫 VM 的詳細資訊,或手動執行此操作。
許多資料庫管理員仍將多個資料庫視為禁忌,認為在實務上很難操作,但我們發現,你可以輕鬆管理一百多個應用程式資料庫實例。要點是,要有工具讓你能夠像操作檔案一樣操作資料庫。
<target name="create_schema"
description="create a schema as defined in the user properties">
<echo message="Admin UserName: ${admin.username}"/>
<echo message="Creating Schema: ${db.username}"/>
<sql password="${admin.password}" userid="${admin.username}"
url="${db.url}" driver="${db.driver}" classpath="${jdbc.classpath}"
>
CREATE USER ${db.username} IDENTIFIED BY ${db.password} DEFAULT TABLESPACE ${db.tablespace};
GRANT CONNECT,RESOURCE, UNLIMITED TABLESPACE TO ${db.username};
GRANT CREATE VIEW TO ${db.username};
ALTER USER ${db.username} DEFAULT ROLE ALL;
</sql>
</target>
開發人員架構的建立可以自動化,使用建置指令碼來減少資料庫管理員的工作負擔。這種自動化也可以僅限於開發環境。
<target name="drop_schema">
<echo message="Admin UserName: ${admin.username}"/>
<echo message="Working UserName: ${db.username}"/>
<sql password="${admin.password}" userid="${admin.username}"
url="${db.url}" driver="${db.driver}" classpath="${jdbc.classpath}"
>
DROP USER ${db.username} CASCADE;
</sql>
</target>
例如,開發人員加入專案,檢出程式碼庫,並開始設定其本機開發環境。她使用範本 build.properties 檔案並進行變更,例如將 db.username 設定為 Jen,並為其餘設定進行設定。完成這些設定後,她只要執行 ant create_schema,即可在團隊開發資料庫伺服器或其筆電上的資料庫伺服器取得自己的架構。
在建立架構後,她接著可以執行資料庫遷移指令碼,以建立所有資料庫內容來填入其資料庫實例:表格、索引、檢視、序列、儲存程序、觸發器、同義詞和其他特定資料庫物件。
類似地,也有用於刪除架構的指令碼,原因可能是因為不再需要,或僅是因為開發人員希望清理並重新開始使用新的架構。資料庫環境應該是 鳳凰,可以定期燒毀並隨意重建。這樣一來,環境累積無法複製或稽核特性的風險較低。
