
使用迴圈和集合管線進行重構
迴圈是處理集合的傳統方式,但隨著程式語言中一級函式的採用率提高,集合管線 成為一個有吸引力的替代方案。在本文中,我將透過一系列的小範例,探討將迴圈重構成集合管線。
2015 年 7 月 14 日

程式設計中的一項常見任務是處理物件清單。大多數程式設計師會自然地使用迴圈來執行此任務,因為這是我們在撰寫第一個程式時所學習的基本控制結構之一。但迴圈並非表示清單處理的唯一方式,近年來,越來越多的人開始使用另一種方法,我稱之為集合管線。這種風格通常被視為函式程式設計的一部分,但我曾在 Smalltalk 中大量使用它。由於物件導向語言支援 lambda 和使一級函式更容易編寫的函式庫,因此集合管線成為一個有吸引力的選擇。
將簡單迴圈重構成管線
我將從迴圈的簡單範例開始,並展示將迴圈重構成集合管線的基本方法。
讓我們假設我們有一個作者清單,每個作者都有以下資料結構。
類別 Author...
public string Name { get; set; }
public string TwitterHandle { get; set;}
public string Company { get; set;}
此範例使用 C#
以下是迴圈。
類別 Author...
static public IEnumerable<String> TwitterHandles(IEnumerable<Author> authors, string company) {
var result = new List<String> ();
foreach (Author a in authors) {
if (a.Company == company) {
var handle = a.TwitterHandle;
if (handle != null)
result.Add(handle);
}
}
return result;
}
將迴圈重構為集合管線的第一步是對迴圈集合套用
類別 Author...
static public IEnumerable<String> TwitterHandles(IEnumerable<Author> authors, string company) {
var result = new List<String> ();
var loopStart = authors;
foreach (Author a in loopStart) {
if (a.Company == company) {
var handle = a.TwitterHandle;
if (handle != null)
result.Add(handle);
}
}
return result;
}
此變數提供給我管線作業的起點。目前我沒有為它取一個好名字,因此我會使用一個目前有意義的名字,預計稍後會重新命名。
然後我開始檢視迴圈中的行為片段。我看到的第一個項目是條件檢查,我可以使用 篩選作業 將其移至管線。
類別 Author...
static public IEnumerable<String> TwitterHandles(IEnumerable<Author> authors, string company) {
var result = new List<String> ();
var loopStart = authors
.Where(a => a.Company == company);
foreach (Author a in loopStart) {
if (a.Company == company) {
var handle = a.TwitterHandle;
if (handle != null)
result.Add(handle);
}
}
return result;
}
我看到迴圈的下一部分對 Twitter 處理程序進行操作,而不是對作者進行操作,因此我可以使用 對應作業 [2]。
類別 Author...
static public IEnumerable<String> TwitterHandles(IEnumerable<Author> authors, string company) {
var result = new List<String> ();
var loopStart = authors
.Where(a => a.Company == company)
.Select(a => a.TwitterHandle);
foreach (string handle in loopStart) {
var handle = a.TwitterHandle;
if (handle != null)
result.Add(handle);
}
return result;
}
迴圈中的下一部分是另一個條件,我同樣可以將其移至篩選作業。
類別 Author...
static public IEnumerable<String> TwitterHandles(IEnumerable<Author> authors, string company) {
var result = new List<String> ();
var loopStart = authors
.Where(a => a.Company == company)
.Select(a => a.TwitterHandle)
.Where (h => h != null);
foreach (string handle in loopStart) {
if (handle != null)
result.Add(handle);
}
return result;
}
現在迴圈所做的就是將其迴圈集合中的所有內容新增至結果集合,因此我可以移除迴圈並只傳回管線結果。
類別 Author...
static public IEnumerable<String> TwitterHandles(IEnumerable<Author> authors, string company) {
var result = new List<String> ();
return authors
.Where(a => a.Company == company)
.Select(a => a.TwitterHandle)
.Where (h => h != null);
foreach (string handle in loopStart) {
result.Add(handle);
}
return result;
}
以下是程式碼的最終狀態
類別 Author...
static public IEnumerable<String> TwitterHandles(IEnumerable<Author> authors, string company) {
return authors
.Where(a => a.Company == company)
.Select(a => a.TwitterHandle)
.Where (h => h != null);
}
我喜歡集合管線的原因是我可以看到邏輯流程,因為清單中的元素會通過管線。對我來說,它讀起來非常接近於我定義迴圈結果的方式「選擇作者,選擇有公司的作者,並取得他們的 Twitter 處理程序,移除任何空值處理程序」。
此外,這種程式碼樣式即使在語法和管線運算子名稱不同的不同語言中也很熟悉。 [3]
Java
public List<String> twitterHandles(List<Author> authors, String company) {
return authors.stream()
.filter(a -> a.getCompany().equals(company))
.map(a -> a.getTwitterHandle())
.filter(h -> null != h)
.collect(toList());
}
Ruby
def twitter_handles authors, company
authors
.select {|a| company == a.company}
.map {|a| a.twitter_handle}
.reject {|h| h.nil?}
end
雖然這符合其他範例,但我會將最後的 reject 替換為 compact
Clojure
(defn twitter-handles [authors company]
(->> authors
(filter #(= company (:company %)))
(map :twitter-handle)
(remove nil?)))
F#
let twitterHandles (authors : seq<Author>, company : string) =
authors
|> Seq.filter(fun a -> a.Company = company)
|> Seq.map(fun a -> a.TwitterHandle)
|> Seq.choose (fun h -> h)
同樣地,如果我不擔心與其他範例的結構相符,我會將對應和選擇合併為一個步驟
我發現一旦我習慣以管線的方式思考,即使在不熟悉的語言中,我也可以快速套用它們。由於基本方法相同,因此即使從不熟悉的語法和函式名稱翻譯也很容易。
在管線中重構並轉為理解
一旦你將一些行為表示為管線,你可以透過重新排序管線中的步驟來進行可能的重構。其中一個動作是,如果你有一個對應後接一個篩選,你通常可以像這樣將篩選移到對應之前。
類別 Author...
static public IEnumerable<String> TwitterHandles(IEnumerable<Author> authors, string company) {
return authors
.Where(a => a.Company == company)
.Where (a => a.TwitterHandle != null)
.Select(a => a.TwitterHandle);
}
當你擁有兩個相鄰的篩選時,你可以使用連接詞將它們合併。 [4]
類別 Author...
static public IEnumerable<String> TwitterHandles(IEnumerable<Author> authors, string company) {
return authors
.Where(a => a.Company == company && a.TwitterHandle != null)
.Select(a => a.TwitterHandle);
}
一旦我有一個像這樣簡單的篩選和對應的 C# 集合管線,我就可以用 Linq 表示式取代它
類別 Author...
