
生產中的品質保證
2017 年 4 月 4 日

Rouan 是一位軟體工程師和技術領導人,協助打造傑出的團隊和高品質的軟體。他曾在金融服務、教育、休閒和能源等產業的各種技術堆疊中工作(包括擔任 Thoughtworks 的顧問)。他注重保持簡單、建立包容性的團隊,並撰寫他所學到的知識。
收集系統的營運資料是常見的作法,特別是表示系統負載和效能的指標,例如 CPU 和記憶體使用率。多年來,這些資料已用於協助支援系統的團隊,讓他們了解中斷何時發生或即將發生。例如,當事情變得緩慢時,可能會啟用程式碼分析器,以確定系統的哪個部分造成瓶頸,例如執行速度緩慢的資料庫查詢。
我觀察到最近的趨勢,將這種傳統營運監控的細緻度與系統品質的更廣泛觀點結合在一起。雖然營運資料是支援系統的必要部分,但收集有助於描繪整個系統是否如預期運作的資料也很有價值。我將「生產中的品質保證」定義為一種方法,讓團隊更密切地關注其生產系統的行為,以提升這些系統所服務功能的整體品質。
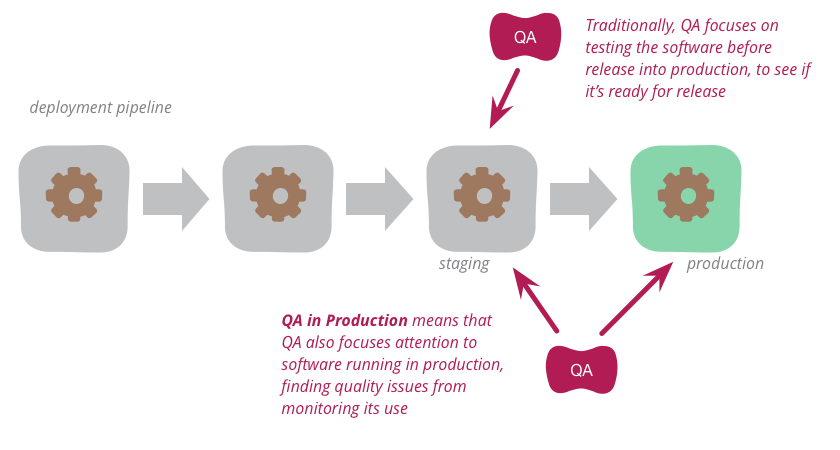
事情總會在生產中出錯,但這不一定是壞事。這是了解您的系統和它所互動的真實世界的一個機會。透過適當的生產監控工具和良好的持續交付管線,您可以建立一組回饋機制,幫助您在問題發生時找出問題並快速發布修正程式。採用生產品質保證 (Quality Assurance) 實務可以幫助您更深入地了解您的系統所面臨的實際問題,並學習新的方法來提升其品質。
收集生產資料
你可以收集許多關於你的系統的資料。我發現思考什麼對系統的成功至關重要,並讓它引導我的努力,非常有幫助。當我在此脈絡中談論成功時,我指的是支付帳單的那種類型。如果你的系統無法提供客戶付費或依賴的服務,那麼每秒處理數千個請求並無所謂。
關鍵成功指標
在 Tes,我花了一些時間研究教師用於求職的系統。我們的團隊認定為至關重要的指標之一,是教師的求職申請是否實際上已送達他們申請工作的學校。電子郵件是系統通知學校有新求職申請的主要方法。我們使用第三方服務來發送電子郵件,這表示這在我們正在處理的系統界限之外。正如我們所了解的,在嘗試發送電子郵件時,可能會出錯。即使電子郵件地址看起來有效,但仍可能無效,信箱已滿,而且人們有外出辦公室訊息,這可能會讓他們看起來即使收到電子郵件,但沒有收到。這些現實世界的複雜情況幾乎無法預測,也很難測試。我們所做的,是從生產中發生的事情中學習。以下是我們對系統品質的理解和反應如何演變的摘要
- 我們開始計算提交的求職申請數量和我們發送的電子郵件數量(透過將簡單的指標發送到指標伺服器)。我們設定一個警示,以便在這些數字不同步時收到通知。
- 我們設定另一個警示,讓我們知道如果我們的發送電子郵件微服務無法處理發送電子郵件的請求。
- 結果發現這經常發生。我們的警示會觸發,但原因不明。我們查看了記錄,但找不到任何有用的資訊,因此我們著手改善我們的記錄。特別是,我們記錄了我們從第三方電子郵件供應商收到的錯誤的更多詳細資訊。
- 從記錄中,我們瞭解了不同類型的回應 - 有些表示儘管有錯誤,但該人可能收到了電子郵件(例如,外出辦公室回覆),有些(例如 DNS 問題)可能是暫時的,而有些錯誤表示電子郵件永遠不會送達。一些文件和錯誤訊息令人困惑,因此我們使用未發送電子郵件的範例與學校交談,以找出哪些電子郵件實際上已收到,哪些沒有。