開發人員需要私人工作空間,而團隊中的其他人也需要。品質保證人員應該建立自己的資料庫,這樣他們也可以工作,而不會因為他們不知道的變更而混淆。資料庫管理員應該能夠在探索建模選項或效能調整時,使用自己的資料庫副本進行實驗。
開發人員持續整合資料庫變更
雖然開發人員可以在自己的沙盒中頻繁地進行實驗,但使用持續整合 (CI)將不同的變更頻繁地整合在一起至關重要。CI 涉及設定一個整合伺服器,自動建置和測試主線軟體。我們的經驗法則是一天至少整合一次到主線。有許多工具可以協助 CI,包括:GoCD、Snap CI、Jenkins、Bamboo 和Travis CI
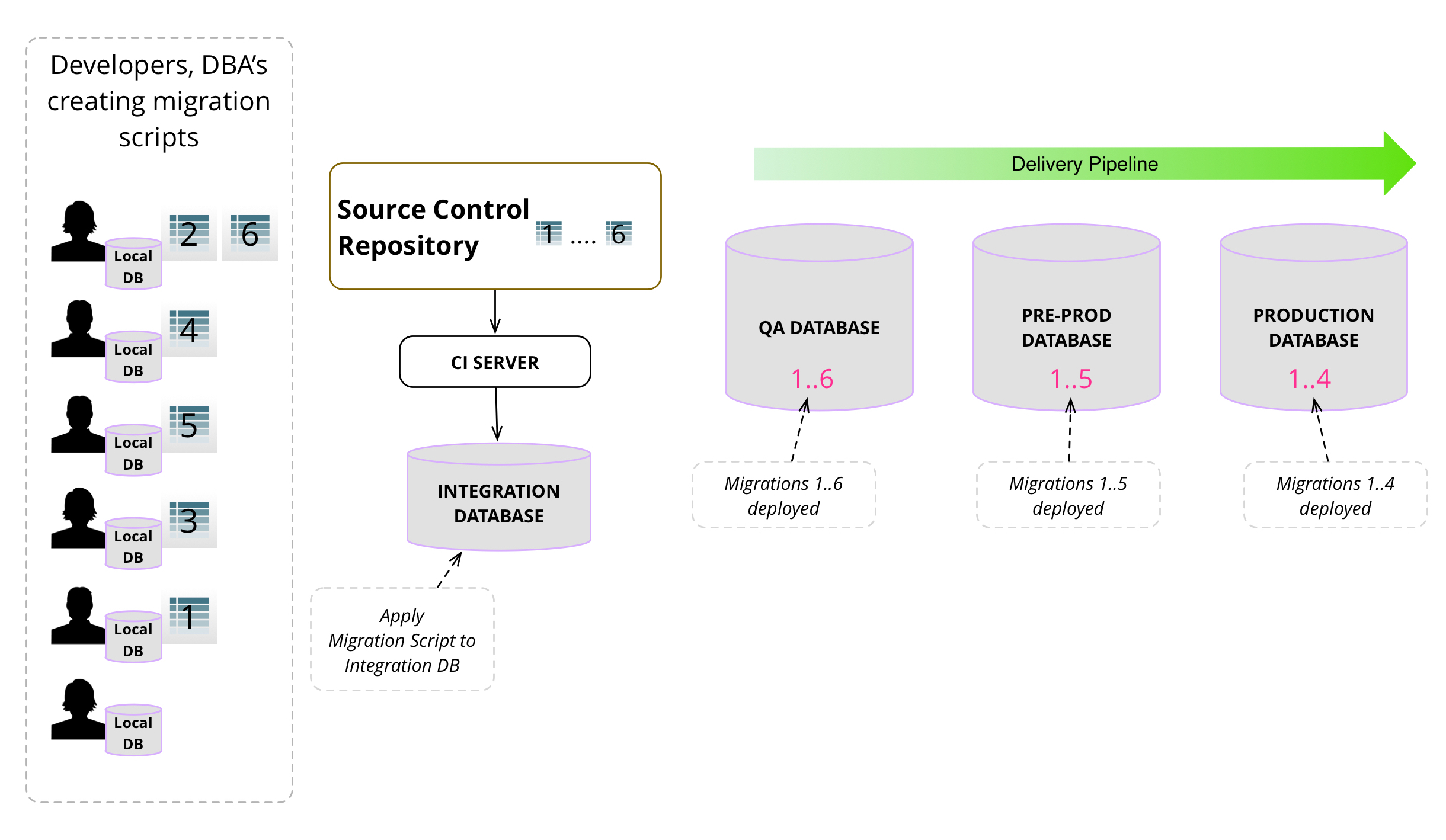
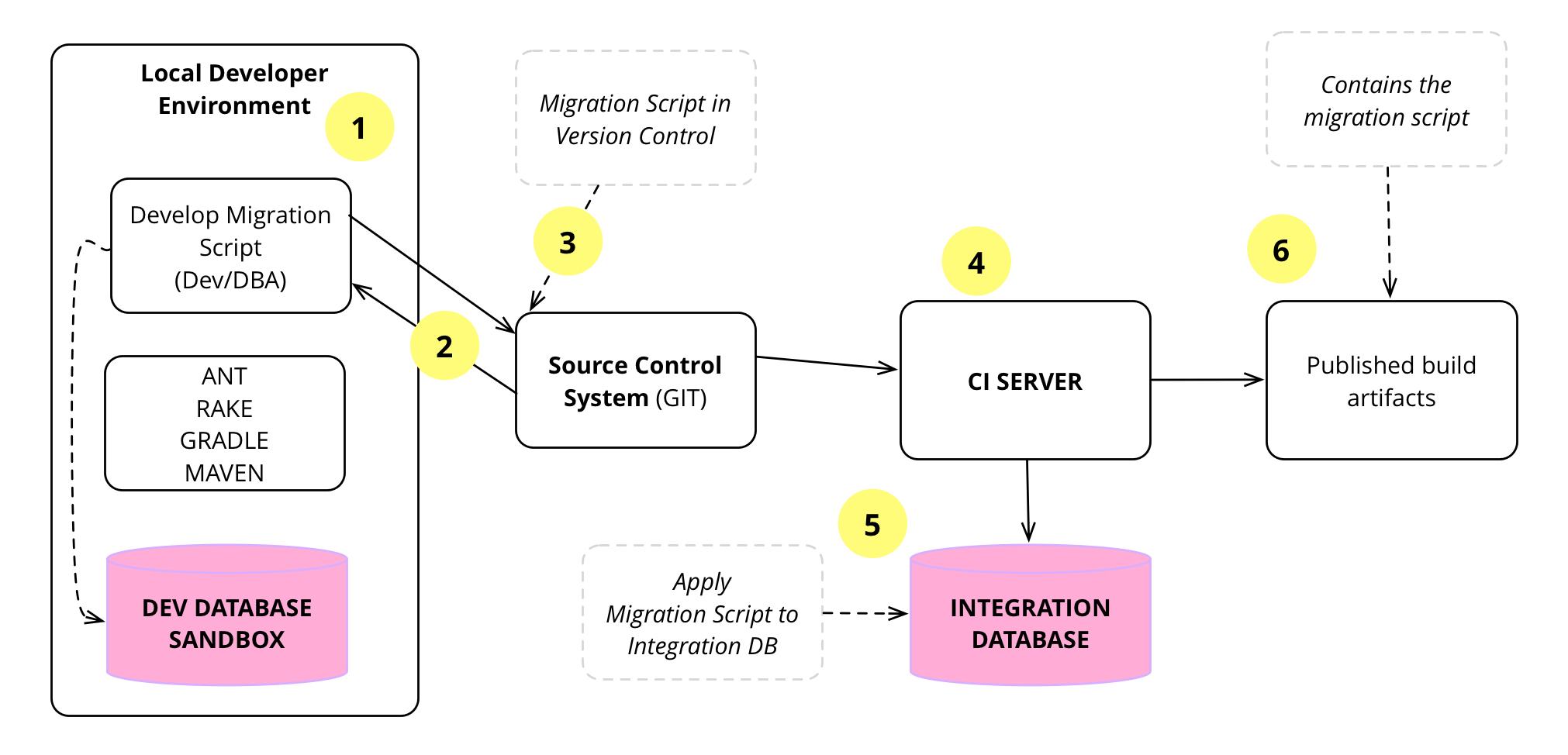
圖 7顯示資料庫遷移如何開發、在本地測試、檢查至原始碼控制、由 CI 伺服器接收並套用至整合資料庫、再次測試,以及封裝供下游使用。
讓我們舉個例子
1
珍開始一項開發,其中包括資料庫架構變更。如果變更很簡單,例如新增一欄,珍決定直接進行變更。如果很複雜,她會找資料庫管理員並與她討論。
一旦她整理出變更,她就會撰寫遷移。
ALTER TABLE project ADD projecttypeid NUMBER(10) NULL;
ALTER TABLE project ADD (CONSTRAINT fk_project_projecttype
FOREIGN KEY (projecttypeid)
REFERENCES projecttype DEFERRABLE INITIALLY DEFERRED);
UPDATE project
SET projecttypeid = (SELECT projecttypeid
FROM projecttype
WHERE name='Integration');
新增可為空的欄位是向後相容的變更,因此她可以在不需要變更任何應用程式程式碼的情況下整合變更。但是,如果它不是向後相容的變更,例如分割表格,那麼珍也需要修改應用程式程式碼。
2
珍完成變更後,她準備好要整合。整合的第一步是從主線更新她的本地副本。這些是團隊其他成員在她處理任務時所做的變更。然後,她透過重建資料庫並執行所有測試,檢查她的變更是否與這些更新一起運作。
如果她遇到問題,由於其他開發人員的變更與她的變更衝突,她需要在自己的副本上修復這些問題。通常此類衝突很容易解決,但偶爾會比較複雜。這些更複雜的衝突通常會觸發 Jen 與她的團隊成員之間的對話,以便他們可以找出如何解決重疊的變更。
一旦她的本地副本再次運作,她會檢查在她工作時是否有任何其他變更已推送到主幹,如果有,她需要重複與新變更的整合。不過,通常在她程式碼完全與主線整合之前,不會花費超過一或兩個此類循環。
3
Jen 將變更推送到主線。由於變更與現有的應用程式程式碼向後相容,因此她可以在更新應用程式程式碼以使用它之前整合資料庫變更 - 這是 平行變更 的常見範例。
4
CI 伺服器偵測到主線的變更並開始一個包含資料庫遷移的新建置。
5