static public IEnumerable<String> TwitterHandles(IEnumerable<Author> authors, string company) {
return from a in authors where a.Company == company && a.TwitterHandle != null select a.TwitterHandle;
}
我認為 Linq 表達式是一種 清單理解 的形式,類似地,您可以使用支援清單理解的任何語言來執行類似的事情。您偏好清單理解形式或管道形式是一個品味問題(我偏好管道)。一般而言,管道功能更強大,因為您無法將所有管道重構為理解。
巢狀迴圈 - 閱讀書籍的人
舉第二個範例來說,我將重構一個簡單的雙重巢狀迴圈。我假設我有一個線上系統,讓讀者可以閱讀書籍。我有一個資料服務,會告訴我每個讀者在特定一天讀了哪些書。此服務會傳回一個雜湊,其金鑰是讀者識別碼,而值是書籍識別碼的集合
介面 DataService…
Map<String, Collection<String>> getBooksReadOn(Date date);
對於這個範例,我將切換到 Java,因為我厭倦了第一個字母大寫的方法名稱
以下是迴圈
public Set<String> getReadersOfBooks(Collection<String> readers, Collection<String> books, Date date) {
Set<String> result = new HashSet<>();
Map<String, Collection<String>> data = dataService.getBooksReadOn(date);
for (Map.Entry<String, Collection<String>> e : data.entrySet()) {
for (String bookId : books) {
if (e.getValue().contains(bookId) && readers.contains(e.getKey())) {
result.add(e.getKey());
}
}
}
return result;
}
我將使用我通常的第一個步驟,也就是將
public Set<String> getReadersOfBooks(Collection<String> readers, Collection<String> books, Date date) {
Set<String> result = new HashSet<>();
Map<String, Collection<String>> data = dataService.getBooksReadOn(date);
final Set<Map.Entry<String, Collection<String>>> entries = data.entrySet();
for (Map.Entry<String, Collection<String>> e : entries) {
for (String bookId : books) {
if (e.getValue().contains(bookId) && readers.contains(e.getKey())) {
result.add(e.getKey());
}
}
}
return result;
}
這樣的動作讓我非常慶幸 IntelliJ 的自動化重構讓我免於輸入那個複雜的類型表達式。
一旦我將初始集合放入變數中,我就可以處理迴圈行為的元素。所有工作都在條件式內進行,因此我將從條件式的第二個子句開始,並將其邏輯移至 篩選器。
public Set<String> getReadersOfBooks(Collection<String> readers, Collection<String> books, Date date) {
Set<String> result = new HashSet<>();
Map<String, Collection<String>> data = dataService.getBooksReadOn(date);
final Set<Map.Entry<String, Collection<String>>> entries = data.entrySet().stream()
.filter(e -> readers.contains(e.getKey()))
.collect(Collectors.toSet());
for (Map.Entry<String, Collection<String>> e : entries) {
for (String bookId : books) {
if (e.getValue().contains(bookId) && readers.contains(e.getKey()))) {
result.add(e.getKey());
}
}
}
return result;
}
使用 Java 的串流函式庫,管道必須以終端(例如收集器)結束
另一個子句較難移動,因為它會參照內部迴圈變數。這個子句會測試,看看映射條目的值是否包含方法參數中的書籍清單中也包含的任何書籍。我可以透過使用集合交集來執行此操作。Java 核心類別不包含集合交集方法。我可以透過使用 Java 的其中一個常見集合導向附加元件(例如 Guava 或 Apache Commons)來完成。由於這是一個簡單的教學範例,我將撰寫一個粗糙的實作。
類別 Utils...
public static <T> Set<T> intersection (Collection<T> a, Collection<T> b) {
Set<T> result = new HashSet<T>(a);
result.retainAll(b);
return result;
}
這在這裡有效,但對於任何實質專案,我都會使用一個常見函式庫。
現在我可以將子句從迴圈移至管道。
public Set<String> getReadersOfBooks(Collection<String> readers, Collection<String> books, Date date) {
Set<String> result = new HashSet<>();
Map<String, Collection<String>> data = dataService.getBooksReadOn(date);
final Set<Map.Entry<String, Collection<String>>> entries = data.entrySet().stream()
.filter(e -> readers.contains(e.getKey()))
.filter(e -> !Utils.intersection(e.getValue(), books).isEmpty())
.collect(Collectors.toSet());
for (Map.Entry<String, Collection<String>> e : entries) {
for (String bookId : books) {
if (e.getValue().contains(bookId) ) {
result.add(e.getKey());
}
}
}
return result;
}
現在迴圈所做的就是傳回映射條目的金鑰,因此我可以透過將 映射作業 新增至管道來終止迴圈的其餘部分
public Set<String> getReadersOfBooks(Collection<String> readers, Collection<String> books, Date date) {
Set<String> result = new HashSet<>();
Map<String, Collection<String>> data = dataService.getBooksReadOn(date);
result = data.entrySet().stream()
.filter(e -> readers.contains(e.getKey()))
.filter(e -> !Utils.intersection(e.getValue(), books).isEmpty())
.map(e -> e.getKey())
.collect(Collectors.toSet());
for (Map.Entry<String, Collection<String>> e : entries) {
for (String bookId : books) {
result.add(e.getKey());
}
}
return result;
}
然後我可以在 result 上使用 內嵌暫存。
public Set<String> getReadersOfBooks(Collection<String> readers, Collection<String> books, Date date) {
Set<String> result = new HashSet<>();
Map<String, Collection<String>> data = dataService.getBooksReadOn(date);
return data.entrySet().stream()
.filter(e -> readers.contains(e.getKey()))
.filter(e -> !Utils.intersection(e.getValue(), books).isEmpty())
.map(e -> e.getKey())
.collect(Collectors.toSet());
return result;
}
看到交集的使用,我發現它相當複雜,我必須在閱讀時找出它的作用,這表示我應該將它抽取出來。[5]
類別 Utils...
public static <T> boolean hasIntersection(Collection<T> a, Collection<T> b) {
return !intersection(a,b).isEmpty();
}
類別 Service...
public Set<String> getReadersOfBooks(Collection<String> readers, Collection<String> books, Date date) {
Map<String, Collection<String>> data = dataService.getBooksReadOn(date);
return data.entrySet().stream()
.filter(e -> readers.contains(e.getKey()))
.filter(e -> Utils.hasIntersection(e.getValue(), books))
.map(e -> e.getKey())
.collect(Collectors.toSet());
}
當你需要執行類似這種操作時,物件導向方法會處於劣勢。在物件上的靜態公用程式方法和一般方法之間切換很麻煩。有些語言有辦法讓它讀起來像串流類別上的方法,但我沒有 Java 中的選項。
儘管有這個問題,我仍然覺得管線版本比較容易理解。我可以將篩選器組合成單一連接,但我通常覺得把每個篩選器當成單一元素比較容易理解。
設備產品
下一個範例使用一些簡單的準則來標記特定區域的優先設備。為了了解它的作用,我需要說明網域模型。我們有一個組織在不同區域提供設備。當你要求一些設備時,你可能會取得你想要的東西,但通常你會得到一個替代品,它幾乎可以滿足你的需求,但可能不太好。舉一個相當牽強的例子:你在波士頓,想要一台除雪機,但如果商店裡沒有,你可能會得到一把雪鏟。然而,如果你在邁阿密,他們甚至不提供除雪機,所以你只能得到雪鏟。資料模型透過三個類別擷取這個資料。
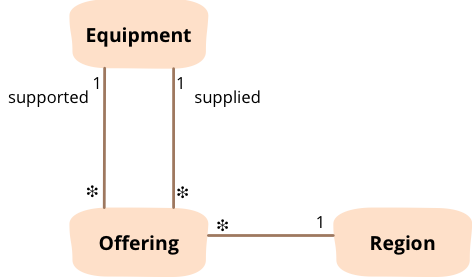
圖 1:每個提供實例都表示特定類型的設備在區域中提供,以支援對某種類型設備的需求。
因此我們可能會看到像這樣的資料
products: ['snow-blower', 'snow-shovel']
regions: ['boston', 'miami']
offerings:
- {region: 'boston', supported: 'snow-blower', supplied: 'snow-blower'}
- {region: 'boston', supported: 'snow-blower', supplied: 'snow-shovel'}
- {region: 'miami', supported: 'snow-blower', supplied: 'snow-shovel'}
我們要查看的程式碼是一些將這些提供標記為優先的程式碼,表示這個提供是區域中某個設備的優先提供。
類別 Service...
var checkedRegions = new HashSet<Region>();
foreach (Offering o1 in equipment.AllOfferings()) {
Region r = o1.Region;
if (checkedRegions.Contains(r)) {
continue;
}
Offering possPref = null;
foreach(var o2 in equipment.AllOfferings(r)) {
if (o2.isPreferred) {
possPref = o2;
break;
}
else {
if (o2.isMatch || possPref == null) {
possPref = o2;
}
}
}
possPref.isPreferred = true;
checkedRegions.Add(r);
}
這個範例使用 C#,因為我是個反覆無常的人。
我懷疑這個迴圈執行的邏輯很容易理解,透過重構它,我希望可以浮現那個邏輯。
我的第一步是從外迴圈開始,並將
類別 Service...
