
網域邏輯與 SQL
在過去幾十年間,我們看到資料庫導向軟體開發人員和記憶體內應用程式軟體開發人員之間的差距越來越大。這導致許多關於如何使用 SQL 和儲存程序等資料庫功能的爭議。在本文中,我探討了是否將業務邏輯放在 SQL 查詢或記憶體內程式碼中的問題,主要考量效能和可維護性,並以一個簡單但豐富的 SQL 查詢為例。
2003 年 2 月

看看任何一本最近關於建置企業應用程式的書籍(例如我最近的 P of EAA),你會發現邏輯被分解成多個層級,將企業應用程式的不同部分分開。不同的作者使用不同的層級,但一個常見的主題是網域邏輯(業務規則)和資料來源邏輯(資料來自何處)之間的分離。由於企業應用程式資料的大部分儲存在關係資料庫中,這種分層架構試圖將業務邏輯與關係資料庫分開
許多應用程式開發人員,特別是我自己這樣的強 OO 開發人員,傾向於將關係資料庫視為一個最好隱藏起來的儲存機制。存在著宣傳將應用程式開發人員與 SQL 的複雜性隔離起來的優點的架構。
然而,SQL 遠遠不只是一個簡單的資料更新和擷取機制。SQL 的查詢處理可以執行許多任務。透過隱藏 SQL,應用程式開發人員排除了強大的工具。
在本文中,我想探討使用可能包含網域邏輯的豐富 SQL 查詢的優缺點。我必須聲明我在討論中帶有 OO 偏見,但我也有在另一邊的生活經驗。(一位前客戶的 OO 專家小組將我趕出公司,因為我是「資料模型設計師」。)
複雜查詢
關聯式資料庫都支援標準查詢語言 - SQL。我基本上相信 SQL 是關聯式資料庫成功到這種程度的主要原因。與資料庫互動的標準方式提供了高度的供應商獨立性,這有助於關聯式資料庫的崛起,並有助於應對 OO 挑戰。
SQL 有許多優點,但其中一個特別強大的功能是查詢資料庫的功能,允許客戶使用極少量的 SQL 程式碼來篩選和彙總大量資料。然而,使用強大的 SQL 查詢通常會嵌入網域邏輯,這與分層企業應用程式架構的基本原則相違背。
為了進一步探討這個主題,讓我們使用一個簡單的範例。我們將從類似於 圖 1 的資料模型開始。想像一下我們的公司有一個特別折扣,我們稱之為 Cuillen。如果客戶在該月份訂購價值超過 5000 美元的 Talisker,則有資格獲得 Cuillen 折扣。請注意,在同一個月訂購兩筆價值 3000 美元的訂單並不算,必須有一筆訂單超過 5000 美元。想像一下,您想要查看特定客戶並確定他們在過去一年中哪些月份有資格獲得 Cuillen 折扣。我將忽略使用者介面,並假設我們想要的是一個與其合格月份相應的數字清單。
{kind=link}
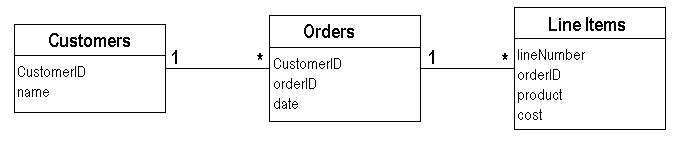
圖 1:範例的資料庫架構(UML 表示法)
我們可以用許多方法來回答這個問題。我將從三個粗略的替代方案開始:交易腳本、網域模型和複雜的 SQL。
對於所有這些範例,我將使用 Ruby 程式語言來說明它們。我在這裡冒了一點險:我通常使用 Java 和/或 C# 來說明這些事情,因為大多數應用程式開發人員都可以閱讀基於 C 的語言。我選擇 Ruby 有點像實驗。我喜歡這種語言,因為它鼓勵緊湊但結構良好的程式碼,並且可以輕鬆地以 OO 樣式編寫。這是我的腳本編寫首選語言。我新增了一個 快速 Ruby 語法指南,基於我這裡使用的 Ruby。
交易指令碼
交易腳本是我在 EAA 的 P 中為處理請求的程序式樣式所創造的模式名稱。在這種情況下,程序讀取它可能需要的所有資料,然後在記憶體中進行選擇和處理,以找出需要哪些月份。
def cuillen_months name
customerID = find_customerID_named(name)
result = []
find_orders(customerID).each do |row|
result << row['date'].month if cuillen?(row['orderID'])
end
return result.uniq
end
def cuillen? orderID
talisker_total = 0.dollars
find_line_items_for_orderID(orderID).each do |row|
talisker_total += row['cost'].dollars if 'Talisker' == row['product']
end
return (talisker_total > 5000.dollars)
end
這兩個方法,cuillen_months 和 cuillen?,包含網域邏輯。它們使用許多向資料庫發出查詢的「尋找器」方法。
def find_customerID_named name
sql = 'SELECT * from customers where name = ?'