CI 伺服器使用自己的資料庫副本進行建置,因此將資料庫遷移指令碼套用到此資料庫以套用遷移中的變更。此外,它還執行建置步驟的其餘部分:編譯、單元測試、功能測試等。
6
建置成功完成後,CI 伺服器會封裝建置成品並發布它們。這些建置成品包含資料庫遷移指令碼,以便它們可以套用到下游環境中的資料庫,例如 部署管線。建置成品還包含封裝到 jar、war、dll 等中的應用程式程式碼。
這正是 持續整合 的實務,通常用於應用程式原始碼管理。上述步驟只是將資料庫程式碼視為另一段原始碼。因此資料庫程式碼 - DDL、DML、資料、檢視、觸發器、儲存程序 - 會以與原始碼相同的方式在組態管理中保留。每當我們成功建置時,透過將資料庫成品與應用程式成品打包在一起,我們便會擁有應用程式與資料庫的完整且同步的版本歷程。
對於應用程式原始碼,整合變更的許多痛苦都能透過原始碼控制系統和在當地環境中使用各種測試來處理。對於資料庫,由於資料庫中有資料(狀態)需要保留其商業意義,因此需要付出更多努力。(我們稍後會進一步討論像這樣的自動化資料庫重構。)此外,DBA 需要檢視任何資料庫變更,並確保它們符合資料庫結構和資料架構的整體架構。為了讓所有這些順利運作,重大的變更不應在整合時才令人驚訝 - 因此 DBA 需要與開發人員密切合作。
我們強調頻繁整合,因為我們發現頻繁的小型整合比不頻繁的大型整合容易得多 - 這是 頻繁降低難度 的一個案例。整合的痛苦會隨著整合規模呈指數增加,因此實際上進行許多小變更容易得多,即使對許多人來說這似乎違反直覺。
資料庫包含架構和資料
當我們在這裡談論資料庫時,我們的用意不僅是資料庫的結構和資料庫程式碼,還包括大量的資料。此資料包含應用程式的常見常設資料,例如所有州、國家、貨幣、地址類型和各種應用程式特定資料的清單。我們也可能會包含一些範例測試資料,例如幾個範例客戶、訂單等。這些範例資料不會進入生產環境,除非特別需要進行健全性測試或語義監控。
此資料存在於此有許多原因。主要原因是為了進行測試。我們非常相信使用大量的自動化測試來幫助穩定應用程式的開發。此類測試是敏捷方法中的常見做法。為了讓這些測試有效率地運作,在資料庫中加入一些範例測試資料是有意義的,所有測試都可以假設在執行之前已就緒。
這些範例資料需要進行版本控制,因此我們在需要填入新資料庫時知道要去哪裡尋找,而且我們有一個與測試和應用程式程式碼同步的變更記錄。
除了協助測試程式碼之外,這些範例測試資料還允許我們在變更資料庫結構時測試我們的遷移。透過擁有範例資料,我們被迫確保任何結構變更也能處理範例資料。
在我們看過的大多數專案中,這些範例資料都是虛構的。然而在少數專案中,我們看到人們使用真實資料作為範例。在這些情況下,這些資料已從先前的舊系統中透過自動化資料轉換指令碼萃取出來。顯然您無法立即轉換所有資料,因為在早期反覆運算中,實際上只建置了新資料庫的一小部分。但我們可以使用 增量遷移 來開發轉換指令碼,以便適時提供必要的資料。
這不僅有助於及早解決資料轉換問題,還能讓領域專家更輕鬆地使用成長中的系統,因為他們熟悉他們正在檢視的資料,而且通常可以協助找出可能造成資料庫和應用程式設計問題的案例。因此,我們現在的觀點是,您應該嘗試從專案的第一個反覆運算中導入真實資料。我們發現 Jailer 是有助於這個流程的有用工具。
所有資料庫變更都是資料庫重構
