
語言工作台:特定領域語言的殺手級應用程式?
軟體開發中大多數的新點子,其實都是舊有概念的新變體。本文將說明其中之一,即我稱之為語言工作台的工具類別,其範例包括 Intentional Software、JetBrains 的 Meta Programming System 和 Microsoft 的 Software Factories。這些工具採用一種舊式的開發風格,我稱之為語言導向程式設計,並使用 IDE 工具,試圖讓語言導向程式設計成為一種可行的途徑。儘管我並非預言家,無法斷言它們是否能實現其目標,但我確實認為這些工具是軟體開發領域最令人感興趣的事物之一。它們有趣到足以讓我寫下這篇文章,試著至少大略說明它們的運作方式和未來實用性的主要議題。
2005 年 6 月 12 日

長期以來,有一種軟體開發風格試圖使用一系列特定領域語言來描述軟體系統。您可以在 Unix 的「小語言」傳統中看到這種風格,它們透過 lex 和 yacc 產生程式碼;您可以在 Lisp 社群中看到這種風格,它們在 Lisp 內部開發語言,通常借助 Lisp 的巨集。這種方法深受其擁護者喜愛,但這種思考風格並未像許多人希望的那樣流行起來。
在過去幾年中,有人嘗試透過一種新的軟體工具類別來支援這種開發風格。最早且最知名的工具是 Intentional Programming,最初由 Charles Simonyi 在 Microsoft 任職期間開發。然而,也有其他人也在做類似的事情,產生足夠的動能來對這種方法產生一些興趣。
在這裡,我將創造一些術語,並在本文的其餘部分使用它們。與往常一樣,這個領域沒有標準術語,因此不要指望我在此使用的術語會在其他地方以這種風格使用。我將在此提供簡短的定義,但會隨著文章的進行對它們進行更多說明,因此如果您無法立即理解這些定義,請不用擔心。
我特別為本文創造的兩個主要術語是「語言導向程式設計」和「語言工作台」。我使用語言導向程式設計來表示圍繞著構建特定領域語言的集合來建立軟體的開發一般風格。我使用語言工作台作為這個新類別工具的通用術語。因此,語言工作台是執行語言導向程式設計的一種方式。您可能也不熟悉特定領域語言(通常縮寫為DSL)這個術語。它是一種針對特定類別問題設計的有限形式的電腦語言。有些社群喜歡只將 DSL 用於問題領域語言,但我遵循將 DSL 用於任何有限領域的用法。
我將從簡要描述語言導向程式設計的當前世界開始,包括一個範例、不同風格的概述,以及關於這種方法優缺點的各種論點。如果您熟悉語言導向程式設計,您可能想要跳過這些內容,但我發現許多開發人員(確實是大多數開發人員)並不熟悉這些概念。在說明這些概念後,我將在它們的基礎上說明語言工作台是什麼,以及它們如何改變取捨。
在我撰寫本文時,發現它對單篇文章來說太長了,所以我將討論的某些部分分開成其他文章。我會在文中提到在什麼地方閱讀那些文章比較有意義,它們也連結在目錄的正下方。特別是,請查看使用 MPS 的範例,它展示了一個使用當前語言工作台之一建構的 DSL 範例,這可能是了解它們將會是什麼樣子的最佳方式。在它變得更有意義之前,您需要先了解這裡語言工作台的一般說明。
面向語言程式設計的簡單範例
我將從一個非常簡單的語言導向程式設計範例開始,以及導致它的情況。想像我們有一個系統,它會讀取檔案並需要根據這些檔案建立物件。檔案格式為每行一個物件。每一行可以對應到不同的類別,類別由行開頭的四個字元代碼表示。這一行的其餘部分包含類別欄位的資料,這些資料會根據我們討論的類別而有所不同。欄位是由位置而非分隔符號表示。因此,客戶 ID 號碼可能會從字元 4 到 8 開始。
以下是部分範例資料
#123456789012345678901234567890123456789012345678901234567890 SVCLFOWLER 10101MS0120050313......................... SVCLHOHPE 10201DX0320050315........................ SVCLTWO x10301MRP220050329.............................. USGE10301TWO x50214..7050329...............................
點點點表示一些含糊不清且無趣的資料。頂端的註解行是為了幫助您查看字元位置。前四個字元表示資料類型 - SVCL 表示服務呼叫,USGE 表示使用記錄。其後的字元表示物件的資料。因此,服務呼叫中從位置 5 到 18 的字元表示客戶名稱。
為了將這些轉換成物件,您可能會想要為每個案例撰寫特定的程式碼,我希望在幾個案例之後,您會想要透過撰寫單一讀取器類別來簡化任務,您可以使用每個類別的欄位詳細資料對其進行參數化。
這裡有一個簡單的類別可以執行此操作。讀取器類別會讀取檔案。讀取器可以參數化為讀取器策略類別的集合 - 每個目標類別一個。因此,對於我們的範例,我們將為服務呼叫有一個策略,為使用記錄有一個策略。我將策略保存在由代碼鍵控的地圖中。
以下是處理檔案的程式碼
類別 Reader...
public IList Process(StreamReader input) {
IList result = new ArrayList();
string line;
while ((line = input.ReadLine()) != null)
ProcessLine(line, result);
return result;
}
private void ProcessLine(string line, IList result) {
if (isBlank(line)) return;
if (isComment(line)) return;
string typeCode = GetTypeCode(line);
IReaderStrategy strategy = (IReaderStrategy)_strategies[typeCode];
if (null == strategy)
throw new Exception("Unable to find strategy");
result.Add(strategy.Process(line));
}
private static bool isComment(string line) {
return line[0] == '#';
}
private static bool isBlank(string line) {
return line == "";
}
private string GetTypeCode(string line) {
return line.Substring(0,4);
}
IDictionary _strategies = new Hashtable();
public void AddStrategy(IReaderStrategy arg) {
_strategies[arg.Code] = arg;
}
它只會迴圈處理各行,讀取足夠的內容以找出要呼叫的策略,然後交由策略來執行工作。若要讓讀取器執行工作,您需要建立一個新的讀取器,載入策略,並讓它處理您想要處理的檔案。
策略也可以參數化。我們只需要一個策略類別,當我們實例化它時,我們可以使用代碼、目標類別以及輸入對應到目標類別中哪個欄位的字元位置詳細資料對其進行參數化。我將後者保存在欄位萃取器類別的清單中。
類別 ReaderStrategy...
private string _code;
private Type _target;
private IList extractors = new ArrayList();
public ReaderStrategy(string code, Type target) {
_code = code;
this._target = target;
}
public string Code {
get { return _code; }
}
一旦我實例化策略,我就能將欄位萃取器新增到策略中。
類別 ReaderStrategy...
public void AddFieldExtractor(int begin, int end, string target) {
if (!targetPropertyNames().Contains(target))
throw new NoFieldInTargetException(target, _target.FullName);
extractors.Add(new FieldExtractor(begin, end, target));
}
private IList targetPropertyNames() {
IList result = new ArrayList();
foreach (PropertyInfo p in _target.GetProperties())
result.Add(p.Name);
return result;
}
為了處理該行,策略會建立目標類別並使用萃取器來取得欄位資料
類別 ReaderStrategy...