- 我們注意到我們的發送電子郵件程式碼對於收到的錯誤過於嚴格,因此我們放寬了一點。(當我們知道錯誤回應表示學校可能已收到郵件時,我們停止記錄錯誤。)
- 我們注意到許多問題是因錯誤擷取電子郵件地址所致。在這些情況下,我們查看了記錄,並與我們的客戶服務團隊交談。「嗨。我們嘗試將電子郵件發送到 example@example.com,但無法傳遞。請與學校確認電子郵件地址是否正確?」
- 一段時間以來,客戶服務團隊會在電子郵件地址修復時通知我們,而我們會手動觸發電子郵件重新發送,使用我們在網路服務上建立的端點。一段時間後,我們開始在電子郵件地址更新時自動重新發送電子郵件。(我們在訊息佇列中傾聽工作資訊的更新。)
- 我們仍然必須做很多工作才能透過電子郵件通知客戶服務團隊無法運作的電子郵件地址,因此我們開始自動發送這些電子郵件。
- 有了這個自動修復系統,我們停止對每封失敗的電子郵件發出警示,因為大多數電子郵件都已修復。現在,我們只會在有不良電子郵件地址未被發現且在特定時間內未修復時收到警示。
Tes 的工作申請系統的另一個關鍵使用量指標是老師是否實際申請工作。他們是否在工作申請表單的結尾按下「提交」按鈕,還是有某些事情阻止他們這樣做?可能是小型 CSS 或 JavaScript 函式庫變更導致「提交」按鈕在特定瀏覽器中顯示或行為不正確。老師提交申請的頻率下降可能是問題的徵兆,因此如果發生類似情況,我們會收到通知。我們還會注意服務傳回的 HTTP 500 回應代碼。我們真的希望老師能夠申請工作,所以如果任何事情阻止他們,我們都想了解。我們對此非常吹毛求疵,因此我們盡一切努力始終向他們顯示工作申請表單。如果在取得顯示表單所需資料時出現問題,我們會確保記錄錯誤,然後盡力讓老師儘管有問題也能申請。我們查看這些日誌(我們的警示系統會提醒我們),並處理任何出錯的地方。我們認為,我們寧願修復不良資料或系統狀態,也不願讓潛在候選人失望。
我在這些範例中提到了幾種不同的技術來收集生產資料。讓我們更詳細地探討它們。
記錄
記錄是收集系統資料非常有效的方法,前提是您在記錄資料的方式上小心謹慎。記錄不再只是讓系統管理員逐行檢視找出問題所在的长文字檔。如果您的記錄堆疊是以可搜尋性為考量而建置,它可以為您提供有關系統的寶貴即時資料。
請記住,記錄不限於記錄技術資訊。您還可以記錄有價值的使用量資料。我花了一些時間在一個具有出色記錄堆疊的線上銀行網站上工作,我們能夠使用記錄來確定我們發布的新功能的普及程度。我們發布了讓使用者調整其線上付款限額的功能,並且可以快速看到此功能被廣泛採用。我們還可以收集一些有趣的資料,例如人們調整其限額的頻率和調整幅度。如果您執行這種記錄,請記住注意使用者的隱私,並且僅記錄您真正需要的資料。
一種達成更具可搜尋性記錄檔的方法是使用記錄檔轉發。這是透過在伺服器上執行一些軟體來達成,該軟體會定期將您的記錄檔資料傳送至另一項服務,通常是針對全文搜尋最佳化的資料庫,例如 ElasticSearch 或 Apache Solr。透過在這個資料庫上建立查詢,便能彙整視覺化資料,顯示出隨著時間推移的彙總資訊和趨勢。對於我提到的銀行網站,便能繪製出顯示有趣商業指標的圖表,例如轉帳金額,以及較技術性的資訊,例如使用者用哪些瀏覽器和裝置進行銀行作業。也能搜尋問題並深入探究個別記錄檔條目,這是一種檢視問題非常有效的方式。