我們對資料庫所做的變更會改變資料庫儲存資訊的方式,導入儲存資訊的新方式,或移除不再需要的儲存。但資料庫變更本身並不會改變軟體的整體行為。因此,我們可以將它們視為符合重構的定義。
對軟體的內部結構所做的變更,讓它更容易理解且更便宜地修改,而不會改變其可觀察的行為
-- 重構(第 2 章)
認識到這一點後,我們 收集並記錄了許多這些重構。透過撰寫此類目錄,我們讓這些變更更容易正確地進行,因為我們可以遵循我們之前成功使用的步驟。
資料庫重構的一個重大差異在於,它們涉及必須一起進行的三個不同變更
- 變更資料庫架構
- 移轉資料庫中的資料
- 變更資料庫存取碼
因此,每當我們描述資料庫重構時,我們都必須描述變更的所有三個面向,並確保在套用任何其他重構之前,已套用所有三個面向。
如同程式碼重構,資料庫重構非常小。將一系列極小的變更串連在一起的概念,對於資料庫和程式碼來說都很類似。變更的三維性質使得保持小變更格外重要。
許多資料庫重構,例如 引入新欄位,可以在不更新存取系統的所有程式碼的情況下完成。如果程式碼在不知情的情況下使用新的架構,該欄位將保持未使用狀態。但許多變更沒有這個屬性,我們稱這些為破壞性變更。破壞性變更需要更小心,小心程度取決於所涉及的破壞程度。
輕微破壞性變更的一個範例是 讓欄位非可為 Null,它會將可為 Null 的欄位變更為不可為 Null。這是破壞性的,因為如果任何現有程式碼未將其設定為值,我們將會收到錯誤。如果現有資料中有任何 Null 值,我們也會遇到問題。
我們可以透過將預設資料指定給任何在此處具有 Null 值的列,來避免現有 Null 值的問題(代價是稍微不同的)。對於應用程式程式碼未指定(或指定 Null)的問題,我們有兩個選項。一個是為欄位設定預設值。
ALTER TABLE customer
MODIFY last_usage_date DEFAULT sysdate;
UPDATE customer
SET last_usage_date =
(SELECT MAX(order_date) FROM order
WHERE order.customer_id = customer.customer_id)
WHERE last_usage_date IS NULL;
UPDATE customer
SET last_usage_date = last_updated_date
WHERE last_usage_date IS NULL;
ALTER TABLE customer
MODIFY last_usage_date NOT NULL;
處理缺少指派任務的另一種方法是將應用程式程式碼變更為重構的一部分。如果我們可以自信地取得所有更新資料庫的程式碼,我們會優先選擇這個選項,如果資料庫僅由單一應用程式使用,這通常很容易,但如果是共用資料庫,這就會很困難。
更複雜的情況是 分割資料表,特別是如果對資料表的存取廣泛分散在應用程式程式碼中。如果是這種情況,讓所有人都知道變更即將到來非常重要,這樣他們才能做好準備。等待相對平靜的時機,例如反覆運算的開始,也可能是明智之舉。
如果資料庫存取全部透過系統的幾個模組進行通道,任何破壞性變更都會容易得多。這樣可以更容易地找到並更新資料庫存取程式碼。