public object Process(string line) {
object result = Activator.CreateInstance(_target);
foreach (FieldExtractor ex in extractors)
ex.extractField(line, result);
return result;
}
萃取器會從行的正確位元中提取資料,並使用反射將值放入目標物件中。
類別 FieldExtractor...
private int _begin, _end;
private string _targetPropertyName;
public FieldExtractor(int begin, int end, string target) {
_begin = begin;
_end = end;
_targetPropertyName = target;
}
public void extractField(string line, object targetObject) {
string value = line.Substring(_begin, _end - _begin + 1);
setValue(targetObject, value);
}
private void setValue(object targetObject, string value) {
PropertyInfo prop = targetObject.GetType().GetProperty(_targetPropertyName);
prop.SetValue(targetObject, value, null);
}
到目前為止,我所描述的是一個用來執行這類事情的非常簡單的函式庫。基本上,我建構了一個抽象,然後可以使用它來指定具體的工作。為了使用抽象,我需要設定策略並將它們載入讀取器中。以下是兩個範例案例的範例。
public void Configure(Reader target) {
target.AddStrategy(ConfigureServiceCall());
target.AddStrategy(ConfigureUsage());
}
private ReaderStrategy ConfigureServiceCall() {
ReaderStrategy result = new ReaderStrategy("SVCL", typeof (ServiceCall));
result.AddFieldExtractor(4, 18, "CustomerName");
result.AddFieldExtractor(19, 23, "CustomerID");
result.AddFieldExtractor(24, 27, "CallTypeCode");
result.AddFieldExtractor(28, 35, "DateOfCallString");
return result;
}
private ReaderStrategy ConfigureUsage() {
ReaderStrategy result = new ReaderStrategy("USGE", typeof (Usage));
result.AddFieldExtractor(4, 8, "CustomerID");
result.AddFieldExtractor(9, 22, "CustomerName");
result.AddFieldExtractor(30, 30, "Cycle");
result.AddFieldExtractor(31, 36, "ReadDate");
return result;
}
我將這視為兩種不同的程式碼樣式。Reader 和 Strategy 類別是一種抽象,最後這段程式碼是設定檔。當您建構這類函式庫類別時,通常有助於思考這兩個部分:抽象和設定檔。抽象可能是類別函式庫、架構或只是一組函式呼叫。抽象可以在許多專案中重複使用,但它不必如此。設定檔程式碼往往是特定的;相當簡單、直接的程式碼。
由於設定檔相當簡單且比抽象更常變更,因此常見的方法是進一步將其分開,並將設定檔完全從 C# 中移除。目前的流行做法是將它放入 XML 檔案中。
<ReaderConfiguration>
<Mapping Code = "SVCL" TargetClass = "dsl.ServiceCall">
<Field name = "CustomerName" start = "4" end = "18"/>
<Field name = "CustomerID" start = "19" end = "23"/>
<Field name = "CallTypeCode" start = "24" end = "27"/>
<Field name = "DateOfCallString" start = "28" end = "35"/>
</Mapping>
<Mapping Code = "USGE" TargetClass = "dsl.Usage">
<Field name = "CustomerID" start = "4" end = "8"/>
<Field name = "CustomerName" start = "9" end = "22"/>
<Field name = "Cycle" start = "30" end = "30"/>
<Field name = "ReadDate" start = "31" end = "36"/>
</Mapping>
</ReaderConfiguration>
XML 有其用途,但並不容易閱讀。我們可以使用自訂語法讓它更容易看到發生了什麼事。或許像這樣
mapping SVCL dsl.ServiceCall 4-18: CustomerName 19-23: CustomerID 24-27 : CallTypeCode 28-35 : DateOfCallString mapping USGE dsl.Usage 4-8 : CustomerID 9-22: CustomerName 30-30: Cycle 31-36: ReadDate
由於您現在已經熟悉這個問題,因此您應該能夠在沒有我的幫助下閱讀語法。
當您查看最後一個範例時,您會看到我們這裡有一個非常小的程式語言 - 僅適用於將固定長度欄位對應到類別的目的。這是 Unix 傳統中 「小語言」 的經典範例。它是針對此任務的特定領域語言。
此語言是一種特定領域語言,並具備許多 DSL 的特性。首先,它只適用於非常狹窄的目的 - 它除了將這些特定固定長度記錄對應到類別之外,無法執行任何其他操作。因此,DSL 非常簡單 - 沒有控制結構或任何其他功能。它甚至不是圖靈完備的。您無法用此語言編寫整個應用程式 - 您只能描述應用程式的其中一個小面向。因此,DSL 必須與其他語言結合才能完成任何事情。但 DSL 的簡單性表示它很容易編輯和翻譯。(我將在稍後詳細說明 DSL 的優缺點。)
現在再看看 XML 表示形式。這是一個 DSL 嗎?我會認為是。它採用 XML 語法 - 但它仍然是一個 DSL - 實際上在許多方面它與前一個範例是相同的 DSL。
這是介紹一個常見區別的時機,您會在程式語言圈中遇到它 - 抽象語法和具體語法之間的區別。語言的具體語法是我們看到的表示形式中的語法。XML 和自訂語言檔案具有不同的具體語法。然而,兩者共用相同的基礎結構:您有多個對應,每個對應都有一個程式碼、一個目標類別名稱和一組欄位。此基礎結構是抽象語法。當大多數開發人員思考程式語言語法時,他們不會做出此區分,但當您使用 DSL 時,這是一個重要的區分。您可以用兩種方式思考這一點。您可以說我們有一個具有兩個具體語法的語言,或兩個共用相同抽象語法的語言。
因此,此範例提出了設計問題 - 對於 DSL,是具有自訂具體語法較好,還是具有 XML 具體語法較好。XML 語法可能更容易解析,因為有許多 XML 工具可用;儘管在這種情況下,自訂語法實際上更容易。我認為自訂語法更容易閱讀,至少在這種情況下是如此。但無論您如何看待此選擇,圍繞 DSL 的核心權衡都是相同的。實際上,您可以辯稱任何 XML 設定檔基本上都是一個 DSL。
讓我們再往回走一步,回到 C# 中的設定檔程式碼 - 這是一個 DSL 嗎?
當您思考這個問題時,請看看這段程式碼。這看起來像這個問題的 DSL 嗎?