var loopStart = equipment.AllOfferings(); var checkedRegions = new HashSet<Region>(); foreach (Offering o1 in loopStart) { Region r = o1.Region; if (checkedRegions.Contains(r)) { continue; } Offering possPref = null; foreach(var o2 in equipment.AllOfferings(r)) { if (o2.isPreferred) { possPref = o2; break; } else { if (o2.isMatch || possPref == null) { possPref = o2; } } } possPref.isPreferred = true; checkedRegions.Add(r); }
然後我查看迴圈的第一部分。它有一個控制變數 checkedRegions,迴圈使用它來追蹤它已經處理過的區域,以避免重複處理同一個區域。這是一個臭味,但它也表示迴圈變數 o1 只是取得區域 r 的踏腳石。我透過在編輯器中突顯 o1 來確認這一點。一旦我知道這一點,我就知道我可以使用map來簡化它。
類別 Service...
var loopStart = equipment.AllOfferings()
.Select(o => o.Region);
var checkedRegions = new HashSet<Region>();
foreach (Region r in loopStart) {
Region r = o1.Region;
if (checkedRegions.Contains(r)) {
continue;
}
Offering possPref = null;
foreach(var o2 in equipment.AllOfferings(r)) {
if (o2.isPreferred) {
possPref = o2;
break;
}
else {
if (o2.isMatch || possPref == null) {
possPref = o2;
}
}
}
possPref.isPreferred = true;
checkedRegions.Add(r);
}
現在我可以討論 checkedRegions 控制變數。迴圈使用它來避免重複處理區域。我還不清楚檢查區域是否為冪等,如果是的話,我可能會完全避免這個檢查(並衡量是否有顯著影響效能)。由於我不確定,所以我決定保留那個邏輯,特別是因為 避免重複使用管道很簡單。
類別 Service...
var loopStart = equipment.AllOfferings()
.Select(o => o.Region)
.Distinct();
var checkedRegions = new HashSet<Region>();
foreach (Region r in loopStart) {
if (checkedRegions.Contains(r)) {
continue;
}
Offering possPref = null;
foreach(var o2 in equipment.AllOfferings(r)) {
if (o2.isPreferred) {
possPref = o2;
break;
}
else {
if (o2.isMatch || possPref == null) {
possPref = o2;
}
}
}
possPref.isPreferred = true;
checkedRegions.Add(r);
}
下一步是確定 possPref 變數。我認為這將更容易作為自己的方法來處理,因此套用 提取方法
類別 Service...
var loopStart = equipment.AllOfferings()
.Select(o => o.Region)
.Distinct();
foreach (Region r in loopStart) {
var possPref = possiblePreference(equipment, r);
possPref.isPreferred = true;
}
static Offering possiblePreference(Equipment equipment, Region region) {
Offering possPref = null;
foreach (var o2 in equipment.AllOfferings(region)) {
if (o2.isPreferred) {
possPref = o2;
break;
}
else {
if (o2.isMatch || possPref == null) {
possPref = o2;
}
}
}
return possPref;
}
我將迴圈集合提取到一個變數中。
類別 Service...
static Offering possiblePreference(Equipment equipment, Region region) {
Offering possPref = null;
var allOfferings = equipment.AllOfferings(region);
foreach (var o2 in allOfferings) {
if (o2.isPreferred) {
possPref = o2;
break;
}
else {
if (o2.isMatch || possPref == null) {
possPref = o2;
}
}
}
return possPref;
}
由於迴圈現在在它自己的函式中,我可以使用回傳而不是中斷。
類別 Service...
static Offering possiblePreference(Equipment equipment, Region region) {
Offering possPref = null;
var allOfferings = equipment.AllOfferings(region);
foreach (var o2 in allOfferings) {
if (o2.isPreferred) {
return o2;
break;
}
else {
if (o2.isMatch || possPref == null) {
possPref = o2;
}
}
}
return possPref;
}
第一個條件是尋找第一個通過條件式(如果有)的提供。那是偵測操作的工作(在 C# 中稱為 First。)[6]
類別 Service...
static Offering possiblePreference(Equipment equipment, Region region) {
Offering possPref = null;
var allOfferings = equipment.AllOfferings(region);
possPref = allOfferings.FirstOrDefault(o => o.isPreferred);
if (null != possPref) return possPref;
foreach (var o2 in allOfferings) {
if (o2.isPreferred) {
return o2;
}
else {
if (o2.isMatch || possPref == null) {
possPref = o2;
}
}
}
return possPref;
}
最後一個條件相當棘手。它將 possPref 設定為清單中的第一個提供,但如果任何提供通過 isMatch 測試,它將覆寫該值。但迴圈不會中斷該 isMatch 通過,因此任何後續的 isMatch 提供將覆寫該匹配。因此,為了複製該行為,我需要使用 LastOrDefault。 [7]
類別 Service...
static Offering possiblePreference(Equipment equipment, Region region) {
Offering possPref = null;
var allOfferings = equipment.AllOfferings(region);
possPref = allOfferings.FirstOrDefault(o => o.isPreferred);
if (null != possPref) return possPref;
possPref = allOfferings.LastOrDefault(o => o.isMatch);
if (null != possPref) return possPref;
foreach (var o2 in allOfferings) {
if (o2.isMatch || possPref == null) {
possPref = o2;
}
}
return possPref;
}
迴圈中剩下的最後一點只是回傳第一個項目。
類別 Service...
static Offering possiblePreference(Equipment equipment, Region region) {
Offering possPref = null;
var allOfferings = equipment.AllOfferings(region);
possPref = allOfferings.FirstOrDefault(o => o.isPreferred);
if (null != possPref) return possPref;
possPref = allOfferings.LastOrDefault(o => o.isMatch);
if (null != possPref) return possPref;
return allOfferings.First();
foreach (var o2 in allOfferings) {
if (possPref == null) {
possPref = o2;
}
}
return possPref;
}
我的個人慣例是將 result 用於函式中用於回傳的任何變數的名稱,因此我重新命名它。
類別 Service...
static Offering possiblePreference(Equipment equipment, Region region) {
Offering result = null;
var allOfferings = equipment.AllOfferings(region);
result = allOfferings.FirstOrDefault(o => o.isPreferred);
if (null != result) return result;
result = allOfferings.LastOrDefault(o => o.isMatch);
if (null != result) return result;
return allOfferings.First();
}
現在我對 possiblePreference 相當滿意,我認為它相當清楚地說明了邏輯,在網域中是有意義的。我不再需要找出程式碼在做什麼才能理解它的意圖。
然而,由於我使用 C#,我可以透過使用空值合併運算子(??)讓它讀起來更好。這允許我將幾個表達式串連在一起,並回傳第一個非空的表達式。
類別 Service...
static Offering possiblePreference(Equipment equipment, Region region) {
var allOfferings = equipment.AllOfferings(region);
return allOfferings.FirstOrDefault(o => o.isPreferred)
?? allOfferings.LastOrDefault(o => o.isMatch)
?? allOfferings.First();
}
在將空值視為假值處理的較不嚴格的型別語言中,您可以使用「或」運算子執行相同操作。另一種替代方案是組成一級函式(但那是另一個主題)。
現在我回到外層迴圈,它目前看起來像這樣。
類別 Service...
var loopStart = equipment.AllOfferings()
.Select(o => o.Region)
.Distinct();
foreach (Region r in loopStart) {
var possPref = possiblePreference(equipment, r);
possPref.isPreferred = true;
}
我可以在管道中使用我的 possiblePreference。
類別 Service...