整體而言,重要的是選擇適合您正在進行的變更類型的程序。如有疑問,請嘗試從使變更更容易的角度出發。我們的經驗是,我們被燒傷的次數遠低於許多人想像的,而且透過對整個系統進行強有力的組態控制,如果發生最壞的情況,要還原並不困難。
在開發過程中處理包括 DDL、DML 和資料遷移在內的資料庫變更,可以為資料團隊提供最多的背景,避免資料團隊在部署期間在沒有背景的情況下批次遷移所有變更。
過渡階段
當我們進行破壞性資料庫重構,而且無法輕易變更存取程式碼時,我們已經暗示了會遇到困難。當您擁有共用資料庫,而且可能有許多應用程式和報表使用它時,這些問題會長出角和又大又尖銳的牙齒。在這種情況下,您必須對 重新命名資料表 等事項更加小心。為了保護我們免於這些角和牙齒的傷害,我們轉向過渡階段。
過渡階段是一段時間,資料庫同時支援舊的存取模式和新的存取模式。這讓舊系統有時間以自己的步調遷移到新的結構。
ALTER TABLE customer RENAME to client;
CREATE VIEW customer AS
SELECT id, first_name, last_name FROM client;
對於 重新命名資料表 範例,開發人員會建立一個腳本,將資料表 customer 重新命名為 client,並建立一個現有應用程式可以使用名為 customer 的 檢視。這個 平行變更 支援新的和舊的存取。它確實增加了複雜性,因此在下游系統有時間遷移後,將其移除非常重要。在某些組織中,這可以在幾個月內完成,而在某些其他組織中可能需要數年時間。
檢視是啟用過渡階段的一種技術。我們也會使用資料庫觸發器,這對於像重新命名欄位之類的事情非常方便
自動化重構
自從重構技術開始廣泛用於應用程式程式碼後,許多語言都開始支援自動化重構。這些技術透過快速執行各種步驟,且無需人為介入而產生錯誤,簡化並加速了重構的過程。資料庫也可以使用這種自動化技術。像Liquibase和Active Record Migrations這類的架構提供了一個DSL來套用資料庫重構,提供一個標準的方式套用資料庫遷移。
然而,這些類型的標準化重構並不適用於資料庫,因為處理資料遷移和舊資料的規則非常仰賴團隊的特定背景。因此,我們偏好透過撰寫遷移腳本來處理資料庫重構,並專注於自動化如何套用這些腳本的工具。
如我們到目前為止所展示的,我們透過結合SQL DDL(用於架構變更)和DML(用於資料遷移),並將結果放入版本控制儲存庫中的資料夾中,來撰寫每個腳本。我們的自動化機制確保我們絕不會手動套用這些變更,它們只會由自動化工具套用。這樣一來,我們便能維持重構的順序並更新資料庫的元資料。
我們可以將重構套用至任何資料庫實例,以讓它們更新至最新的主版本,或任何以前的版本。此工具會使用資料庫中的元資料資訊找出其目前的版本,然後套用它和目標版本之間的每個重構。我們可以使用這種方法來更新開發實例、測試實例和生產資料庫。
更新生產資料庫和測試資料庫沒有什麼不同,我們針對不同的資料執行相同的腳本組。我們確實偏好頻繁地釋出,因為這樣可以讓更新保持在較小的規模,這表示更新會發生得更快,而且更容易處理任何出現的問題。執行這些更新最簡單的方法是在套用更新時關閉生產資料庫,這在大部分情況下都能順利運作。如果我們必須在應用程式保持運作的同時執行更新,這也是可行的,但我們使用的技術需要另一篇文章才能說明。