mapping('SVCL', ServiceCall) do
extract 4..18, 'customer_name'
extract 19..23, 'customer_ID'
extract 24..27, 'call_type_code'
extract 28..35, 'date_of_call_string'
end
mapping('USGE', Usage) do
extract 9..22, 'customer_name'
extract 4..8, 'customer_ID'
extract 30..30, 'cycle'
extract 31..36, 'read_date'
end
這第二段程式碼與 C# 有關。那些知道我語言喜好的人會猜到最後這個範例實際上是 Ruby 程式碼。事實上,它與 C# 範例完全等價。由於各種 Ruby 特色,它看起來更像自訂 DSL:最低限度的侵入式語法、範圍文字,以及彈性的執行階段評估。這是完整的組態檔,可以在執行階段讀取並評估物件實例的範圍。但它仍然是純 Ruby,並透過方法呼叫 mapping 和 extract 與架構程式碼互動,這對應於 C# 範例中的 AddStrategy 和 AddFieldExtractor。
我會主張 C# 和 Ruby 範例都是 DSL。在這兩種情況下,我們都使用主機語言功能的子集,並擷取與 XML 和自訂語法相同的想法。基本上,我們將 DSL 嵌入到主機語言中,使用主機語言的子集作為抽象語言的自訂語法。在某種程度上,這更是一種態度,而不是其他任何事情。我選擇透過面向語言程式設計眼鏡來看 C# 和 Ruby 程式碼。但這是一個有悠久傳統的觀點 - Lisp 程式設計師經常想到在 Lisp 內部建立 DSL。這些內部 DSL 的取捨顯然與外部 DSL 不同,但仍有許多相似之處。(我也會在稍後擴充這些取捨。)
現在我已經展示了 DSL 的範例,我可以更好地定義面向語言程式設計。面向語言程式設計是透過多個 DSL 來描述系統。這是一個漸進的事情,您可以在系統中使用一些面向語言程式設計,其中只有部分功能以 DSL 表示;或者您可以在 DSL 中表示大部分功能,並使用大量的面向語言程式設計。您使用多少面向語言程式設計很難衡量,特別是如果您使用語言內 DSL。通常,就像任何可重複使用的程式碼一樣,您自己撰寫一些 DSL,並從其他地方使用其他 DSL。
面向語言程式設計的傳統
正如我的範例所示,面向語言程式設計並不是什麼新鮮事 - 人們已經從事面向語言程式設計一段時間了。因此,在我們探討語言工作台對圖片的影響之前,值得探討一下面向語言程式設計的現狀。
有許多面向語言程式設計的風格。現在是總結其中幾個的好時機。
Unix 小語言
世界上最明顯的 DSLy 部分之一是 Unix 撰寫小語言的傳統。這些是外部 DSL 系統,通常使用 Unix 的內建工具來協助翻譯。在大學時,我玩了一點 lex 和 yacc - 類似的工具是 Unix 工具鏈的常規部分。這些工具可以輕鬆撰寫解析器並為小語言產生程式碼(通常是 C)。Awk 是這種迷你語言的一個很好的範例。
Lisp
Lisp 可能是在語言本身中直接表達 DSL 的最強範例。符號處理嵌入在 Lisp 使用者的名稱和實務中。Lisp 的功能有助於此 - 最小語法、封閉和巨集提供了 DSL 工具的濃烈雞尾酒。Paul Graham 寫了很多關於這種開發風格的文章。Smalltalk 也有這種開發風格的悠久傳統。
主動資料模型
如果你遇到一些更老練的資料建模人員,他們會向你展示資料庫表格中的資料如何編碼系統中高度變異的部分(通常稱為元資料表格或表格驅動程式)。然後,程式碼可以詮釋表格中的資料以執行行為。
這基本上是一種具體語法為資料庫表格的 DSL。通常,這些表格會透過某種形式的 GUI 介面進行管理,以編輯此主動資料。通常,執行此操作的人員不會考慮建立語言,而且使用關聯式具體語法通常有助於保持語言簡潔且重點明確。
適應式物件模型
與死忠的物件導向程式設計人員交談,他們會告訴你他們建立的系統,這些系統依賴於將物件組成靈活且強大的環境。此類系統是由精密的領域模型建構而成,其中大部分行為來自將物件連接到組態中,以處理各種複雜案例。OO 人員將 適應性物件模型 視為類固醇上的主動資料模型。
此類適應性模型是一種語言內 DSL。迄今為止的經驗表明,它們允許熟悉適應性模型的人員在模型開發並穩定後極具生產力。負面影響是,此類模型通常很難讓新人理解。
XML 組態檔
造訪一個現代 Java 專案,你可能會誤以為系統中的 XML 比 Java 還多。企業 Java 系統使用各種架構,其中大多數都擁有複雜的 XML 組態檔。這些檔案基本上是 DSL。XML 很容易解析,儘管不如自訂格式容易閱讀。人們會為 IDE 編寫外掛程式,以協助操作 XML 檔案,供那些發現尖括號會傷眼的使用者使用。
GUI 建構器
自從人們開始建構 GUI 以來,一直都有允許你透過拖放控制項來配置 GUI 的系統。Visual Basic 可能是最著名的範例,但在 GUI 變得普遍之前,我已經使用過類似的螢幕建構器來處理字元螢幕。這些工具會將配置儲存在封閉格式中,產生適合執行的程式碼;或者它們會嘗試將所有必要資訊放入產生的程式碼中。儘管它們在視覺上很漂亮,但我們越來越發現,儘管它們可以進行吸引人的示範,但這種互動方式有其限制。許多經驗豐富的 GUI 開發人員不建議將 GUI 建構器用於相當複雜的應用程式,限制之多可見一斑。
GUI 建構器是一種 DSL,但其編輯體驗與我們習慣使用的文字程式語言截然不同。因此,建構它們的人通常不會將它們視為語言,有些人認為這是它們問題的一部分。
面向語言程式設計的優缺點
回顧這些樣式,我們可以看到各種以語言為導向的程式設計相當盛行。粗略地概括來說,我發現將它們分為兩種更廣泛的樣式很有用。外部 DSL 使用與應用程式的主要(主機)語言不同的語言撰寫,並透過某種形式的編譯器或直譯器轉換為該語言。Unix 小語言、主動資料模型和 XML 組態檔都屬於此類別。內部 DSL 將主機語言轉變為 DSL 本身,Lisp 傳統就是最好的範例。
我為這篇文章創造了外部/內部術語,因為對於我認為有用的區別,並沒有明確的一組術語。內部 DSL 通常稱為「嵌入式 DSL」,但我避免使用「嵌入式」這個術語,因為它會與應用程式中的嵌入式語言混淆(例如嵌入在 Word 中的 VBA,如果是的話,就是外部 DSL。)不過,如果你在更多關於 DSL 的文章中四處查看,你可能會遇到嵌入式術語。
外部 DSL 和內部 DSL 的取捨相當不同,因此最好分別探討它們。
外部 DSL
我將外部 DSL 定義為使用與應用程式的主要語言不同的語言撰寫的 DSL,例如我們簡單範例中的最後兩個形式。Unix 小語言和 XML 組態檔就是這種樣式的良好範例。