另一種方法是採用所謂的結構化記錄,我在待過的一家保險公司使用過這種方法。不要記錄類似
There was an invalidInputFormat error capturing data for user 54321
您可以記錄
There was an error capturing data for userId={54321},
errorType={invalidInputFormat}
透過在個別記錄檔條目中加入一點額外結構,就能更輕鬆地搜尋資訊。有一些強大的工具可用(例如 Splunk),可以根據這些類型的記錄檔建立索引,並提供最佳化的搜尋、彙總和視覺化功能。如果您使用的是 ElasticSearch 等工具,也可以以 JSON 格式記錄結構化資料。
記錄檔現在可能以更精密的型式使用,但別忘了善用已獲證實的指定記錄檔層級的作法,例如 ERROR、WARN 和 INFO。以這種方式標示每個記錄檔條目的嚴重性,在支援系統時非常有幫助,因為這會改善記錄檔的訊號雜訊比。支援系統的人員應該能夠檢視一天的記錄檔,並能夠過濾只查看錯誤(理想上這些錯誤不應太多)。這樣一來,他們就能確保沒有任何錯誤發生而未被發現。
指標
除了在記錄檔中記錄資訊之外,還有像 statsd 這樣的工具可用,讓您能夠計算系統事件和彙總系統資料。記錄檔對於收集非常具體的資訊很有用,這種方法可以透過提供彙總資訊的收集方式來補充記錄。在 Tes,我們一直使用 statsd 將資料傳送至 DataDog。例如,我們會定期傳送每個 Docker 容器目前的 CPU 負載和記憶體使用量,以便我們注意到效能問題。同樣地,我想強調,您應考慮擷取商業指標和技術指標。
對於我先前提到的求職系統,我們會針對常見的錯誤傳送指標。為了傳送電子郵件,我們會透過訊息佇列傳送訊息到共用微服務。如果該服務無法處理訊息,訊息就會進入死信佇列,而我們會傳送指標來表示我們的其中一則訊息已進入該佇列。如果我們收到任何此指標的執行個體,團隊就會收到警示,表示有問題,應該進行調查。接著,我們可以在電子郵件服務中搜尋發生在相同時間範圍內的錯誤記錄,以找出未寄送電子郵件到學校的求職申請,以及錯誤訊息為何。
我們也會收集常見的使用率指標,例如應用程式何時啟動、更新或提交。我們可以使用這些指標來查看提交的應用程式百分比,並讓我們比較不同類型的申請表單。這些統計資料有助於我們找出趨勢、瞭解系統,並回應潛在問題。值得注意的是,這些工具的目的是收集足夠的資料以提供有用的統計資料,因此通常無法依賴其精確性。
API
如果上述技術一開始看起來很繁瑣,請不要灰心。最簡單的系統資料搜尋位置就是您已在使用的工具的 API。許多效能監控、網路分析、正常運作時間監控和 IaaS 工具都提供 API,可以查詢這些 API 以取得有關系統效能和使用情況的資料。
從生產資料中學習
警示
如果您收集的所有資料都沒有人做出反應,那麼這些資料就毫無用處,因此建立某種警示系統非常重要。當問題出現在製作過程中,您會希望成為第一個知道的人,這樣才能將對使用者的影響降到最低。您需要具備能夠監控您的記錄資料或指標,並具備向您發送警示功能的軟體。這些警示可能會透過電子郵件、簡訊或您團隊使用的聊天室通知傳送。然後,您需要設定一些警示閾值,也就是您希望收到通知的規則。在求職範例中,當我們無法向學校發送任何電子郵件時,我們會收到通知(也就是 1 的閾值)。這是因為這類錯誤應該很少見,而且發生時應該受到重視。為了查看教師放棄申請的頻率,我們的警示需要與其他資料相關。當一天的求職申請數目低於某個數字,或與目前的趨勢明顯不同時,我們會收到警示通知,表示可能有些事情阻礙教師申請。