return $dbh.select_one(sql, name)['customerID']
end
def find_orders customerID
result = []
sql = 'SELECT * FROM orders WHERE customerID = ?'
$dbh.execute(sql, customerID) do |sth|
result = sth.collect{|row| row.dup}
end
return result
end
def find_line_items_for_orderID orderID
result = []
sql = 'SELECT * FROM lineItems l WHERE orderID = ?'
$dbh.execute(sql, orderID) do |sth|
result = sth.collect{|row| row.dup}
end
return result
end
在許多方面,這是一個非常簡單的方法,特別是它在使用 SQL 時非常沒有效率,需要多個查詢才能拉回資料(2 + N,其中 N 是訂單數量)。目前先不用太擔心,我稍後會說明如何改善。相反地,專注於方法的精髓:讀取所有必須考慮的資料,然後迴圈並選取所需資料。
(順帶一提,上面的網域邏輯是以這種方式完成,以便於閱讀,但這不是我認為符合慣例的 Ruby。我比較喜歡下面的方法,它更多地利用了 Ruby 強大的區塊和集合方法。這段程式碼對許多人來說看起來很奇怪,但 Smalltalker 應該會喜歡。)
def cuillen_months2 name
customerID = find_customerID_named(name)
qualifying_orders = find_orders(customerID).select {|row| cuillen?(row['orderID'])}
return (qualifying_orders.collect {|row| row['date'].month}).uniq
end
網域模型
對於第二個起點,我們將考慮一個傳統的物件導向網域模型。在這種情況下,我們會建立記憶體中的物件,在本例中會反映資料庫表格(在真實系統中,它們通常不是完全的鏡像)。一組尋找器物件會從資料庫載入這些物件,一旦我們在記憶體中取得物件,我們就會對它們執行邏輯。
我們將從尋找器開始。它們會對資料庫猛烈查詢並建立物件。
class CustomerMapper
def find name
result = nil
sql = 'SELECT * FROM customers WHERE name = ?'
return load($dbh.select_one(sql, name))
end
def load row
result = Customer.new(row['customerID'], row['NAME'])
result.orders = OrderMapper.new.find_for_customer result
return result
end
end
class OrderMapper
def find_for_customer aCustomer
result = []
sql = "SELECT * FROM orders WHERE customerID = ?"
$dbh.select_all(sql, aCustomer.db_id) {|row| result << load(row)}
load_line_items result
return result
end
def load row
result = Order.new(row['orderID'], row['date'])
return result
end
def load_line_items orders
#Cannot load with load(row) as connection gets busy
orders.each do
|anOrder| anOrder.line_items = LineItemMapper.new.find_for_order anOrder
end
end
end
class LineItemMapper
def find_for_order order
result = []
sql = "select * from lineItems where orderID = ?"
$dbh.select_all(sql, order.db_id) {|row| result << load(row)}
return result
end
def load row
return LineItem.new(row['lineNumber'], row['product'], row['cost'].to_i.dollars)
end
end
這些載入方法會載入下列類別
class Customer...
attr_accessor :name, :db_id, :orders
def initialize db_id, name
@db_id, @name = db_id, name
end
class Order...
attr_accessor :date, :db_id, :line_items
def initialize (id, date)
@db_id, @date, @line_items = id, date, []
end
class LineItem...
attr_reader :line_number, :product, :cost
def initialize line_number, product, cost
@line_number, @product, @cost = line_number, product, cost
end
確定 cuillen 月份的邏輯可以用幾個方法來描述。
class Customer...