外部 DSL 的主要優點是你可以在任何你喜歡的格式中自由使用。因此,你能夠以最容易閱讀和修改的形式表達網域。格式僅受你建構可以剖析組態檔並產生可執行項目的翻譯器的能力限制,通常使用你的基礎語言。
接著會出現一個明顯的缺點,你必須建構這個翻譯器。對於像我上面展示的簡單語言來說,這並不困難。雖然更複雜的語言會讓它更困難,但仍然沒有那麼糟。剖析器產生器和編譯器編譯器工具可以幫助你操作相當複雜的語言,當然 DSL 的重點在於它們通常相當簡單。XML 限制了 DSL 的形式,但讓它非常容易剖析。
外部 DSL 的一大缺點是它們缺乏我所謂的符號整合,也就是說 DSL 沒有真正連結到我們的基礎語言。基礎語言環境不知道我們在做什麼。現在程式設計環境變得越來越複雜,這成為一個越來越大的問題。
舉個簡單的例子,假設我們想重新命名簡單範例中目標類別的屬性。使用一流的現代 IDE,自動重構命名是習慣性的。但這種重新命名不會傳播到 DSL。我稱之為 C# 世界和檔案對應 DSL 之間的符號障礙。我們可以將對應轉換為 C#,但障礙限制了我們操作整體程式的能力。
這種整合性不足會在許多方面影響我們的工具。首先 - 我們如何編輯我們的 DSL?文字編輯器可以完成這項工作 - 但現代 IDE 讓文字編輯器看起來越來越原始。我應該在欄位名稱上取得快顯清單和完成,如果字元範圍重疊,則會出現紅色波浪線。但要做到這一點,我需要一個了解我的 DSL 語意的編輯器。
也許我可以不用語意編輯器。但接著考慮除錯。我的除錯器可以逐步執行 C# 轉換,但無法進入實際來源本身。我真正想要的是一個我的 DSL 的完整 IDE。在文字編輯器和簡單除錯器的時代,這不是一個大問題 - 但我們現在生活在後 IntelliJ世界中。
對外部 DSL 特別常見的異議是語言混亂問題。這個問題是語言難以學習,因此使用多種語言會比使用單一語言複雜得多。在某種程度上,這種擔憂基於對 DSL 的誤解。有這種擔憂的人通常會想像多種通用語言,這確實很容易導致混亂。但 DSL 往往有限且簡單,這使得它們更容易學習。這一點因它們與網域的接近性而得到加強。DSL 看起來不像常規程式語言。
基本上,在任何合理大小的程式中,你都在處理一堆你需要的抽象,例如入門範例中的檔案讀取範例。我們通常使用物件和方法來操作這些抽象。這很有效,但提供了一個有限的語法來表達我們想說的話(儘管有限程度取決於我們的基礎語言)。使用外部 DSL 讓我們有機會擁有更容易操作的語法。問題在於透過外部 DSL 操作的增加容易性是否大於一開始理解新 DSL 的成本。
與此問題相關的是對於設計 DSL 的困難性感到憂心 - 語言設計很困難,因此對於大多數專案來說,設計多個 DSL 會太困難。此反對意見通常依賴於思考通用語言而非 DSL。在此,我認為基本問題是取得良好的抽象 - 這是任務的困難之處。API 設計與 DSL 設計之間的差異很小 - 因此我不認為設計 DSL 會比設計良好的 API 困難許多。
對於許多人來說,外部 DSL 的一大優點是 DSL 可以於執行階段評估。這允許變更參數而不重新編譯程式。這是 XML 設定檔在 Java 世界中如此受歡迎的主要原因。雖然這是靜態編譯語言的重要問題,但請務必記住,許多語言可以在執行階段輕鬆評估表達式,因此對它們來說這不是問題。混合編譯時間和執行階段語言的興趣也日益增加,例如 .NET 中的 IronPython。這允許您在主要為 C# 系統的環境中評估 IronPython 內部 DSL。這是 Unix 世界中混合 C/C++ 與指令碼語言的常見技術。
內部 DSL
內部 DSL 翻轉了 ex 語言 DSL 的優缺點。我們使用基本語言消除了符號障礙。我們在任何時候都可以使用基本語言的全部功能,以及基本語言中存在的所有工具。Lisp 和自適應物件模型是內部 DSL 的範例。
討論此問題時的一個問題是,主流大括號程式語言 (C、C++、Java、C#) 與特別適合內部 DSL 的語言(例如 Lisp)之間有很大的差異。內部 DSL 風格在 Lisp 或 Smalltalk 中比在 Java 或 C# 中更容易實現 - 事實上,動態語言的倡導者指出這是他們的優勢之一。我們看到一些人使用指令碼語言重新發現這一點 - 考慮Ruby 的元程式設計能力,以及Rails 框架如何使用它們。這個問題因許多程式設計人員從未認真使用動態語言而變得更加複雜,因此不了解它們的能力(和真正的限制)。
內部 DSL 受限於基礎語言的語法和結構。更動態的語言受限較少。它們具有最低限度的侵入性語法(例如 lisp、smalltalk 和腳本語言),通常比主流大括號語言更有效,這在比較 C# 和 ruby 範例時非常明顯。封閉和巨集等語言功能也很有價值。雖然 C 基礎語言缺少許多此類機制,但我們看到一些功能可以支援此類思考。註解(C# 中的屬性)就是此類語言功能的一個好範例,對於此類目的可能非常有用。
雖然您有基礎語言的工具,但此基礎語言實際上並不知道您使用 DSL 的目的,因此工具並不完全支援 DSL。您仍然比使用文字編輯器來得好,但仍有很大的進步空間。
在 DSL 中擁有語言的全部功能是一把雙面刃。如果您熟悉基礎語言,一切都很好。然而,DSL 的優點之一是它允許人們在不了解完整基礎語言的情況下進行編程,這使得非專業程式設計人員可以將特定領域的資訊直接輸入系統。內部 DSL 可能會讓這件事變得困難,因為使用者在不熟悉完整基礎語言的情況下,可能會在許多地方感到困惑。
思考這件事的一種方式是,通用程式設計語言提供了許多工具,但您的 DSL 只使用其中少數幾個工具。擁有比您需要的更多工具通常會讓事情變得更困難,因為您必須先了解所有這些工具,才能找出您使用的少數工具。理想情況下,您只想要工作所需的實際工具,當然不能更少,但只能再多一些。(Charles Simonyi 用自由度的概念討論了這個想法。)
這裡有一個與辦公室工具的類比。許多人抱怨現代文字處理器很難使用,因為它們有數百種功能,遠遠超過任何單一人的需求。但由於所有這些功能都是某人需要的,因此辦公室程式最終透過建立大型系統來滿足所有人。另一種方法是擁有多個辦公室工具,每個工具都專注於單一任務。這些工具中的每個工具都將更容易學習和使用。當然,問題在於建立所有這些特殊用途的辦公室工具成本很高。這與通用程式設計語言(帶有內部 DSL)和外部 DSL 之間的權衡非常相似。