到目前為止,我們發現這種技術運作得非常好。透過將所有資料庫變更分解成一系列小而簡單的變更;我們得以對生產資料進行相當大的變更,而不會遇到麻煩。
除了自動化正向變更,您也可以考慮為每個重構自動化反向變更。如果您這樣做,您將能夠以同樣的自動化方式備份資料庫變更。我們尚未發現這足夠具有成本效益和好處,可以隨時嘗試,而且我們對它的需求也不多,但這是一個基本原理。總的來說,我們比較喜歡撰寫遷移,以便資料庫存取區段可以與資料庫的舊版本和新版本一起使用。這讓我們可以更新資料庫以支援未來的需求並使其上線,讓它在生產環境中執行一段時間,然後只有在我們發現它們在沒有問題的情況下穩定下來後,才會推送使用新資料結構的更新。
現在有許多工具可以自動化套用資料庫遷移,包括:Flyway、Liquibase、MyBatis migrations、DBDeploy。以下是使用 Flyway 套用遷移。
psadalag:flyway-4 $ ./flyway migrate
Flyway 4.0.3 by Boxfuse
Database: jdbc:oracle:thin:@localhost:1521:xe (Oracle 11.2)
Successfully validated 9 migrations (execution time 00:00.021s)
Creating Metadata table: "JEN_DEV"."schema_version"
Current version of schema "JEN_DEV": << Empty Schema >>
Migrating schema "JEN_DEV" to version 0 - base version
Migrating schema "JEN_DEV" to version 1 - asset
Migrating schema "JEN_DEV" to version 2 - asset type
Migrating schema "JEN_DEV" to version 3 - asset parameters
Migrating schema "JEN_DEV" to version 4 - inventory
Migrating schema "JEN_DEV" to version 5 - split inventory
Migrating schema "JEN_DEV" to version 6 - equipment type
Migrating schema "JEN_DEV" to version 7 - add insurance value to equipment type
Migrating schema "JEN_DEV" to version 8 - data location equipment type
Successfully applied 9 migrations to schema "JEN_DEV" (execution time 00:00.394s).
psadalag:flyway-4 $