var loopStart = equipment.AllOfferings()
.Select(o => o.Region)
.Distinct()
.Select(r => possiblePreference(equipment, r))
;
foreach (Offering o in loopStart) {
var possPref = possiblePreference(product, r);
o.isPreferred = true;
}
請注意將分號放在自己一行上的樣式。我經常對較長的管道這樣做,因為這樣可以更容易地操作管道。
透過重新命名初始迴圈變數,結果讀起來很清楚。
類別 Service...
var preferredOfferings = equipment.AllOfferings()
.Select(o => o.Region)
.Distinct()
.Select(r => possiblePreference(equipment, r))
;
foreach (Offering o in preferredOfferings) {
o.isPreferred = true;
}
我很樂意就此打住,但我也可以將 forEach 行為移到管線中,就像這樣。
類別 Service...
equipment.AllOfferings()
.Select(o => o.Region)
.Distinct()
.Select(r => possiblePreference(equipment, r))
.ToList()
.ForEach(o => o.isPreferred = true)
;
這是個較有爭議性的步驟。許多人不喜歡在管線中使用具有副作用的函式。這就是我必須使用中間的 ToList 的原因,因為 ForEach 在 IEnumerable 上不可用。除了副作用的問題之外,使用 ToList 也提醒我們,每當我們使用副作用時,我們也會失去管線評估中的任何惰性(這在這裡不是問題,因為管線的重點是選擇一些物件進行修改)。
然而,無論哪種方式,我發現這比原始迴圈清楚多了。較早的迴圈範例相當清楚易懂,但這個範例需要思考才能找出它在做什麼。當然,提取 possiblePreference 是讓它更清楚的一個重要因素,你可以這麼做並保留迴圈,儘管我當然希望避免修改邏輯以確保我避免重複區域。
分組飛行記錄
使用這個範例,我將查看一些摘要航班延誤資訊的程式碼。該程式碼從準時航班績效記錄開始,最初來自美國運輸部 運輸統計局。經過一些初步整理後,產生的資料看起來像這樣
[
{
"origin":"BOS","dest":"LAX","date":"2015-01-12",
"number":"25","carrier":"AA","delay":0.0,"cancelled":false
},
{
"origin":"BOS","dest":"LAX","date":"2015-01-13",
"number":"25","carrier":"AA","delay":0.0,"cancelled":false
},
…
以下是處理它的迴圈
export function airportData() {
const data = flightData();
const count = {};
const cancellations = {};
const totalDelay = {};
for (let row of data) {
const airport = row.dest;
if (count[airport] === undefined) {
count[airport] = 0;
cancellations[airport] = 0;
totalDelay[airport] = 0;
}
count[airport]++;
if (row.cancelled) {
cancellations[airport]++ ;
}
else {
totalDelay[airport] += row.delay;
}
}
const result = {};
for (let i in count) {
result[i] = {};
result[i].meanDelay = totalDelay[i] / (count[i] - cancellations[i]);
result[i].cancellationRate = cancellations[i] / count[i];
}
return result;
}
這個範例使用 Javascript(es6 on node),因為現在所有東西都必須用 Javascript 編寫。
迴圈按目的地機場(dest)摘要航班資料,並計算取消率和平均延誤。這裡的核心活動是按目的地對航班資料進行分組,這非常適合管線中的 group 運算子。因此,我的第一步是建立一個變數來擷取這個分組。
import _ from 'underscore';
export function airportData() {
const data = flightData();
const working = _.groupBy(data, r => r.dest);
const count = {};
const cancellations = {};
const totalDelay = {};
for (let row of data) {
const airport = row.dest;
if (count[airport] === undefined) {
count[airport] = 0;
cancellations[airport] = 0;
totalDelay[airport] = 0;
}
count[airport]++;
if (row.cancelled) {
cancellations[airport]++;
}
else {
totalDelay[airport] += row.delay;
}
}
const result = {};
for (let i in count) {
result[i] = {};
result[i].meanDelay = totalDelay[i] / (count[i] - cancellations[i]);
result[i].cancellationRate = cancellations[i] / count[i];
}
return result;
}
關於這個步驟有幾件事。首先,我還想不出一個好名字,所以我只稱它為 working。其次,儘管 javascript 在 Array 上有一組良好的集合管線運算子,但它缺少分組運算子。我可以自己寫一個,但相反地,我將使用 underscore 函式庫,它長期以來一直是 Javascript 領域中的有用工具。
計數變數擷取每個目的地機場有多少航班記錄。我可以在管線中使用 map 運算 輕鬆計算這個值。
export function airportData() {
const data = flightData();
const working = _.chain(data)
.groupBy(r => r.dest)
.mapObject((val, key) => {return {count: val.length}})
.value()
;
const count = {};
const cancellations = {};
const totalDelay = {};
for (let row of data) {
const airport = row.dest;
if (count[airport] === undefined) {
count[airport] = 0;
cancellations[airport] = 0;
totalDelay[airport] = 0;
}
count[airport]++;
if (row.cancelled) {
cancellations[airport]++;
}
else {
totalDelay[airport] += row.delay;
}
}
const result = {};
for (let i in count) {
result[i] = {};
result[i].meanDelay = totalDelay[i] / (working[i].count - cancellations[i]);
result[i].cancellationRate = cancellations[i] / working[i].count;
}
return result;
}
要在 underscore 中執行這樣的多步驟管線,我必須使用 chain 函式啟動管線。這可確保管線中的每個步驟都包裝在 underscore 中,因此我可以使用 方法鏈 來建立管線。缺點是我必須在最後使用 value 才能從中取得基礎陣列。
地圖操作並非標準地圖,因為它會對 JavaScript 物件的內容進行操作,基本上是一個雜湊映射,因此映射函式會對一個鍵/值對進行操作。在底線中,我使用 mapObject 函式執行此操作。
通常,當我將行為移至管線時,我喜歡完全移除控制變數,但它也在追蹤所需的鍵中扮演角色,因此我會暫時保留它,直到我處理完其他計算。
接下來我要處理取消變數,這次我可以移除它。
export function airportData() {
const data = flightData();
const working = _.chain(data)
.groupBy(r => r.dest)
.mapObject((val, key) => {
return {
count: val.length,
cancellations: val.filter(r => r.cancelled).length
}
})
.value()
;
const count = {};
const cancellations = {};
const totalDelay = {};
const cancellations = {};
for (let row of data) {
const airport = row.dest;
if (count[airport] === undefined) {
count[airport] = 0;
cancellations[airport] = 0;
totalDelay[airport] = 0;
}
count[airport]++;
if (row.cancelled) {
cancellations[airport]++;
}
else {
totalDelay[airport] += row.delay;
}
}
const result = {};
for (let i in count) {
result[i] = {};
result[i].meanDelay = totalDelay[i] / (working[i].count - working[i].cancellations);
result[i].cancellationRate = working[i].cancellations / working[i].count;
}
return result;
}
映射函式現在變得相當長,因此我想是時候對它使用 Extract Method 了。
export function airportData() {
const data = flightData();
const summarize = function(rows) {
return {
count: rows.length,
cancellations: rows.filter(r => r.cancelled).length
}
}
const working = _.chain(data)
.groupBy(r => r.dest)
.mapObject((val, key) => summarize(val))
.value()
;
const count = {};
const totalDelay = {}
for (let row of data) {
const airport = row.dest;
if (count[airport] === undefined) {
count[airport] = 0;
totalDelay[airport] = 0;
}
count[airport]++;
if (row.cancelled) {
}
else {
totalDelay[airport] += row.delay;
}
}
const result = {};
for (let i in count) {
result[i] = {};
result[i].meanDelay = totalDelay[i] / (working[i].count - working[i].cancellations);
result[i].cancellationRate = working[i].cancellations / working[i].count;
}
return result;
}
將函式指定給整體函式中的變數是 JavaScript 巢狀函式定義的方式,以將其範圍限制在 airportData 函式中。我可以想像這個函式會有更廣泛的用途,但那是後續要考量的重構。
現在來處理總延遲計算。
export function airportData() {
const data = flightData();
const summarize = function(rows) {
return {
count: rows.length,
cancellations: rows.filter(r => r.cancelled).length,