重要的是要指出,警示不只是讓您知道出了什麼問題。良好的警示會在出問題之前讓您知道。您對系統了解越多,您就越能設定出能指出即將發生的問題的監控類型。例如,您可能知道某個伺服器上使用超過 64% 的記憶體通常表示有記憶體外洩,而且很快就會用完資源。如果您及時收到警示,您可以採取步驟來解決記憶體問題或讓備用伺服器上線。精密的設定甚至可能包含一些自我修復機制。
在您的警示中擁有良好的信號雜訊比至關重要。如果您的團隊收到太多警示,或收到太多誤報警示,那麼警示就會變成雜訊,會被忽略,而且重要的問題就會被錯過。
儀表板
儀表板是讓資料更容易使用的常見方式。這些通常包含一系列圖表(例如,所有伺服器上的 CPU 使用率)或大型個別數字(例如,今天的求職申請數)。這些視覺化的資料可能來自各種資料來源,因此您使用的儀表板工具可能需要執行一些資料處理或彙總。否則,您可以使用許多工具現在提供的內建儀表板。在您團隊的工作區域的大螢幕上顯示這些視覺化非常有用,這樣您才能一目了然地看到趨勢和狀態。如果您的團隊遠端工作,請確保儀表板的連結容易找到。人類具有發現趨勢和注意到奇怪現象的靈敏能力,因此,如果您的團隊習慣查看資料,您可能會發現問題,而無需投資於維護複雜的資料處理演算法。
組織越來越常以狀態頁面的形式向其使用者提供一些基本的系統統計資料。這有助於讓使用者在問題發生時了解問題,並向他們保證問題正在處理中。請參閱 GitHub 的狀態頁面 以取得範例,或查看 我們在 Tes 提供的狀態頁面。
根植於現實的品質保證方法
當大多數人想到 QA 時,他們想到的是測試,但要掌握系統品質,記住 QA 的其他面向很重要。了解系統並分析最大的品質問題是一個經常被忽略的面向。
測試只能幫助你處理你已經知道的情境。測試很適合找出你預期會發生的缺陷,但許多生產缺陷都是驚喜。使用者、網路、瀏覽器和裝置極度多元且高度不可預測。測試根本無法涵蓋所有情境。測試是確保系統按預期運作的好方法,但它們無法告訴你預期的行為是否正確。良好的生產監控可以提供關於你無法預見的情境的寶貴回饋,並幫助你相應調整系統的行為。QA 就像學習系統的正確行為一樣,也是關於保護該行為,這是一個經常被忽略的面向。
測試需要證明其價值
測試是一種有價值的做法,為許多組織節省了大量時間和金錢,但值得考慮的是,測試確實有成本。有些測試容易維護和使用,但其他測試需要更多努力。例如,UI 或基於瀏覽器的測試已知會不穩定(它們會產生大量假性失敗)、脆弱(隨著 UI 的演進,它們需要大量維護)且經常依賴不可靠的下游系統。對於某些組織,尤其是依賴專有硬體或軟體的組織,效能測試很昂貴。與其進行 UI 測試來檢查某些功能是否運作,你可以進行監控以確保關鍵指標不會低於特定閾值。與其有一套測試來將功能置於模擬負載下,你可以使用生產中的指標來指出系統的平均回應時間。
然後,團隊可以在他們用於這些測試的時間內繼續提供有價值的網站改進,並且如果系統有任何問題,他們將會收到通知。如果真的出錯,他們可以調查並補救失敗。
您準備好採用生產品質保證實務了嗎?