開發人員可以依需求更新資料庫
如上所述,將我們的變更整合到主線的第一步是提取我們在進行自己的工作時發生的任何變更。這不僅在整合步驟中至關重要,而且在我們完成之前通常也很有用,這樣我們就可以評估我們聽同事談論的任何變更的影響。在兩種情況下,能夠輕鬆地從主線提取變更並將它們套用到我們的本地資料庫非常重要。
我們從將變更從主線提取到我們的本地工作空間開始。通常這很簡單,但有時我們會發現我們的同事在我們工作時已將遷移推送到主線。如果我們已撰寫序列號為 8 的遷移,我們會看到另一個具有該號碼的遷移出現在我們的遷移資料夾中。執行我們的遷移工具應該會偵測到這一點
psadalag:flyway-4 $ ./flyway migrate
Flyway 4.0.3 by Boxfuse
Database: jdbc:oracle:thin:@localhost:1521:xe (Oracle 11.2)
ERROR: Found more than one migration with version 8
Offenders:
-> /Users/psadalag/flyway-4/sql/V8__data_location_equipment_type.sql (SQL)
-> /Users/psadalag/flyway-4/sql/V8__introduce_fuel_type.sql (SQL)
psadalag:flyway-4 $
一旦我們發現有衝突,我們的首要步驟很簡單,我們需要將遷移重新編號為 9,以便在主線上的新遷移之上套用。重新編號後,我們需要測試遷移之間沒有任何衝突。為此,我們清理資料庫,然後套用所有遷移,包括新的 8 和我們重新編號的 9 到一個空白的資料庫副本。
psadalag:flyway-4 $ mv sql/V8__introduce_fuel_type.sql sql/V9__introduce_fuel_type.sql
psadalag:flyway-4 $ ./flyway clean
Flyway 4.0.3 by Boxfuse
Database: jdbc:oracle:thin:@localhost:1521:xe (Oracle 11.2)
Successfully cleaned schema "JEN_DEV" (execution time 00:00.031s)
psadalag:flyway-4 $ ./flyway migrate
Flyway 4.0.3 by Boxfuse
Database: jdbc:oracle:thin:@localhost:1521:xe (Oracle 11.2)
Successfully validated 10 migrations (execution time 00:00.013s)
Creating Metadata table: "JEN_DEV"."schema_version"
Current version of schema "JEN_DEV": << Empty Schema >>
Migrating schema "JEN_DEV" to version 0 - base version
