
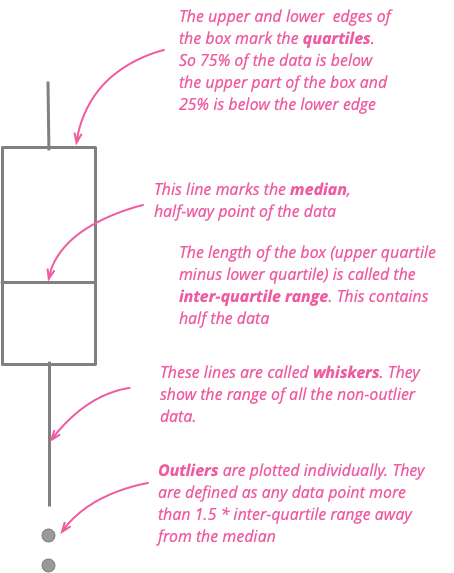
不要比較平均值
僅使用平均值來比較數字群組會隱藏許多見解
在業務會議中,通常會透過比較平均值來比較數字群組。但這麼做常常會隱藏這些群組中數字分佈中的重要資訊。有許多資料視覺化可以清楚呈現這些資訊。這些視覺化包括帶狀圖、直方圖、密度圖、盒狀圖和小提琴圖。這些視覺化很容易使用免費的軟體製作,適用於小至十幾個、大至數千個的群組。
2020 年 9 月 24 日

想像一下,你是位主管,而你被要求決定要頒發大獎項/升遷/獎金給哪位銷售主管。你的公司是一家資本主義公司,只重視營收,因此你決策中的關鍵要素是誰在今年獲得最多的營收成長。(由於現在是 2020 年,或許我們賣的是口罩。)
以下是極為重要的數字。
| 姓名 | 平均營收成長率 (%) |
|---|---|
| 愛麗絲 | 5.0 |
| 鮑伯 | 7.9 |
| 克拉拉 | 5.0 |
以及一張彩色圖表
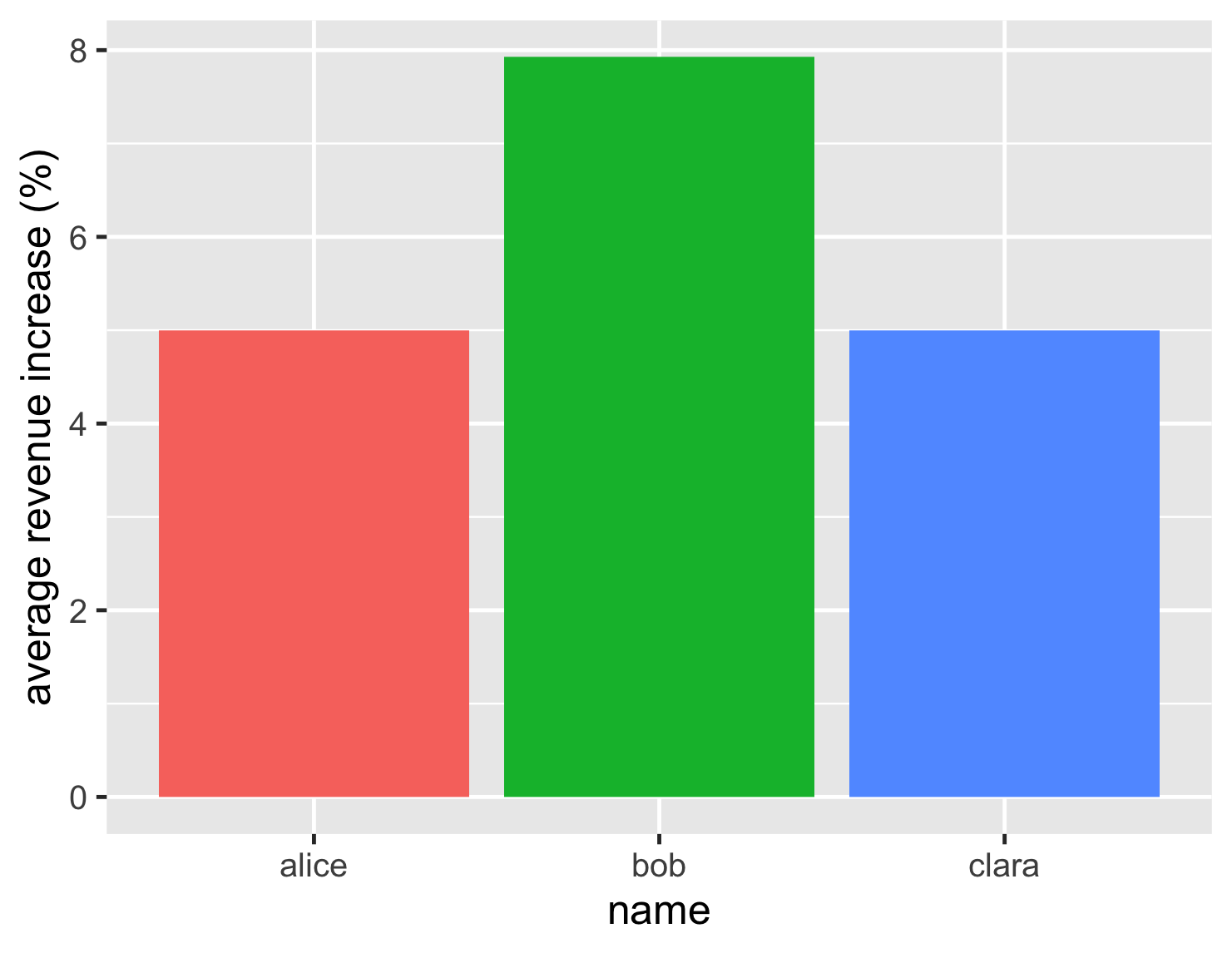
根據這些資料,這個決策看起來很容易。鮑伯的營收成長率略低於 8%,顯著優於僅有 5% 的競爭對手。
但讓我們深入探討,並查看每位銷售人員的個別帳戶。
| 姓名 | 帳戶營收成長率 (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 愛麗絲 | -1.0 | 2.0 | 1.0 | -3.0 | -1.0 | 10.0 | 13.0 | 8.0 | 11.0 | 10.0 |
| 鮑伯 | -0.5 | -2.5 | -6.0 | -1.5 | -2.0 | -1.8 | -2.3 | 80.0 | ||