def cuillenMonths
result = []
orders.each do |o|
result << o.date.month if o.cuillen?
end
return result.uniq
end
class Order...
def cuillen?
discountableAmount = 0.dollars
line_items.each do |line|
discountableAmount += line.cost if 'Talisker' == line.product
end
return discountableAmount > 5000.dollars
end
這個解決方案比交易指令碼版本長。然而,值得指出的是,載入物件的邏輯和實際網域邏輯更加分離。對這組網域物件的任何其他處理都會使用相同的載入邏輯。因此,如果我們執行許多不同的網域邏輯,載入邏輯的努力將攤銷到所有網域邏輯,這將使其不再成為問題。這種成本可以透過元資料對應等技術進一步降低。
同樣地,有很多 SQL 查詢(2 + 訂單數量)。
SQL 中的邏輯
對於前兩個,資料庫幾乎被用作儲存機制。我們所做的就是要求從特定表格取得所有記錄,並進行一些非常簡單的篩選。SQL 是一種非常強大的查詢語言,可以執行遠多於這些範例所使用的簡單篩選。
充分利用 SQL,我們可以在 SQL 中完成所有工作
def discount_months customerID
sql = <<-END_SQL
SELECT DISTINCT MONTH(o.date) AS month
FROM lineItems l
INNER JOIN orders o ON l.orderID = o.orderID
INNER JOIN customers c ON o.customerID = c.customerID
WHERE (c.name = ?) AND (l.product = 'Talisker')
GROUP BY o.orderID, o.date, c.NAME
HAVING (SUM(l.cost) > 5000)
END_SQL
result = []
$dbh.select_all(sql, customerID) {|row| result << row['month']}
return result
end
儘管我將此稱為複雜查詢,但它僅相較於先前範例的簡單選取和 where 子句查詢而言複雜。SQL 查詢可以比這個複雜得多,儘管許多應用程式開發人員會迴避即使像這樣最小的複雜查詢。
檢視效能
人們考慮這類事情時,首先會想到的問題之一就是效能。就我個人而言,我不認為效能應該是首要考量。我的哲學是,大多數時候你都應該專注於撰寫可維護的程式碼。然後使用剖析器找出熱點,再用較快但較不清晰的程式碼取代那些熱點。我這麼做的主要原因是,在大部分的系統中,只有極少部分的程式碼實際上是效能關鍵,而改善結構良好的可維護程式碼的效能也容易得多。
但無論如何,讓我們先來考量效能取捨。在我那台小筆電上,複雜的 SQL 查詢執行速度比其他兩種方法快了二十倍。現在你無法從一台纖巧但老舊的筆電中得出資料中心伺服器效能的任何結論,但我會很驚訝如果複雜查詢的執行速度比記憶體中方法慢了不到一個數量級。
造成這種情況的部分原因是,記憶體中方法的撰寫方式在 SQL 查詢方面非常沒有效率。正如我在說明中指出的,每個方法都會針對客戶的每筆訂單發出 SQL 查詢,而我的測試資料庫中每個客戶都有上千筆訂單。
我們可以透過改寫記憶體中程式,讓它們使用單一 SQL 查詢,大幅降低這個負載。我將從交易腳本開始。
SQL = <<-END_SQL
SELECT * from orders o
INNER JOIN lineItems li ON li.orderID = o.orderID
INNER JOIN customers c ON c.customerID = o.customerID
WHERE c.name = ?
END_SQL
def cuillen_months customer_name
orders = {}
$dbh.select_all(SQL, customer_name) do |row|
process_row(row, orders)
end
result = []
orders.each_value do |o|
result << o.date.month if o.talisker_cost > 5000.dollars
end
return result.uniq
end
def process_row row, orders
orderID = row['orderID']
orders[orderID] = Order.new(row['date']) unless orders[orderID]
if 'Talisker' == row['product']
orders[orderID].talisker_cost += row['cost'].dollars
end
end
class Order
attr_accessor :date, :talisker_cost
def initialize date
@date, @talisker_cost = date, 0.dollars
end
end
這對交易腳本來說是一個相當大的變更,但它將速度提升了三倍。
我可以在網域模型中執行類似的技巧。這裡我們可以看到網域模型更複雜結構的優點。我只需要修改載入方法,網域物件本身的商業邏輯不需要變更。
class CustomerMapper
SQL = <<-END_SQL
SELECT c.customerID,
c.NAME as NAME,
o.orderID,
o.date as date,
li.lineNumber as lineNumber,
li.product as product,
li.cost as cost
FROM customers c
INNER JOIN orders o ON o.customerID = c.customerID
INNER JOIN lineItems li ON o.orderID = li.orderID
WHERE c.name = ?