totalDelay: rows.filter(r => !r.cancelled).reduce((acc,each) => acc + each.delay, 0)
}
}
const working = _.chain(data)
.groupBy(r => r.dest)
.mapObject((val, key) => summarize(val))
.value()
;
const count = {};
const totalDelay = {}
for (let row of data) {
const airport = row.dest;
if (count[airport] === undefined) {
count[airport] = 0;
totalDelay[airport] = 0;
}
count[airport]++;
if (row.cancelled) {
}
else {
totalDelay[airport] += row.delay;
}
}
const result = {};
for (let i in count) {
result[i] = {};
result[i].meanDelay = working[i].totalDelay / (working[i].count - working[i].cancellations);
result[i].cancellationRate = working[i].cancellations / working[i].count;
}
return result;
}
lambda 中用於總延遲的表達式反映了原始公式,使用 reduce 操作 來計算總和。我常常發現先使用映射會更易於閱讀。
export function airportData() {
const data = flightData();
const summarize = function(rows) {
return {
count: rows.length,
cancellations: rows.filter(r => r.cancelled).length,
totalDelay: rows.filter(r => !r.cancelled).map(r => r.delay).reduce((a,b) => a + b)
}
}
const working = _.chain(data)
.groupBy(r => r.dest)
.mapObject((val, key) => summarize(val))
.value()
;
const count = {};
for (let row of data) {
const airport = row.dest;
if (count[airport] === undefined) {
count[airport] = 0;
}
count[airport]++;
}
const result = {};
for (let i in count) {
result[i] = {};
result[i].meanDelay = working[i].totalDelay / (working[i].count - working[i].cancellations);
result[i].cancellationRate = working[i].cancellations / working[i].count;
}
return result;
}
這種重新表述並非大事,但我越來越喜歡它。那個 lambda 也有一點長,但還不到我覺得需要提取它的程度。
我也趁機將呼叫 summarize 的 lambda 替換為僅命名函式。
export function airportData() {
const data = flightData();
const summarize = function(rows) {
return {
count: rows.length,
cancellations: rows.filter(r => r.cancelled).length,
totalDelay: rows.filter(r => !r.cancelled).map(r => r.delay).reduce((a,b) => a + b)
}
}
const working = _.chain(data)
.groupBy(r => r.dest)
.mapObject(summarize)
.value()
;
const count = {};
for (let row of data) {
const airport = row.dest;
if (count[airport] === undefined) {
count[airport] = 0;
}
count[airport]++;
}
const result = {};
for (let i in count) {
result[i] = {};
result[i].meanDelay = working[i].totalDelay / (working[i].count - working[i].cancellations);
result[i].cancellationRate = working[i].cancellations / working[i].count;
}
return result;
}
現在,在移除所有依賴資料後,我準備移除 count。
export function airportData() {
const data = flightData();
const summarize = function(rows) {
return {
count: rows.length,
cancellations: rows.filter(r => r.cancelled).length,
totalDelay: rows.filter(r => !r.cancelled).map(r => r.delay).reduce((a,b) => a + b)
}
}
const working = _.chain(data)
.groupBy(r => r.dest)
.mapObject(summarize)
.value()
;
const count = {};
for (let row of data) {
const airport = row.dest;
if (count[airport] === undefined) {
count[airport] = 0;
}
count[airport]++;
}
const result = {};
for (let i in working) {
result[i] = {};
result[i].meanDelay = working[i].totalDelay / (working[i].count - working[i].cancellations);
result[i].cancellationRate = working[i].cancellations / working[i].count;
}
return result;
}
現在,我將注意力轉向第二個迴圈,它基本上執行 map 來計算其兩個值。
export function airportData() {
const data = flightData();
const summarize = function(rows) {
return {
count: rows.length,
cancellations: rows.filter(r => r.cancelled).length,
totalDelay: rows.filter(r => !r.cancelled).map(r => r.delay).reduce((a,b) => a + b)
}
}
const formResult = function(row) {
return {
meanDelay: row.totalDelay / (row.count - row.cancellations),
cancellationRate: row.cancellations / row.count
}
}
let working = _.chain(data)
.groupBy(r => r.dest)
.mapObject(summarize)
.mapObject(formResult)
.value()
;
return working;
let result = {};
for (let i in working) {
result[i] = {};
result[i].meanDelay = working[i].totalDelay / (working[i].count - working[i].cancellations);
result[i].cancellationRate = working[i].cancellations / working[i].count;
}
return result;
}
在完成所有這些操作後,我可以在 working 上使用 Inline Temp,並進行更多重新命名和整理。
export function airportData() {
const data = flightData();
const summarize = function(flights) {
return {
numFlights: flights.length,
numCancellations: flights.filter(f => f.cancelled).length,
totalDelay: flights.filter(f => !f.cancelled).map(f => f.delay).reduce((a,b) => a + b)
}
}
const formResult = function(airport) {
return {
meanDelay: airport.totalDelay / (airport.numFlights - airport.numCancellations),
cancellationRate: airport.numCancellations / airport.numFlights
}
}
return _.chain(data)
.groupBy(r => r.dest)
.mapObject(summarize)
.mapObject(formResult)
.value()
;
}
就像通常的情況一樣,最終函式可讀性大幅提升,是因為提取了函式。但我發現分組運算子在釐清函式的目的方面有很大幫助,也有助於設定提取。
如果資料來自關聯式資料庫,而且我遇到效能問題,這個重構還有另一個潛在的優點。透過從迴圈重構到集合管線,我以更類似 SQL 的形式表示轉換。針對這個任務,我可能會從資料庫中提取大量資料,但重構的程式碼讓考慮將群組和第一層摘要邏輯移到 SQL 中變得更容易,這會減少我需要透過網路傳輸的資料量。我通常比較喜歡將邏輯保留在應用程式程式碼中,而不是 SQL,因此我會將這樣的變更視為效能最佳化,而且只有在我可以測量到顯著的效能改善時才會這麼做。但這強化了一個觀點,也就是在有清楚的程式碼可供處理時,執行最佳化容易多了,這也是我認識的所有效能高手都強調清晰優先是效能良好程式碼基礎的原因。
識別碼
在我們的下一個範例中,我將檢視一些檢查人員是否具有一組必要識別碼的程式碼。系統通常會依賴透過某種類似客戶 ID 的唯一識別碼來識別人員。在許多網域中,您必須處理許多不同的識別方案,而且人員應該具有多個方案的識別碼。因此,鎮公所可能會希望人員具有鎮 ID、州 ID 和國家 ID。

圖 2:人員具有不同方案識別碼的資料模型
這種情況的資料結構非常簡單。人員類別有一組識別碼物件。識別碼有一個用於方案和一些值的欄位。但通常有無法僅由資料模型強制執行的進一步約束,此類約束會由驗證函數(例如這個函數)檢查。
類別人員...
def check_valid_ids required_schemes, note: nil
note ||= Notification.new
note.add_error "has no ids" if @ids.size < 1
used = []
found_required = []
dups = []
for id in @ids
next if id.void?
if used.include?(id.scheme)
dups << id.scheme
else
for req in required_schemes
if id.scheme == req
found_required << req
required_schemes.delete req
next
end
end
end
used << id.scheme
end
if dups.size > 0
note.add_error "duplicate schemes: " + dups.join(", ")
end
if required_schemes.size > 0
missing_names = ""
for req in required_schemes
missing_names += (missing_names.size > 0) ? ", " + req.to_s : req.to_s
end
note.add_error "missing schemes: " + missing_names
end
return note
end
這個範例使用 Ruby,因為我喜歡用 Ruby 程式設計
還有幾個其他物件支援這個迴圈。識別碼類別知道其方案、值,以及是否為空值 - 表示已邏輯刪除(但仍保留在資料庫中)。還有一個通知來追蹤任何錯誤。
class Identifier
attr_reader :scheme, :value
def void?