由於內部 DSL 與程式語言接近,因此當您想要表達無法很好地對應到程式語言本身的內容時,這可能會造成困難。例如,在企業應用程式中,通常會有層級的概念。這些層級可以在很大程度上使用程式語言的封裝結構來定義,但很難定義層級之間的相依性規則。因此,您可能會將所有 UI 程式碼放入 MyApp.Presentation,而將您的網域邏輯放入 MyApp.Domain,但沒有內部 DSL 機制可以指出 MyApp.Domain 中的類別不應參照 MyApp.Presentation 中的類別。在某種程度上,這再次反映了常見語言的動態性有限,由於您可以更深入地存取元層級,因此 Smalltalk 中可以做到這類事情。
(作為比較,我很好奇看到我的 更複雜範例 在這些動態語言之一中開發出來。我可能不會去做,但我懷疑其他人可能會做,如果是這樣,我會更新 進一步閱讀。)
讓非程式設計師參與
在兩種形式的語言導向程式設計中不斷出現的主題之一是外行程式設計師的參與:不是專業程式設計師,但會在開發工作中使用 DSL 進行程式設計的網域專家。外行程式設計的目標一直是軟體世界的恆久目標,確實許多人相信早期的高級語言(COBOL 和 FORTRAN)預示著程式設計師的終結,因為使用者會使用它們。這讓我們想起我所謂的COBOL 推論,即大多數被認為會淘汰專業程式設計師的技術並未做到這一點。
儘管有 COBOL 推論,但人們時不時會成功地讓使用者直接輸入程式。執行此操作的方法之一是找出一個足夠簡單且有限的問題部分,讓使用者可以在這個空間中安全且舒適地進行程式設計。然後,您將每個這些使用者可程式設計的區域轉換成 DSL。這些 DSL 可能相當複雜,MatLab 是專注於網域而運作的相當複雜 DSL 的一個好範例。
外部 DSL 對使用者可程式設計 DSL 的優點在於,你可以拋棄主機語言的所有包袱,並呈現出對使用者來說非常清楚的東西。這對於語法較為嚴格的語言來說尤其重要。但即使對於簡單的語言,你仍會在內部 DSL 中遇到一個問題,即使用者可以輕鬆地執行在語言中看似合理,但卻超出 DSL 範圍的事情。這會讓使用者對他們看來奇怪的行為和神秘的錯誤訊息感到困惑。
許多面向語言程式設計的倡導者對未來抱持著一個願景,即系統的所有網域邏輯都由使用者完成。然後,程式設計師撰寫必要的支援工具,讓使用者可以編輯和編譯這些程式。雖然這並不意味著專業程式設計師的終結,但它將大幅減少所需的人數(因為這些工具中的許多都可以重複使用),而且它將消除許多導致當今軟體開發進度緩慢的溝通問題。這種非專業程式設計師願景很有吸引力,但 COBOL 推論卻嘲諷地懸掛在它上面。
最後,我認為非專業程式設計是一種有價值的事物,但並非面向語言程式設計的全部重點。即使非專業程式設計師不採用,一個好的 DSL 也可以讓專業程式設計師的生產力更高。一個好的 DSL 最終可能由專業程式設計師撰寫,但可以由網域專家進行有用的審查。
非專業程式設計師論點是一個高風險的賭注。如果有人主要基於啟用大規模使用者程式設計來證明某項技術,我會充滿懷疑。然而,如果這種方法能夠成功,它將帶來巨大的好處。這並非來自於消除專業程式設計師,而是改善網域專家和程式設計師之間經常糟糕的溝通狀態。這種溝通不良通常是軟體開發專案中最大的障礙。
總結面向語言程式設計的權衡取捨
對我來說,面向語言程式設計的基本問題是使用 DSL 的好處與建構必要工具以有效支援它們的成本之間的權衡。使用內部 DSL 可以降低工具成本,但對 DSL 本身的限制也可能大幅降低好處,特別是如果你限於使用基於 C 的語言。外部 DSL 可以讓你發揮最大的好處,但設計語言、建構翻譯器以及考量支援程式設計的工具的成本也更高。
這就是面向語言程式設計沒有那麼流行的原因。語言內和語言外技術都有顯著的缺點。因此,有一個令人沮喪的差距,一種我們應該能夠使用 DSL 做更多事情的感覺,而我們目前還沒有做到。
這恰好引出語言工作台的論據。語言工作台的承諾基本上是它們提供外部 DSL 的彈性,而沒有語義障礙。此外,它們讓建立與現代 IDE 最佳功能相符的工具變得容易。結果讓面向語言的程式設計更容易建立和支援,降低了讓面向語言的程式設計對許多人來說如此困難的障礙。
現今的語言工作台
我將從簡要提及我遇到的符合此語言工作台類別的一些工具開始。請記住,所有這些工具都處於開發的早期階段。我們仍需要幾年時間才能看到可供大型軟體開發使用的語言工作台。
Intentional Software
這些工具的教父是 Intentional Programming。Intentional Programming 最初是由 Charles Simonyi 在 Microsoft Research 開發的。幾年前,Simonyi 離開 Microsoft 並創立自己的公司,獨立開發 Intentional Software。與此類新創公司常見的情況一樣,他對開發過程並未十分公開。結果,關於 Intentional Software 中的內容以及如何使用它的資訊非常缺乏。
我有機會花一點時間使用 Intentional Software,而我在 Thoughtworks 的幾位同事在過去一年左右的時間裡與 Intentional 密切合作。因此,我有機會一窺 Intentional 的面紗 - 儘管我受到限制,無法透露我在那裡看到多少。幸運的是,他們打算在未來一年左右的時間裡開始公開他們的工作。
(作為術語說明,Intentional 的人使用術語「Intentional Programming」來指稱他們在 Microsoft 所做的較早工作,並使用「Intentional Software」來指稱他們自那以後所做的工作。)
元程式設計系統
較新的計畫是 Meta Programming System,由 JetBrains 開發。由於其出色的 IDE 工具,JetBrains 在軟體開發人員中享有很高的聲譽。
JetBrains 在 IDE 方面的經驗與語言工作台相關,有幾種方式。首先,他們在 IntelliJ 上的成功讓他們在工具界獲得了很高的信譽 - 既是技術能力,也是實用主義。其次,語言工作台的大部分功能都與讓後 IntelliJ IDE 如此強大的功能緊密相關。
JetBrains 花了幾年的時間建立一個用於開發網路應用程式的精密環境,稱為 Fabrique。建立 Fabrique 的經驗讓他們確信,他們需要一個平台,以便在未來更有效地建立這些類型的工具 - 這種渴望促使他們開發 MPS。
MPS 深受 Intentional Software 公開資訊的影響。它的開發時間遠少於 Intentional 的作品,但 JetBrains 相信一個非常開放的開發週期。只要他們有可用的東西,他們就會在早期存取計畫下提供 MPS。目前他們希望在 2005 年上半年做到這一點。
我最近很幸運地與 MPS 幕後推手 Sergey Dmitriev 密切合作。MPS 活動來自 JetBrains 的麻薩諸塞州辦公室,這有助於我輕鬆拜訪他們。由於這種地理上的相似性和他們的開放性,我使用 MPS 來幫助描述一些 詳細範例(儘管在本文中進展得更深入之前,它們不會有太大意義。不用擔心,到時候我會再次提供連結給您。)