簡短的答案是肯定的。大多數團隊會透過更注意生產中發生的事情來深入了解他們正在建立的系統,並且應該很快就能看到設定一些基本儀表板和警示的價值。
簡短答案的問題在於,生產中的 QA 包括你可以用本文中描述的技術替換一些你的生產前品質實務的概念。在實務上,在沒有啟用一些 持續傳遞實務的情況下,很難支援這種轉變。
在取代一些傳統的預生產 QA 技術之前,您應該建立測試文化和相關的測試技能。當您嘗試修正您在生產中發現的問題時,擁有一組穩固的自動化測試非常重要,讓您確信自己沒有破壞其他東西。如果沒有適當的測試類型,您就有可能陷入無止盡的打地鼠遊戲。
依賴生產資料來找出問題表示修正這些問題非常耗時。一旦您解決了問題或實施了替代方案,您需要能夠快速將變更套用到生產環境。您需要有自動化部署才能做到這一點,否則您就有可能發生手動錯誤,讓情況變得更糟。
找到適當的平衡
用監控取代昂貴的測試可以讓組織動作更迅速,但每個組織都需要在這項速度和在發布到生產環境之前確定(或盡可能確定)事情運作正常之間取得平衡。這種平衡將在很大程度上取決於相關的系統。例如,Facebook 開發團隊[1]能夠放棄一些測試,因為他們有良好的回饋迴路,讓他們知道他們是否在生產環境中破壞了某個東西,並且他們可以快速發布修正程式。如果出了問題,導致某人無法檢視照片或錯過朋友的生日,這並非世界末日。在另一個極端,一家編寫醫療裝置程式碼的公司有很高的風險和非常緩慢的回饋迴路,因此他們需要在這些裝置使用之前盡可能確定事情運作正常。大多數系統介於這兩者之間。
對於任何系統,都會有難以復原的問題。對於這些情況,您需要在預生產測試中投入更多資源,以防止在生產中發生意外。在生產中發生的每個問題都會有相關的成本,因此決定您需要多麼謹慎非常重要。等到問題發生在生產環境中再處理的好處是,您知道這值得修正,因為它真的發生了。
有些組織已經在生產環境中進行所有測試,但完全依賴生產環境中的問題或測試來了解系統品質是反模式。它忽略了適當的 QA 需要各種品質實務,而生產中的 QA 只是其中之一。如果您在流程中尋找的只是一個可以說「是的,看起來不錯」的點,您將無法學到太多讓系統更好的方法。
找到預生產和生產品質實務的適當平衡可以幫助您對系統品質有更實際且全面的了解。要記住的最重要的事情是,我們可以透過密切注意生產環境中發生的事情學到很多,而且我們可以使用所學到的知識來打造品質更好的東西。
註腳
1: Facebook 以前有「快速行動,勇於破壞」的座右銘。請參閱這則xkcd 漫畫,了解為什麼這並非對每個人都適用的正確方法。
重大修訂
2017 年 4 月 4 日:首次發布