…
class Notification
def add_error e
…
對我來說,此例程中最大的問題是迴圈同時進行兩件事。它同時尋找重複的識別碼(收集在 dups 中)和尋找遺失的必要架構(在 required_schemes 中)。程式設計師經常會遇到對同一物件集合執行兩件事的情況,並決定在同一個迴圈中執行這兩件事。原因之一是設定迴圈所需的程式碼,寫兩次似乎很浪費。現代迴圈建構和管線消除了這個負擔。更惡劣的原因是對效能的疑慮。當然,許多效能熱點都涉及迴圈,而且有些情況下可以融合迴圈來改善問題。但這些只佔我們撰寫的所有迴圈的一小部分,因此我們應該遵循程式設計的慣用原則。除非您有經過測量且顯著的效能問題,否則應專注於清晰度而非效能。如果您有此類問題,則優先解決問題會比清晰度重要,但這種情況很少見。
除非您有經過測量且顯著的效能問題,否則應專注於清晰度而非效能。
因此,當遇到同時進行兩件事的迴圈時,我毫不猶豫地複製迴圈以提高清晰度。效能分析極少會讓我逆轉此重構。
因此,我的第一步是使用我稱為「分割迴圈」的重構。執行此操作時,我首先取得迴圈和將其連接成一個連貫程式碼區塊的程式碼,並對其套用 萃取方法。
類別人員...
def check_valid_ids required_schemes, note: nil
note ||= Notification.new
note.add_error "has no ids" if @ids.size < 1
return inner_check_valid_ids required_schemes, note: note
end
def inner_check_valid_ids required_schemes, note: nil
used = []
found_required = []
dups = []
for id in @ids
next if id.void?
if used.include?(id.scheme)
dups << id.scheme
else
for req in required_schemes
if id.scheme == req
found_required << req
required_schemes.delete req
next
end
end
end
used << id.scheme
end
if dups.size > 0
note.add_error "duplicate schemes: " + dups.join(", ")
end
if required_schemes.size > 0
missing_names = ""
for req in required_schemes
missing_names += (missing_names.size > 0) ? ", " + req.to_s : req.to_s
end
note.add_error "missing schemes: " + missing_names
end
return note
end
這個萃取的方法正在執行兩件事,因此現在我想複製它以形成兩個獨立方法的架構,每個方法只會執行一件事。如果我複製它並分別呼叫每個方法,則我的累積通知會收到兩倍的錯誤,我可以透過從每個複製品中移除不相關的更新來避免這個問題。
類別人員...
def check_valid_ids required_schemes, note: nil note ||= Notification.new note.add_error "has no ids" if @ids.size < 1 check_no_duplicate_ids required_schemes, note: note check_all_required_schemes required_schemes, note: note end def check_no_duplicate_ids required_schemes, note: nil used = [] found_required = [] dups = [] for id in @ids next if id.void? if used.include?(id.scheme) dups << id.scheme else for req in required_schemes if id.scheme == req found_required << req required_schemes.delete req next end end end used << id.scheme end if dups.size > 0 note.add_error "duplicate schemes: " + dups.join(", ") end if required_schemes.size > 0 missing_names = "" for req in required_schemes missing_names += (missing_names.size > 0) ? ", " + req.to_s : req.to_s end note.add_error "missing schemes: " + missing_names end return note end def check_all_required_schemes required_schemes, note: nil used = [] found_required = [] dups = [] for id in @ids next if id.void? if used.include?(id.scheme) dups << id.scheme else for req in required_schemes if id.scheme == req found_required << req required_schemes.delete req next end end end used << id.scheme end if dups.size > 0 note.add_error "duplicate schemes: " + dups.join(", ") end if required_schemes.size > 0 missing_names = "" for req in required_schemes missing_names += (missing_names.size > 0) ? ", " + req.to_s : req.to_s end note.add_error "missing schemes: " + missing_names end return note end
移除重複更新非常重要,這樣我在重構時所有測試都能持續通過。
結果相當難看,但現在我可以獨立處理每個方法,移除任何與每個方法目的無關的內容。
重構不重複檢查
我將從沒有重複項目的情況開始,我可以分幾個步驟刪除程式碼區塊,並在每個步驟後進行測試以確保我沒有犯錯。我首先移除最後使用 required_schemes 的程式碼
類別人員...
def check_no_duplicate_ids required_schemes, note: nil
used = []
found_required = []
dups = []
for id in @ids
next if id.void?
if used.include?(id.scheme)
dups << id.scheme
else
for req in required_schemes
if id.scheme == req
found_required << req
required_schemes.delete req
next
end
end
end
used << id.scheme
end
if dups.size > 0
note.add_error "duplicate schemes: " + dups.join(", ")
end
if required_schemes.size > 0
missing_names = ""
for req in required_schemes
missing_names += (missing_names.size > 0) ? ", " + req.to_s : req.to_s
end
end
return note
end
然後我取出條件式的多餘分支
類別人員...
def check_no_duplicate_ids required_schemes, note: nil
used = []
found_required = []
dups = []
for id in @ids
next if id.void?
if used.include?(id.scheme)
dups << id.scheme
else
for req in required_schemes
if id.scheme == req
found_required << req
required_schemes.delete req
next
end
end
end
used << id.scheme
end
if dups.size > 0
note.add_error "duplicate schemes: " + dups.join(", ")
end
return note
end
在這個時候,我可以,而且或許應該,移除現在不需要的 required_schemes 參數。我沒有這麼做,你會看到它最後會被整理出來。
我執行我平常的
類別人員...
def check_no_duplicate_ids required_schemes, note: nil
used = []
dups = []
input = @ids
for id in input
next if id.void?
if used.include?(id.scheme)
dups << id.scheme
end
used << id.scheme
end
if dups.size > 0
note.add_error "duplicate schemes: " + dups.join(", ")
end
return note
end
然後我可以在輸入變數中新增一個 filter,並移除略過空識別碼的那一行。
類別人員...
def check_no_duplicate_ids required_schemes, note: nil
used = []
dups = []
input = @ids.reject{|id| id.void?}
for id in input
next if id.void?
if used.include?(id.scheme)
dups << id.scheme
end
used << id.scheme
end
if dups.size > 0
note.add_error "duplicate schemes: " + dups.join(", ")
end
return note
end
進一步查看迴圈,我可以看到它使用的是 scheme 而不是 id,所以我可以在 pipeline 步驟中新增 map id 到 scheme。
類別人員...
def check_no_duplicate_ids required_schemes, note: nil
used = []
dups = []
input = @ids
.reject{|id| id.void?}
.map {|id| id.scheme}
for scheme in input
if used.include?(scheme)
dups << scheme
end
used << scheme
end
if dups.size > 0
note.add_error "duplicate schemes: " + dups.join(", ")
end
return note
end
在這個時候,我已經將迴圈主體簡化成簡單的移除重複行為。有一個 pipeline 方法可以找出重複,就是 group scheme 本身,並 filter 出現超過一次的那些。
類別人員...
def check_no_duplicate_ids required_schemes, note: nil
used = []
dups = []
input = @ids
.reject{|id| id.void?}
.map {|id| id.scheme}
.group_by {|s| s}
.select {|k,v| v.size > 1}
.keys
for scheme in input
if used.include?(scheme)
dups << scheme
end
used << scheme
end
if dups.size > 0
note.add_error "duplicate schemes: " + dups.join(", ")
end
return note
end
現在 pipeline 的輸出是重複,所以我可以移除輸入變數,並將 pipeline 指定給變數(並移除現在不需要的 used 變數)。
類別人員...