軟體工廠
軟體工廠 是由 Jack Greenfield 和 Keith Short 在 Microsoft 領導的一項計畫。軟體工廠有幾個元素,我不會在此深入探討(除了不要讓可怕的名稱嚇退你)。與本文相關的元素是 DSL 工作 - 面向語言的程式設計在軟體工廠中扮演著重要的角色。
軟體工廠團隊有模型驅動開發的背景。他們包括活躍於 CASE 工具開發的人員,以及英國 OO 社群的許多領導人物。因此,他們的 DSL 傾向於更圖形化的方式也就不足為奇了。然而,與大多數 CASE 工具人員不同,他們對語意和對程式碼生成的控制非常感興趣。
我這裡的大部分討論都指的是應用程式的傳統程式設計。軟體工廠團隊特別有興趣將 DSL 用於軟體開發的其他領域,這些領域通常無法自動化,例如部署、測試和文件編寫。他們還正在探索模擬器,用於您不希望在開發中直接執行 DSL 的情況 - 例如部署 DSL。
Microsoft 的 DSL 團隊已將 下載 提供了幾個月,作為 Visual Studio 2005 Team System 的一部分。
模型驅動架構 (MDA)
如果您一直在追蹤 OMG 的 MDA,您會注意到我所說關於語言工作台與 MDA 願景之間的許多相似之處。這是一個有爭議的問題,但就目前而言,我會說某些 MDA 願景是語言工作台的形式,但並非全部。我也會說,我相信在 MDA 上建立語言工作台存在嚴重缺陷。我寫了一篇相關文章來更詳細地討論這個問題,但在您完成這篇文章之前,這篇文章可能沒有太大意義。
語言工作台的元素
儘管這些工具都不同,但它們確實有一些共同的特徵和類似的部分。
語言工作台最強大的品質之一是它們改變了編輯和編譯程式之間的關係。它們本質上從編輯文字檔案轉變為編輯程式的抽象表示。讓我花幾個段落來解釋最後一句話。
在傳統程式設計中,我們使用文字編輯器在文字檔案上編輯程式的文字。然後,我們通過執行一個將這些文字檔案轉換成電腦可以理解和執行的內容的翻譯器,使該檔案可執行。這種翻譯可能發生在執行時間,例如對於 Python 或 Ruby 等腳本語言,或者作為 Java、C# 和 C 等編譯語言的單獨步驟。
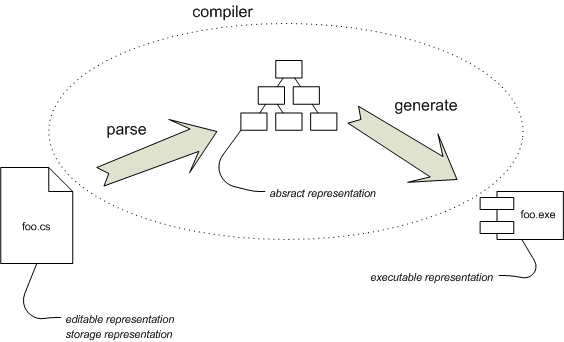
圖 1:傳統編譯的概要。
讓我稍微分解一下這個過程。圖 1顯示了編譯過程的簡化視圖。要將 foo.cs 轉換為可執行內容,我們對其執行編譯器。為了討論這個問題,我們可以將編譯過程分解為兩個步驟。第一步從檔案 foo.cs 中取出文字並將其解析為抽象語法樹 (AST)。第二步遍歷此樹,產生 CLR 位元組碼,並將其放入組建中(一個 exe 檔案)。
{kind=link}
我們可以認為程式有多個表示,其中編譯器在這些表示之間進行翻譯。原始碼檔案是可編輯的表示,也就是當我們想要變更程式時所操作的表示。它也是儲存表示,也就是儲存在原始碼控制中並在我們想要再次取得程式時使用的表示。當我們執行編譯器時,第一階段會將可編輯的表示對應到抽象表示(抽象語法樹),然後程式碼產生器將其轉換為可執行表示(CLR 位元組碼)。
(在真正成為最終可執行檔之前,可執行程式碼上還有更多翻譯。但一旦我們有了位元組碼,編譯器的工作就完成了,而剩下的所有工作都留給了其範圍之外的後續階段。)
抽象表示非常暫時 - 它只存在於編譯器執行時,並且僅用於將編譯分為兩個邏輯步驟。這種暫時性當然是外部 DSL 難以獲得符號整合的主要原因。每種語言都執行單獨的編譯,因此抽象表示之間沒有連結。只有在產生程式碼時,才會將所有內容組合在一起,而此時會遺失關鍵抽象。
更精密的 IntelliJ 後期 IDE 對此模型做出了重大改變。當 IDE 載入檔案時,它會在記憶體中建立一個抽象表示,並使用它來協助您編輯檔案。(Smalltalk 也做了此功能的精簡版本。)此抽象表示有助於執行簡單的工作,例如方法名稱完成,以及複雜的工作,例如重構(自動化重構是抽象表示的轉換)。
我的同事 Matt Foemmel 描述了在 IntelliJ 中工作時,這如何讓他印象深刻。他做了一個變更,這些功能對此變更提供了極大的協助,並且突然意識到他沒有在輸入文字 - 相反地,他是在針對抽象表示執行命令。儘管 IDE 將這些抽象表示中的變更翻譯回文字 - 但他實際上操作的是抽象表示。如果您在使用現代 IDE 時也有類似的感覺,那麼您就能感受到語言工作台的作用。
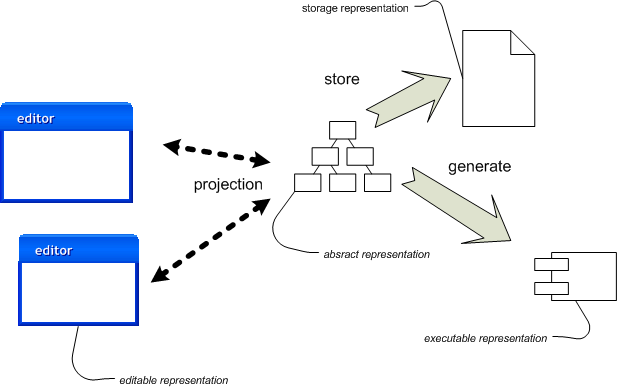
圖 2:使用語言工作台操作表示。
圖 2 顯示此程序如何使用語言工作台運作。此處的主要差異在於「來源」不再是可編輯的文字檔案。您操作的主要來源是抽象表示本身。為了編輯它,語言工作台會將抽象表示投影到某種可編輯表示中。但此可編輯表示純粹是暫時的 - 它只存在於協助人類。真正的來源是持久的抽象表示。
{kind=link}
可編輯表示只是抽象表示的投影,這一點導致了幾個重點。也許最重要的重點是,可編輯表示不需要完整 - 抽象表示的某些方面如果對手邊的工作不重要,則可以省略。此外,您可以有多個投影 - 每個投影顯示抽象表示的不同方面。由於投影位於語言工作台中,因此可編輯表示比文字檔案更為活躍。此投影編輯器與語言本身緊密結合。因此,在思考可編輯表示時,您會積極思考編輯器如何使用它們。這會產生與純被動可編輯表示(例如文字)不同的想法。
語言工作台將儲存表示法與可編輯表示法分開。儲存表示法現在是抽象表示法的序列化。執行此項操作的常見方法是 XML,但此 XML 並非設計用於人類編輯。將 XML 作為儲存表示法有助於工具互操作性,儘管此類互操作性可能非常困難。
程式碼產生幾乎相同,儘管此類工具可能會將傳統來源視為可執行表示法。如果它們確實產生常規語言來源檔案,這些檔案並非真正的來源,且與其他產生的程式碼一樣,不應直接編輯。隨著語言工作台的成熟,我們應會看到更多依賴產生非可編輯結構(例如位元組碼)。
語言工作台的一個不顯而易見但重要的特點是抽象表示法必須能舒適地處理錯誤和歧義。傳統上,人們認為如果您要有一個抽象表示法,則需要保持其正確性,您不應能夠將不正確的資訊放入其中。然而,此假設導致了糟糕的可用性。後 IntelliJ IDE 意識到這一點,並優雅地對錯誤狀態做出反應。例如,您可以對有編譯錯誤的程式執行重構(對於良好的可用性非常必要)。
如果您想從多個來源擷取複雜資訊,這變得更加重要。您無法始終保持一切一致且正確。因此,您必須處理模稜兩可和錯誤的狀態,重點標示錯誤,而不是拒絕輸入。您還應允許人們輕鬆地將不可計算資訊(例如文件)輸入模型。這樣,掃描的餐巾紙就可以直接連結到產生的 DSL 程式碼。
定義新的 DSL
有了這種設定,定義新的 DSL 有三個主要部分