END_SQL
def find name
result = nil
om = OrderMapper.new
lm = LineItemMapper.new
$dbh.execute (SQL, name) do |sth|
sth.each do |row|
result = load(row) if result == nil
unless result.order(row['orderID'])
result.add_order(om.load(row))
end
result.order(row['orderID']).add_line_item(lm.load(row))
end
end
return result
end
(當我說我不需要修改網域物件時,我說了一個小謊。為了獲得良好的效能,我需要變更客戶的資料結構,讓訂單以雜湊而非陣列儲存。但話說回來,這是一個非常獨立的變更,而且不會影響用於確定折扣的程式碼。)
這裡有幾點。首先,值得記住的是,記憶體中程式碼通常可以透過更智慧的查詢獲得提升。找出你是否多次呼叫資料庫,以及是否有辦法改用單一呼叫來執行,這總是有價值的。當你有一個網域模型時,這一點特別容易被忽略,因為人們通常一次只想到一個類別存取。(我甚至看過有人一次只載入單一行,但這種病態行為相對罕見。)
交易腳本和網域模型之間最大的差異之一在於變更查詢結構的影響。對於交易腳本來說,這幾乎意味著變更整個腳本。此外,如果有很多使用類似資料的網域邏輯腳本,則每個腳本都必須變更。使用網域模型,你可以變更程式碼中一個分隔良好的區段,而網域邏輯本身不必變更。如果你有很多網域邏輯,這將是一件大事。這是交易腳本和網域邏輯之間的一般取捨 - 如果你有大量的網域邏輯,則資料庫存取的複雜性會產生初始成本。
但即使使用多表格查詢,記憶體中方法仍然不如複雜的 SQL 快 - 在我的案例中,慢了 6 倍。這是有道理的:複雜的 SQL 在資料庫中執行成本的選擇和加總,並且只需要將少數值傳送回用戶端,而記憶體中方法需要將五千列資料傳送回用戶端。
效能並非決定採用何種途徑的唯一因素,但通常是最後的因素。如果你有一個絕對需要改善的熱點,那麼其他因素就其次了。因此,許多網域模型的愛好者遵循預設在記憶體中執行的系統,並且僅在必要時使用複雜查詢等方法來處理熱點。
值得指出的是,這個範例是發揮資料庫優勢的範例。許多查詢沒有像這個範例中那麼強烈的選擇和彙總元素,並且不會顯示出這樣的效能變更。此外,多使用者場景通常會對查詢行為方式造成令人驚訝的變更,因此必須在實際的多使用者負載下進行實際設定檔分析。你可能會發現鎖定問題比你可以透過更快的個別查詢獲得的任何好處都更重要。
可修改性
對於任何長壽的企業應用程式,你可以確定一件事 - 它會發生很多變化。因此,你必須確保系統以易於變更的方式組織。可修改性可能是人們將業務邏輯放入記憶體中的主要原因。
SQL 可以做很多事情,但其功能有限。它可以做的一些事情需要相當聰明的編碼,例如瀏覽資料集的中位數演算法。其他事情在不使用非標準擴充功能的情況下是不可能做到的,如果你想要可移植性,這是一個問題。
你通常希望在將資料寫入資料庫之前執行業務邏輯,特別是如果你正在處理一些待處理資訊時。載入資料庫可能會出現問題,因為你通常希望待處理的階段資料與完全接受的資料隔離。這些階段資料通常不應受到與完全接受的資料相同的驗證規則約束。
可理解性
SQL 通常被視為一種特殊語言,應用程式開發人員不應該需要處理它。事實上,許多資料庫架構都喜歡說,透過使用它們,你可以避免需要處理 SQL。我總是發現這是一個有點奇怪的論點,因為我對中等複雜度的 SQL 一直都很自在。然而,許多開發人員發現 SQL 比傳統語言更難處理,而且許多 SQL 慣用語對於除了 SQL 專家之外的人來說都很難理解。
對你來說,一個好的測試是檢視這三種解決方案,並找出哪一種讓網域邏輯最容易遵循,因此最容易修改。我發現網域模型版本(僅有幾個方法)最容易遵循;在很大程度上,這是因為資料存取已分開。接下來,我比較喜歡 SQL 版本,而不是記憶體內交易指令碼。但我確定其他讀者會有其他偏好。
如果團隊中的大多數人都不太熟悉 SQL,那麼這是一個將網域邏輯遠離 SQL 的理由。(這也是考慮對更多人進行 SQL 訓練的理由 - 至少達到中級程度。)這是一種情況,你必須考慮團隊的組成 - 人員確實會影響架構決策。
避免重複
我遇到過最簡單但最有力的設計原則之一就是避免重複 - 由 實用程式設計師 制定為 DRY(不要重複自己)原則。
為了思考此案例的 DRY 原則,我們來考慮此應用程式的另一個需求 - 特定月份客戶的訂單清單,顯示訂單 ID、日期、總成本,以及此訂單是否是 Cuillen 計畫的合格訂單。所有這些都按總成本排序。
使用網域物件方法來處理此查詢,我們需要新增一個方法到訂單中,以計算總成本。
class Order...
def total_cost
result = 0.dollars