def check_no_duplicate_ids required_schemes, note: nil
used = []
dups = []
dups = @ids
.reject{|id| id.void?}
.map {|id| id.scheme}
.group_by {|s| s}
.select {|k,v| v.size > 1}
.keys
for scheme in input
dups << scheme
used << scheme
end
if dups.size > 0
note.add_error "duplicate schemes: " + dups.join(", ")
end
return note
end
那會給我們一個不錯的 pipeline,但有一個令人困擾的元素。pipeline 中的最後三個步驟是為了移除重複,但這個知識在我的腦袋裡,而不是程式碼中。我需要使用 Extract Method 將它移到程式碼中。
類別人員...
def check_no_duplicate_ids required_schemes, note: nil
dups = @ids
.reject{|id| id.void?}
.map {|id| id.scheme}
.duplicates
if dups.size > 0
note.add_error "duplicate schemes: " + dups.join(", ")
end
return note
end
class Array…
def duplicates
self
.group_by {|s| s}
.select {|k,v| v.size > 1}
.keys
end
這裡我使用 Ruby 在現有類別中新增方法的能力(稱為 monkey-patching)。我也可以在最新的 Ruby 版本中使用 Ruby 的 refinement 功能。然而,許多 OO 語言不支援 monkey-patching,在這種情況下我必須使用局部定義的函式,類似以下內容
類別人員...
def check_no_duplicate_ids required_schemes, note: nil
schemes = @ids
.reject{|id| id.void?}
.map {|id| id.scheme}
if duplicates(schemes).size > 0
note.add_error "duplicate schemes: " + duplicates(schemes).join(", ")
end
return note
end
def duplicates anArray
anArray
.group_by {|s| s}
.select {|k,v| v.size > 1}
.keys
end
在 person 上定義方法不如將它放在陣列上對 pipeline 來說好。但我們常常無法在陣列上放置方法,因為我們的語言不包含 monkey patching,或者專案標準讓它不容易,或者它是一個方法,不夠通用到可以放在通用清單類別上。這是物件導向方法會造成阻礙的情況,而不會將方法繫結到物件上的函式方法會運作得更好。
每當我有一個像這樣的局部變數時,我總是會考慮使用 Replace Temp with Query 將變數變成方法 - 導致類似這樣的結果。
類別人員...
def check_no_duplicate_ids required_schemes, note: nil
if duplicate_identity_schemes.size > 0
note.add_error "duplicate schemes: " + duplicate_identity_schemes.join(", ")
end
return note
end
def duplicate_identity_schemes
@ids
.reject{|id| id.void?}
.map {|id| id.scheme}
.duplicates
end
我根據我認為 duplicate_identity_schemes 行為是否可能對 person 類中的其他方法有用的判斷來做出這個決定。但儘管我比較喜歡在查詢方法中出錯,但對於這個情況,我比較喜歡將它保留為一個局部變數。
重構所有必要方案的檢查
現在我已經清理了對沒有重複項目的檢查,我可以處理我們擁有所有必要方案的檢查。以下是目前的方法。
類別人員...
def check_all_required_schemes required_schemes, note: nil
used = []
found_required = []
dups = []
for id in @ids
next if id.void?
if used.include?(id.scheme)
dups << id.scheme
else
for req in required_schemes
if id.scheme == req
found_required << req
required_schemes.delete req
next
end
end
end
used << id.scheme
end
if dups.size > 0
end
if required_schemes.size > 0
missing_names = ""
for req in required_schemes
missing_names += (missing_names.size > 0) ? ", " + req.to_s : req.to_s
end
note.add_error "missing schemes: " + missing_names
end
return note
end
與之前的做法一樣,我的第一步是移除任何與檢查重複項目有關的事情。
類別人員...
def check_all_required_schemes required_schemes, note: nil
used = []
found_required = []
dups = []
for id in @ids
next if id.void?
if used.include?(id.scheme)
dups << id.scheme
else
for req in required_schemes
if id.scheme == req
found_required << req
required_schemes.delete req
next
end
end
end
used << id.scheme
end
if dups.size > 0
end
if required_schemes.size > 0
missing_names = ""
for req in required_schemes
missing_names += (missing_names.size > 0) ? ", " + req.to_s : req.to_s
end
note.add_error "missing schemes: " + missing_names
end
return note
end
為了深入了解此函數,我首先查看 found_required 變數。與檢查重複項目情況一樣,它主要感興趣的是我們有非空識別碼的方案,所以我傾向於首先將方案擷取到一個變數中,並使用它們而不是 ID。
類別人員...
def check_all_required_schemes required_schemes, note: nil
found_required = []
schemes = @ids
.reject{|i| i.void?}
.map {|i| i.scheme}
for s in schemes
next if id.void?
for req in required_schemes
if s == req
found_required << req
required_schemes.delete req
next
end
end
end
if required_schemes.size > 0
missing_names = ""
for req in required_schemes
missing_names += (missing_names.size > 0) ? ", " + req.to_s : req.to_s
end
note.add_error "missing schemes: " + missing_names
end
return note
end
found_required 的目的是擷取同時在 required_schemes 清單和我們的 ID 中的方案。這聽起來像一個集合交集,而這是我應該在任何自尊的集合中預期的函數。因此我應該能夠用它來確定 found_required。
類別人員...
def check_all_required_schemes required_schemes, note: nil found_required = [] schemes = @ids .reject{|i| i.void?} .map {|i| i.scheme} for s in schemes for req in required_schemes if s == req found_required << req required_schemes.delete req next end end end found_required = schemes & required_schemes if required_schemes.size > 0 missing_names = "" for req in required_schemes missing_names += (missing_names.size > 0) ? ", " + req.to_s : req.to_s end note.add_error "missing schemes: " + missing_names end return note end
遺憾的是,此舉動未能通過測試。現在我更仔細地查看程式碼,並意識到 found_required 根本沒有被後面的程式碼使用,它是一個殭屍變數,可能曾經用於某事,但後來放棄了這種用法,而且這個變數從未從程式碼中移除。因此我撤回我剛才做的更改並將其移除。
類別人員...
def check_all_required_schemes required_schemes, note: nil
found_required = []
schemes = @ids
.reject{|i| i.void?}
.map {|i| i.scheme}
for s in schemes
for req in required_schemes
if s == req
found_required << req
required_schemes.delete req
next
end
end
end
if required_schemes.size > 0
missing_names = ""
for req in required_schemes
missing_names += (missing_names.size > 0) ? ", " + req.to_s : req.to_s
end
note.add_error "missing schemes: " + missing_names
end
return note
end
現在我看到迴圈正在從參數 required_schemes 中移除元素。對參數進行這樣的修改對我來說是一個嚴格的禁忌,除非它是一個收集參數(例如備註)。所以我立即套用 移除對參數的指定
類別人員...
def check_all_required_schemes required_schemes, note: nil missing_schemes = required_schemes.dup schemes = @ids .reject{|i| i.void?} .map {|i| i.scheme} for s in schemes for req in required_schemes if s == req missing_schemes.delete req next end end end if missing_schemes.size > 0 missing_names = "" for req in missing_schemes missing_names += (missing_names.size > 0) ? ", " + req.to_s : req.to_s end note.add_error "missing schemes: " + missing_names end return note end
這樣做也顯示出迴圈正在從它列舉的清單中刪除項目 - 比修改參數更糟糕的事情。
現在這已經釐清了,我可以看到集合運算是一個適當的選擇,但我需要做的是從必要的清單中移除我們擁有的方案 - 使用集合差分運算。
類別人員...