- 定義抽象語法,也就是抽象表示法的架構。
- 定義一個編輯器,讓人們透過投影來操作抽象表示法。
- 定義一個產生器。這說明如何將抽象表示法轉換為可執行表示法。在實務上,產生器定義 DSL 的語意。
這是主要三人組,但會有變化。正如我前面提到的,沒有理由不能為 DSL 擁有多個編輯器或產生器。多個編輯器可能很常見。不同的人可能喜歡不同的編輯體驗。例如,Intentional 的編輯器允許您輕鬆地在同一個模型的不同投影之間切換,以便您可以將階層資料結構視為 lispy 清單、巢狀方塊或樹狀結構。
多個產生器可能出於多種原因出現。您可能希望它們與執行類似工作的不同框架進行繫結。一個很好的例子就是令人討厭的 SQL 多種方言。另一個原因是針對不同的效能特性或函式庫依賴關係進行不同的實作權衡。第三個原因是產生不同的語言:例如,允許單一 DSL 產生 Java 或 C#。
另一個可選的額外功能可能是為儲存表示法定義轉譯器。我們可以假設語言工作台將附帶一個預設儲存架構,自動處理抽象表示法的序列化。但是,您可能希望產生替代的儲存表示法,以實現工具之間的互操作性或傳輸。與產生器不同,這必須是一個雙向表示法。
另一種產生器會定義人類可讀的說明文件 - 相當於 javadoc 的語言工作台。雖然與語言工作台的大部分互動都會透過編輯器進行,但仍然需要產生網路或紙本說明文件。
定義語言工作台
對於語言工作台的定義並無普遍接受的共識。這並不令人意外,因為我剛剛才為這篇文章創造了這個術語!但我認為,為了避免軟體業務中許多主題周圍存在的猖獗歧義(例如元件、服務導向架構),我應該嘗試簡要說明語言工作台的基本特性,現在我已經提供了必要的背景,可以簡要說明。
- 使用者可以自由定義彼此完全整合的新語言。
- 資訊的主要來源是持續性的抽象表示。
- 語言設計人員以三個主要部分定義 DSL:架構、編輯器和產生器。
- 語言使用者透過投影編輯器操作 DSL。
- 語言工作台可以在其抽象表示中保留不完整或矛盾的資訊。
語言工作台如何改變面向語言程式設計的權衡取捨。
一段時間前我討論了面向語言程式設計的權衡。語言工作台顯然會影響該權衡,並帶來許多新的考量因素。
語言工作台對等式做出的最明顯改變是簡化了建立外部 DSL 的過程。您不再需要撰寫剖析器。您確實必須定義抽象語法 - 但那實際上是一個非常直接的資料建模步驟。此外,您的 DSL 會獲得強大的 IDE - 儘管您確實必須花一些時間定義該編輯器。產生器仍然是您必須做的事情,而我的感覺是它並未比以往容易多少。但為一個良好且簡單的 DSL 建立產生器是練習中最簡單的部分之一。
語言工作台的第二個大優點是您獲得了符號整合。能夠採用類似 Excel 的公式語言,並將其插入您自己的專業語言中,這非常棒。就像能夠在一個語言中變更符號,並讓這些變更在整個系統中產生漣漪效應一樣,這是一個使用語言工作台時可以考慮的合理做法(我不確定是否有任何語言工作台可以做到這一點)。
重構的這個問題是語言工作台中的一個大問題。當我解釋使用語言工作台時,很容易陷入將其描述為「先定義 DSL,然後使用它建立東西」的陷阱。如果您讀過我過去寫過的大量內容,這個概念應該會觸發許多警鈴。我是演化設計的忠實擁護者 - 在這個脈絡中,這表示您需要能夠同時演化 DSL 和任何在 DSL 中建立的程式碼。這是一個難題,但 Intentional 在開發初期就已經承認了這一點。現在判斷在成熟的語言工作台中,同時演化 DSL 及其使用情況的效果如何還為時過早 - 但缺乏這種能力將會對它們造成很大的負面影響。
我認為語言工作台最大的中期問題是供應商鎖定的風險。定義架構、編輯器和產生器的三人組沒有標準。一旦你在語言工作台中定義一種語言,你就會被綁定到那個語言工作台。不同的語言工作台之間沒有交換標準 - 如果你想變更語言工作台,這會讓你重新實作三人組。隨著時間的推移,我們可能會看到某種特殊儲存表示法,旨在交換 DSL - 一種交換表示法。但除非這裡出現一個強大的故事,否則供應商鎖定仍然是一個很大的風險。(MDA 聲稱提供了一個答案,但它充其量只是部分。)
如果將語言工作台視為幫助你產生來源的工具,這可以減輕此問題。這方面的範例是使用語言工作台來控制所有 Java XML 組態檔。如果發生最糟的情況,你必須放棄語言工作台,那麼你仍然有產生的組態檔。只要你注意乾淨的產生檔,你甚至可能不會比自己撰寫它們更糟。即使對於更深入的功能,你仍然可以產生結構良好的 Java 程式碼。這在某種程度上減輕了風險,至少你不會完全陷入困境。但供應商鎖定仍然是需要考慮的事情。
關於工具的這個問題是遠離文字檔作為來源的後果之一。出現了其他問題 - 我們已經設法用文字解決的問題,但現在必須重新思考抽象表示法的核心角色。在我的清單中,版本控制很重要。我們知道如何對文字來源進行有效的版本控制,並具備良好的差異和合併功能。為了有效,語言工作台需要能夠提供抽象表示法本身的差異和合併。理論上,這應該是可解決的,並開啟了真正的語義差異的機會(其中重新命名符號被理解為該動作,而不仅仅是你必須從其結果中推論出來的東西,就像你對文字所做的那樣。)Intentional 似乎有一個很好的解決方案,但我們尚未在實務中嘗試過。
回到積極的觀點,自訂語言和編輯器的結合可能最終為非程式設計人員開啟了編輯 DSL 的途徑。此外,符號整合消除了使用者程式碼和核心程式不同步的問題。編輯器的使用可能是幫助打破 COBOL 推論的最大工具 - 提供自訂使用者互動的工具環境。
讓領域專家更直接地參與開發工作的這個承諾可能是語言工作台承諾中最誘人的部分。一次又一次地,我們看到無論我們程式設計人員使用什麼工具來提高我們的生產力,都有一種感覺,我們正在最佳化閒置迴圈。在我拜訪的大多數專案中,最大的問題是開發人員與業務之間的溝通。如果運作良好,那麼即使使用二流技術,你也可以取得進展。如果這種關係破裂,那麼即使 Smalltalk 也救不了你。
大多數面向語言程式設計的支持者都談到更多地涉及領域專家。事實上,我甚至聽說過秘書們在 Lisp 的內部 DSL 中快樂地編寫程式。然而,大多數時候,這些努力都沒有真正成功。透過結合專注的外部 DSL 與精密的編輯器和開發環境的優勢,我們也許終於可以開始解決這個問題。如果是這樣,優點將是巨大的。事實上,令人驚訝的是,這種使用者參與似乎是 Charles Simonyi 工作背後的主要驅動力,支撐著 Intentional Software 中大多數的決策。
這些工具最大的短期限制是成熟度。這些工具要達到開發人員的領先水準還需要一段時間。但我們知道這可能會快速改變,只要回顧一下十年前與現在的工具和語言選擇即可。
改變我們對 DSL 的概念