line_items.each {|line| result += line.cost}
return result
end
有了這個方法,列印訂單清單就很容易了
class Customer
def order_list month
result = ''
selected_orders = orders.select {|o| month == o.date.month}
selected_orders.sort! {|o1, o2| o2.total_cost <=> o1.total_cost}
selected_orders.each do |o|
result << sprintf("%10d %20s %10s %3s\n",
o.db_id, o.date, o.total_cost, o.discount?)
end
return result
end
使用單一 SQL 陳述式定義相同的查詢需要一個相關子查詢 - 有些人會覺得這很困難。
def order_list customerName, month
sql = <<-END_SQL
SELECT o.orderID, o.date, sum(li.cost) as totalCost,
CASE WHEN
(SELECT SUM(li.cost)
FROM lineitems li
WHERE li.product = 'Talisker'
AND o.orderID = li.orderID) > 5000
THEN 'Y'
ELSE 'N'
END AS isCuillen
FROM dbo.CUSTOMERS c
INNER JOIN dbo.orders o ON c.customerID = o.customerID
INNER JOIN lineItems li ON o.orderID = li.orderID
WHERE (c.name = ?)
AND (MONTH(o.date) = ?)
GROUP by o.orderID, o.date
ORDER BY totalCost desc
END_SQL
result = ""
$dbh.select_all(sql, customerName, month) do |row|
result << sprintf("%10d %20s %10s %3s\n",
row['orderID'],
row['date'],
row['totalCost'],
row['isCuillen'])
end
return result
end
不同的人對於這兩個哪一個最容易理解會有不同的看法。但我在此咀嚼的問題是重複。此查詢重複了原始查詢的邏輯,該查詢僅提供月份。網域物件方法沒有這種重複 - 如果我想變更 Cuillen 計畫的定義,我所要做的就是變更 cuillen? 的定義,所有用途都會更新。
現在,在重複問題上批評 SQL 並不公平 - 因為你也可以在豐富的 SQL 方法中避免重複。資料庫愛好者一定會急著指出,訣竅是使用檢視。
我可以定義一個檢視,為了簡單起見,稱為 Orders2,基於以下查詢。
SELECT TOP 100 PERCENT
o.orderID, c.name, c.customerID, o.date,
SUM(li.cost) AS totalCost,
CASE WHEN
(SELECT SUM(li2.cost)
FROM lineitems li2
WHERE li2.product = 'Talisker'
AND o.orderID = li2.orderID) > 5000
THEN 'Y'
ELSE 'N'
END AS isCuillen
FROM dbo.orders o
INNER JOIN dbo.lineItems li ON o.orderID = li.orderID
INNER JOIN dbo.CUSTOMERS c ON o.customerID = c.customerID
GROUP BY o.orderID, c.name, c.customerID, o.date
ORDER BY totalCost DESC
現在我可以同時使用這個檢視來取得月份和產生訂單清單
def cuillen_months_view customerID
sql = "SELECT DISTINCT month(date) FROM orders2 WHERE name = ? AND isCuillen = 'Y'"
result = []
$dbh.select_all(sql, customerID) {|row| result << row[0]}
return result
end
def order_list_from_view customerName, month
result = ''
sql = "SELECT * FROM Orders2 WHERE name = ? AND month(date) = ?"