def check_all_required_schemes required_schemes, note: nil missing_schemes = required_schemes.dup schemes = @ids .reject{|i| i.void?} .map {|i| i.scheme} missing_schemes = required_schemes - schemes for s in schemes for req in required_schemes if s == req missing_schemes.delete req next end end end if missing_schemes.size > 0 missing_names = "" for req in missing_schemes missing_names += (missing_names.size > 0) ? ", " + req.to_s : req.to_s end note.add_error "missing schemes: " + missing_names end return note end
現在我查看第二個迴圈,形成錯誤訊息。這只是將方案轉換為字串並用逗號將它們連接起來 - 這是字串連接運算的工作。
類別人員...
def check_all_required_schemes required_schemes, note: nil
schemes = @ids
.reject{|i| i.void?}
.map {|i| i.scheme}
missing_schemes = required_schemes - schemes
if missing_schemes.size > 0
missing_names = missing_schemes.join(", ")
for req in missing_schemes
missing_names += (missing_names.size > 0) ? ", " + req.to_s : req.to_s
end
note.add_error "missing schemes: " + missing_names
end
return note
end
合併兩個方法
現在這兩個方法都已清理乾淨,它們只做一件事,而且清楚自己在做什麼。它們都需要非空識別碼的方案清單,所以我傾向於使用 萃取方法
類別人員...
def check_no_duplicate_ids required_schemes, note: nil
dups = @ids
.reject{|id| id.void?}
.map {|id| id.scheme}
.duplicates
dups = identity_schemes.duplicates
if dups.size > 0
note.add_error "duplicate schemes: " + dups.join(", ")
end
return note
end
def check_all_required_schemes required_schemes, note: nil
schemes = @ids
.reject{|i| i.void?}
.map {|i| i.scheme}
missing_schemes = required_schemes - identity_schemes
if missing_schemes.size > 0
missing_names = missing_schemes.join(", ")
note.add_error "missing schemes: " + missing_names
end
return note
end
def identity_schemes
@ids
.reject{|i| i.void?}
.map {|i| i.scheme}
end
然後我想要一些小的清理。首先,我透過檢查集合的大小來測試集合是否為空。我總是比較喜歡更能揭示意圖的 empty 方法。
類別人員...
def check_no_duplicate_ids required_schemes, note: nil
dups = identity_schemes.duplicates
unless dups.empty?
note.add_error "duplicate schemes: " + dups.join(", ")
end
return note
end
def check_all_required_schemes required_schemes, note: nil
missing_schemes = required_schemes - identity_schemes
unless missing_schemes.empty?
missing_names = missing_schemes.join(", ")
note.add_error "missing schemes: " + missing_names
end
return note
end
我沒有為這個重構命名,它應該是「用揭示意圖的方法取代揭示實作的方法」之類的東西。
missing_names 變數沒有發揮作用,所以我將對它使用 內嵌暫存。
類別人員...
def check_no_duplicate_ids required_schemes, note: nil
dups = identity_schemes.duplicates
unless dups.empty?
note.add_error "duplicate schemes: " + dups.join(", ")
end
return note
end
def check_all_required_schemes required_schemes, note: nil
missing_schemes = required_schemes - identity_schemes
unless missing_schemes.empty?
missing_names = missing_schemes.join(", ")
note.add_error "missing schemes: " + missing_schemes.join(", ")
end
return note
end
我也想將這兩個都轉換為使用單行條件語法
類別人員...
def check_no_duplicate_ids required_schemes, note: nil
dups = identity_schemes.duplicates
unless dups.empty?
note.add_error "duplicate schemes: " + dups.join(", ") unless dups.empty?
end
return note
end
def check_all_required_schemes required_schemes, note: nil
missing_schemes = required_schemes - identity_schemes
unless missing_schemes.empty?
note.add_error "missing schemes: " + missing_schemes.join(", ") unless missing_schemes.empty?
end
return note
end
同樣地,沒有定義的重構,而且它將是非常特定的 Ruby。
因此,我不認為這些方法還有價值,所以我將它們內嵌,以及提取的 identity_schemes 方法,再放回呼叫者
類別人員...
def check_valid_ids required_schemes, note: nil
note ||= Notification.new
note.add_error "has no ids" if @ids.size < 1
identity_schemes = @ids.reject{|i| i.void?}.map {|i| i.scheme}
dups = identity_schemes.duplicates
note.add_error("duplicate schemes: " + dups.join(", ")) unless dups.empty?
missing_schemes = required_schemes - identity_schemes
note.add_error "missing schemes: " + missing_schemes.join(", ") unless missing_schemes.empty?
return note
end
最後一個方法比我通常使用的要長一些,但我喜歡它的凝聚力。如果它變得更大,我想將它拆分,也許使用 將方法替換為方法物件 即使它很長,我發現它在傳達驗證檢查的錯誤時更清晰。
最後的想法
這結束了這組重構範例。我希望它能讓您充分了解集合管線如何釐清操作集合的程式碼邏輯,以及如何經常非常直接地將迴圈重構成集合管線。
與任何重構一樣,有一個類似的反向重構,可以將集合管線轉換為迴圈,但我幾乎從不做這種事。
如今,大多數現代語言都提供一級函數和集合函式庫,其中包含集合管線所需的運算。如果您不習慣使用集合管線,那麼對您遇到的迴圈進行重構並像這樣重構它們是一個很好的練習。如果您發現最終管線不如原始迴圈清晰,則可以在完成後隨時還原重構。即使您還原了重構,練習也可以讓您學到很多關於此技術的知識。我已經使用這種程式設計模式很長一段時間了,並發現它是一種幫助我閱讀自己程式碼的寶貴方式。因此,我認為探索它是值得的,看看您的團隊是否得出類似的結論。
註腳
1: 嗯,實際上,我的第一步是考慮對迴圈套用 提取方法,因為如果將迴圈孤立到自己的函數中,通常更容易操作迴圈。
2: 對我來說,看到 map 運算子 被稱為「Select」很奇怪。原因是 C# 中的管線方法來自 Linq,其主要目的是抽象資料庫存取,因此方法名稱被選為類似於 SQL。「Select」是 SQL 中的投影運算子,當您將其視為選取欄位時很有道理,但如果您將其視為使用函數對應時,則是一個奇怪的名稱。
3: 當然,這不是所有可以執行集合管線的語言的完整清單,所以我預期會收到一連串抱怨,說我沒有展示 Javascript、Scala 或 Whatever++。我這裡不想要一個龐大的語言清單,只想要一個足夠多樣化的小型集合,以傳達集合管線在不熟悉的語言中很容易遵循的概念。
4: 在某些情況下,它需要是一個短路,儘管這裡不是這種情況
5: 我經常發現這與負布林值有關。這是因為否定 (!) 出現在表達式的開頭,而謂詞 (isEmpty) 出現在結尾。在兩個之間有任何實質性的表達式,結果都難以解析。(至少對我來說是這樣。)
6: 我還沒有將它放入運算子目錄中。
7: 如果我使用一種沒有偵測通過謂詞的最後一個項目的運算的語言,我可以先反轉它,然後偵測第一個項目。
致謝
Kit Eason 協助讓 F# 範例更為慣用語法。Les Ramer 協助我改善我的 C#。Richard Warburton 修正我 Java 中一些不嚴謹的措辭。Daniel Sandbecker 發現 Ruby 範例中的錯誤。Andrew Kiellor、Bruno Trecenti、David Johnston、Duncan Cragg、Karel Alfonso、Korny Sietsma、Matteo Vaccari、Pete Hodgson、Piyush Srivastava、Scott Robinson、Steven Lowe 和 Vijay Aravamudhan 在 Thoughtworks 郵件清單上討論這篇文章的草稿。
重大修訂
2015 年 7 月 14 日:新增識別碼範例和最終想法
2015 年 7 月 7 日:新增群組航班資料範例
2015 年 6 月 30 日:新增設備提供範例。
2015 年 6 月 25 日:新增巢狀迴圈分期付款
2015 年 6 月 23 日:發布第一期