我在這篇文章中使用的範例實際上是 DSL 相當無趣的範例。我使用它們是因為它們容易討論和建構。但即使更複雜的協議 DSL 也相當傳統,很容易看出如何將其作為傳統的文字 DSL 來完成。許多人希望製作圖形 DSL,但即使這些 DSL 也無法發揮全部潛力。使用「語言」一詞最大的危險在於,它可能會讓人們錯過語言工作台真正能做什麼的重點。
當我與同事討論 OOPSLA 2004 時,最大的話題是喬納森·愛德華茲關於範例中心程式設計的一些示範。關鍵想法是一個編輯器,它不僅顯示程式碼,還顯示該程式碼中範例執行的結果。這個想法是,儘管我們操作的是抽象,但我們通常發現用具體案例來思考會更容易。這種傾向於範例是測試驅動開發吸引力很大的一部分,我認為它是 範例規格。
愛德華茲進一步將他的想法發展成一個名為 Subtext 的工具。Subtext 共享語言工作台的一些原則,特別是遠離文字原始碼的想法。雖然 Subtext 在支援新語言的輕鬆定義方面不太有趣,但它提供了對隨著語言工作台讓我們深入思考語言和工具的緊密交織而可能發展的想法的有趣見解。
事實上,這可能是語言工作台能夠避免 COBOL 推論的惡劣影響的最有力理由。正如我之前所說,我們不斷提出技術來賦予使用者作為外行程式設計師的能力,但經常失敗。讓我們考慮一項在讓外行程式設計師發揮作用方面真正成功的技術:試算表。
大多數程式設計師不會將試算表視為程式設計環境。然而,許多外行程式設計師使用它們建立了複雜的系統。試算表是一個迷人的程式設計環境,它建議外行程式設計工具可能需要具備的特徵
- 立即回饋,包括立即顯示範例計算的結果。
- 工具和語言的深度整合
- 沒有文字來源
- 不需要一直顯示所有資訊,公式僅在您編輯包含它們的儲存格時才可見,否則會顯示值。
試算表也很令人沮喪。它們缺乏結構鼓勵實驗,但我經常覺得更多的結構可以讓某些問題更容易處理。
因此,當我們想到語言工作台中使用的 DSL 時,我們應該減少思考我這裡展示的語言類型,或模型設計師所喜愛的圖形語言。相反地,我們應該思考像是下一代試算表之類的東西。
結論
我寫作此文章的主要目的是為您介紹語言工作台。至少我希望您現在已經了解足夠的資訊,以便在您的經理要求您用語言工作台取代整個程式設計環境時,您能應付自如。
在我看來,語言工作台提供兩個主要的優點。一是透過提供更好的工作工具來提升程式設計師的生產力。另一個是透過讓領域專家有更多機會直接貢獻開發基礎,來提升開發的生產力。這些優點是否會實際實現,只有時間才能證明。就我來看,我認為提升生產力比較有可能發生,但影響力較小。如果語言工作台對開發與領域專家之間的關係產生重大的影響,它可能會產生巨大的效果,但它必須克服 COBOL 推論才能成功。
我逐漸意識到,最有趣的事情可能是,一旦我們有了語言工作台的經驗,我們可能對 DSL 的樣貌幾乎沒有概念。到目前為止,我的思考仍然受到對文字和圖形語言的印象所限制。然而,編輯器和架構的交互作用開啟了與大多數人對外部 DSL 的想法截然不同的可能性。如果語言工作台符合他們的期望,十年後我們將回首過去,嘲笑我們現在認為 DSL 應該是什麼樣子。
正如我所指出的,語言工作台仍處於開發的非常早期階段。在我們能夠認真地測試它們之前,還需要幾年的時間。我不會對它們是否會如其擁護者所希望的那樣改變軟體開發的面貌做出預測。我不是一位科技未來主義者。我相信的是,語言工作台是我們視野邊緣最有趣的想法之一。如果它們確實發揮了潛力,它們肯定會對我們的專業產生巨大的影響。即使沒有,我懷疑它們也會帶來許多有趣的想法。
因此,我建議您持續關注此空間。這是一個有趣的領域,而且有足夠的生命力,足以在未來許多年間保持有趣。我很幸運能在最近幾個月對此領域有深入的了解,而且我打算繼續保持我的興趣一段時間。
進一步閱讀
我決定將進一步閱讀的參考資料放在我的 bliki 上。這樣可以更容易追蹤更新。
致謝
我要向我的 ThoughtWorker 同事 Matt Foemmel 致上最深的謝意。Matt 長期以來一直是 Thoughtworks 的關鍵工具開發者,而且不斷尋找方法來推動我們的開發工作。他從 2004 年初開始對意向式程式設計產生興趣,而我也從他的研究中受益良多。他去年積極參與 Intentional Software 的開發,這對我了解這個環境非常有幫助。
當我聽說我欽佩的幾個軟體工具公司之一正在這個領域工作時,我立刻產生了興趣。Sergey Dmitriev 就在波士頓離我不遠的地方,這讓情況變得更好了。Sergey 在開發 MPS 時,讓我得以接觸到這個工具。他和他的團隊採用了這個協議範例,並在 MPS 中實作它,這樣我就可以描述一些並非完全是空談的東西。Igor Alshannikov 在我遇到軟體在開發過程中不可避免的問題時幫助了我。
Intentional Software 在過去幾年一直非常低調,因為他們一直在開發自己的想法。Charles Simonyi 讓我得以接觸到他們的工具和計畫。我也得以與 Magnus Christerson 重新合作,他現在也在 Intentional。
就像 80 年代和 90 年代的許多英國人一樣,我從 Steve Cook 在那裡的 OO 社群領導中受益良多。從那時起,他幫助我度過了 UML 規範的難關,而且對於這篇文章,他在 Microsoft 的軟體工廠計畫中提供了非常有用的資訊。看到許多我認識多年的朋友參與這個計畫,這很有幫助:Keith Short、Jack Greenfield、Alan Wills 和 Stuart Kent 都提供了大量的資訊。
多虧了 Daniel Jackson 教授,我多次拜訪了麻省理工學院,並度過了愉快的時光。特別是他向我介紹了 Jonathon Edwards。這不是我第一次在第一次看到戲劇性的想法時無法真正理解它們,但我最終會學到的。
在 Thoughtworks 最棒的事情之一就是可以接觸到從事有趣工作的非常有才華的人。在這種情況下,能夠接觸到與 Intentional 工具密切合作的人非常有用:Matt Foemmel、Jeremy Stell-Smith 和 Jason Wadsworth。
說到 ThoughtWorkers 同事,Rebecca Parsons 和 Dave Rice 一直都是很好的智力共鳴板,對於讓我的思考保持在正軌上至關重要。
除了提供這種背景資訊來撰寫這些文章之外,我也收到了 Rebecca Parsons、Dave 'Bedarra' Thomas、Steve Cook、Jack Greenfield、Bill Caputo、Obie Fernandez、Magnus Christerson 和 Igor Alshannikov 對早期草稿的有用評論
感謝 Reuven Yagel、Dave Hoover 和 Ravi Mohan 發現並傳送錯字給我。
重大修訂
2005 年 6 月 12 日:首次發布。