$dbh.select_all(SQL, customerName, month) do |row|
result << sprintf("%10d %10s %10s\n",
row['orderID'],
row['date'],
row['isCuillen'])
end
return result
end
這個檢視簡化了查詢,並將關鍵商業邏輯集中在單一位置。
似乎很少人討論使用這種檢視來避免重複。我所看過的 SQL 書籍似乎沒有討論這種作法。在某些環境中,這很困難,因為資料庫和應用程式開發人員之間存在組織和文化上的分歧。通常,應用程式開發人員不被允許定義檢視,而資料庫開發人員形成瓶頸,阻礙應用程式開發人員完成這種檢視。DBA 甚至可能拒絕建立僅由單一應用程式需要的檢視。但我的看法是,SQL 值得像其他任何事物一樣仔細設計。
封裝
封裝是物件導向設計中一個著名的原則,我認為它很適用於一般的軟體設計。它基本上表示程式應該被分割成模組,這些模組會將資料結構隱藏在程序呼叫介面之後。這樣做的目的是讓您可以在不造成系統產生大量漣漪效應的情況下變更基礎資料結構。
在這種情況下,問題是如何封裝資料庫?一個好的封裝架構可以讓我們變更資料庫架構,而不會造成應用程式中痛苦的編輯循環。
對於企業應用程式,封裝的一種常見形式是分層,我們努力將網域邏輯與資料來源邏輯分開。這樣一來,當我們變更資料庫設計時,處理商業邏輯的程式碼就不會受到影響。
網域模型版本就是這種封裝的一個好範例。商業邏輯只處理記憶體中的物件。資料如何到達那裡完全是分開的。交易腳本方法透過尋找方法具有一定的資料庫封裝,儘管資料庫結構更透過傳回的結果集揭露出來。
在應用程式世界中,您透過程序和物件的 API 來達成封裝。SQL 等效的方式是使用檢視。如果您變更一個表格,您可以建立一個支援舊表格的檢視。這裡最大的問題在於更新,通常無法透過檢視正確地執行更新。這就是許多商店用儲存程序包裝所有 DML 的原因。
封裝不只是支援檢視變更而已。它也關於存取資料與定義商業邏輯之間的差異。使用 SQL,兩者可以輕易地模糊不清,但您仍然可以進行某種形式的區分。
例如,考慮我在上面定義的檢視,以避免查詢中的重複。該檢視是一個單一檢視,可以沿著資料來源和商業邏輯區分的界線進行分割。資料來源檢視看起來像這樣
SELECT o.orderID, o.date, c.customerID, c.name,
SUM(li.cost) AS total_cost,
(SELECT SUM(li2.cost)
FROM lineitems li2
WHERE li2.product = 'Talisker' AND o.orderID =li2.orderID
) AS taliskerCost
FROM dbo.CUSTOMERS c
INNER JOIN dbo.orders o ON c.customerID = o.customerID
INNER JOIN dbo.lineItems li ON li.orderID = o.orderID
GROUP BY o.orderID, o.date, c.customerID, c.name
然後我們可以在更注重網域邏輯的其他檢視中使用此檢視。以下是表示 Cuillen 資格的一個檢視
SELECT orderID, date, customerID, name, total_cost,
CASE WHEN taliskerCost > 5000 THEN 'Y' ELSE 'N' END AS isCuillen
FROM dbo.OrdersTal
這種思考方式也可以應用於我們將資料載入網域模型的情況。稍早我談到如何透過採用 Cuillen 月份的整個查詢並用單一 SQL 查詢取代它,來處理網域模型的效能問題。另一種方法是使用上述資料來源檢視。這將允許我們在網域模型中保留網域邏輯的同時,保持較高的效能。線性項目僅在必要時使用延遲載入載入,但適當的摘要資訊可以透過檢視載入。