Migrating schema "JEN_DEV" to version 1 - asset
Migrating schema "JEN_DEV" to version 2 - asset type
Migrating schema "JEN_DEV" to version 3 - asset parameters
Migrating schema "JEN_DEV" to version 4 - inventory
Migrating schema "JEN_DEV" to version 5 - split inventory
Migrating schema "JEN_DEV" to version 6 - equipment type
Migrating schema "JEN_DEV" to version 7 - add insurance value to equipment type
Migrating schema "JEN_DEV" to version 8 - data location equipment type
Migrating schema "JEN_DEV" to version 9 - introduce fuel type
Successfully applied 10 migrations to schema "JEN_DEV" (execution time 00:00.435s).
psadalag:flyway-4 $
通常這運作得很好,但偶爾我們會看到衝突 - 也許其他開發人員重新命名了我們要變更的表格。在這種情況下,我們需要找出如何解決衝突。這裡,遷移的小型化讓找出和處理衝突變得更容易。
最後,一旦資料庫變更整合完畢,我們需要重新執行應用程式測試套件,以防我們從主線取得的遷移導致我們的任何測試中斷。
此程序讓我們能夠獨立工作一段時間,即使沒有網路連線,然後在任何適合我們的時候整合。我們完全可以決定何時以及多久進行此整合 - 只要確保在推送到主線之前同步即可。
清楚區分所有資料庫存取程式碼
要了解資料庫重構的後果,能夠看到應用程式如何使用資料庫非常重要。如果 SQL 隨意散佈在程式碼庫中,這將非常難以執行。因此,擁有明確的資料庫存取層以顯示資料庫的使用位置和方式非常重要。為此,我們建議遵循 P ofEAA 中的其中一種資料來源架構模式。
擁有明確的資料庫層有許多有價值的附帶優點。它將開發人員需要 SQL 知識來操作資料庫的系統區域減至最低,這讓對於 SQL 常常不特別熟練的開發人員來說生活更輕鬆。對於 DBA 來說,它提供了一個明確的程式碼區段,他可以查看以了解資料庫的使用方式。這有助於準備索引、資料庫最佳化,以及查看 SQL 以了解如何重新制定以執行得更好。這讓 DBA 能夠更深入了解資料庫的使用方式。
頻繁發布
當我們在十多年前撰寫本文的原始版本時,鮮少人支持軟體應該頻繁發佈到生產環境的想法。從那時起,網路巨頭的崛起顯示出一連串快速發佈是成功數位策略的關鍵部分。
透過在遷移中擷取每個變更,我們可以輕鬆將新變更部署到測試和生產環境。我們在此討論的演化式資料庫設計是促成頻繁發佈的重要部分,而且也受益於我們從看到軟體實際使用的回饋中獲得的學習。





{kind=link}