使用檢視或儲存程序僅在某個程度提供封裝。在許多企業應用程式中,資料來自多個來源,不只是多個關聯式資料庫,還有舊系統、其他應用程式和檔案。事實上,XML 的成長可能會看到更多資料來自透過網路共用的平面檔案。在這種情況下,真正的完整封裝只能由應用程式程式碼內的層級來完成,這進一步暗示網域邏輯也應該存在於記憶體中。
資料庫可攜性
許多開發人員迴避複雜 SQL 的一個原因是資料庫可移植性的問題。畢竟 SQL 的承諾是它允許您在大量的資料庫平台上使用相同的標準 SQL,讓您能夠輕鬆地變更資料庫供應商
實際上,這一直有點模糊不清。在實務上,SQL 大多是標準的,但有各種各樣的小地方會讓您絆倒。然而,只要小心,您就可以建立在資料庫伺服器之間轉移時不會太痛苦的 SQL。但要做到這一點,您會失去許多功能。
關於資料庫可移植性的決策最終會針對您的專案而定。現在這已不再像以前那樣是一個問題。資料庫市場已經穩定下來,因此大多數地方都屬於三大陣營之一。企業通常對他們所在的陣營有強烈的承諾。如果您認為由於這種投資而變更資料庫的可能性很低,您不妨開始利用您的資料庫提供的特殊功能。
有些人仍然需要可移植性,例如提供可以安裝並與多個資料庫介接的產品的人。在這種情況下,有一個更強的論點反對將邏輯放入 SQL,因為您必須非常小心您能安全使用的 SQL 部分。
可測試性
可測試性並非在設計討論中常被提及的主題。測試驅動開發(TDD)的其中一個好處是它重新點燃了可測試性是設計中重要部分的概念。
SQL 中的常見做法似乎是不測試。事實上,發現重要的檢視和儲存程序甚至沒有保存在組態管理工具中是很常見的。然而,要擁有可測試的 SQL 絕對是有可能的。廣受歡迎的 xunit 系列有許多工具可用於在資料庫環境中進行測試。演化式資料庫技術(例如測試資料庫)可用於提供一個可測試的環境,這與 TDD 程式設計師所享受的環境非常類似。
可以產生差異的主要領域是效能。雖然直接 SQL 在生產環境中通常較快,但如果資料庫介面是以一種可以將實際資料庫連線替換為 服務 Stub 的方式設計,則在記憶體中執行商業邏輯的測試可能會快得多。
總結
到目前為止,我已經討論了這些問題。現在是時候得出結論了。基本上,你必須考慮我這裡討論的各種問題,根據你的偏見來判斷它們,並決定採用哪些政策來使用豐富的查詢並將網域邏輯放在其中。
我觀察這個問題的方式,其中一個最關鍵的元素是你的資料是來自單一的邏輯關聯式資料庫,還是分散在大量不同的(通常是非 SQL)來源中。如果它是分散的,則你應該在記憶體中建立一個資料來源層來封裝你的資料來源,並將你的網域邏輯保存在記憶體中。在這種情況下,SQL 作為一種語言的優點並不是問題,因為並非你所有的資料都在 SQL 中。
當你的資料絕大部分都位於單一邏輯資料庫中時,情況就變得有趣了。在這種情況下,你必須考慮兩個主要問題。一個是程式語言的選擇:SQL 與你的應用程式語言。另一個是程式碼執行的位址,資料庫中的 SQL,還是記憶體中。
SQL 讓某些事情變得容易,但讓其他事情變得更困難。有些人覺得 SQL 很容易使用,而另一些人則覺得它非常難懂。團隊的個人舒適度在這裡是一個大問題。我建議,如果你選擇在 SQL 中放入大量邏輯,不要期望具有可移植性 - 使用你所有供應商的擴充功能,並愉快地將自己綁定到他們的技術。如果你想要可移植性,請將邏輯排除在 SQL 之外。
到目前為止,我已經討論了可修改性的問題。我認為這些問題應該優先考慮,但會被任何關鍵的效能問題所取代。如果你使用記憶體中方法,並且有可以透過更強大的查詢來解決的熱點,那就這樣做。我建議看看你可以將多少效能提升查詢組織為資料來源查詢,如我上面所述。這樣,你可以將網域邏輯放入 SQL 的程度降到最低。
重大修訂
2003 年 2 月