| 克拉拉 | 3.0 | 7.0 | 4.5 | 5.5 | 4.8 | 5.0 | 5.2 | 4.0 | 6.0 | 5.0 |
這些帳戶層級的資料說明了一個不同的故事。鮑伯的高績效是因為一個帳戶產生了高達 80% 的營收成長。他所有其他帳戶都縮減了。由於鮑伯的績效僅來自一個帳戶,他真的是最適合獲得獎金的銷售人員嗎?
鮑伯的故事是比較任何資料點群組時,僅查看平均值會遇到的最大問題之一。通常的平均值,技術上來說是平均數,很容易受到一個異常值影響而大幅改變。請記住,當比爾蓋茲進入房間後,一百位無家可歸者的平均淨資產就會變成 10 億美元。
詳細的帳戶資料揭露了另一個差異。儘管愛麗絲和克拉拉的平均值相同,但他們的帳戶資料說明了兩個截然不同的故事。愛麗絲不是非常成功(約 10%),就是表現平平(約 2%),而克拉拉則持續表現平穩(約 5%)。僅查看平均值會隱藏這個重要的差異。
到此為止,任何研究過統計學或資料視覺化的人,都對我這個「明白先生」翻白眼。但這項知識並未傳達給企業界人士。我在商業簡報中經常看到比較平均值的長條圖。因此我決定撰寫這篇文章,展示一系列可供您探索此類資訊的視覺化方式,獲得單靠平均值無法提供的見解。在這樣做的過程中,我希望能夠說服一些人停止僅使用平均值,並在看到其他人這樣做時質疑平均值。畢竟,除非您知道如何正確檢查資料,否則熱切收集成為資料導向企業所需的資料毫無意義。
帶狀圖顯示所有個別數字
因此,規則是當您不知道資料的實際分佈為何時,不要比較平均值。您如何才能對資料有良好的了解?
當我們沒有太多資料點時,我將從上述情況開始。通常,最好的方法是使用長條圖,它將顯示不同群體中的每個資料點。
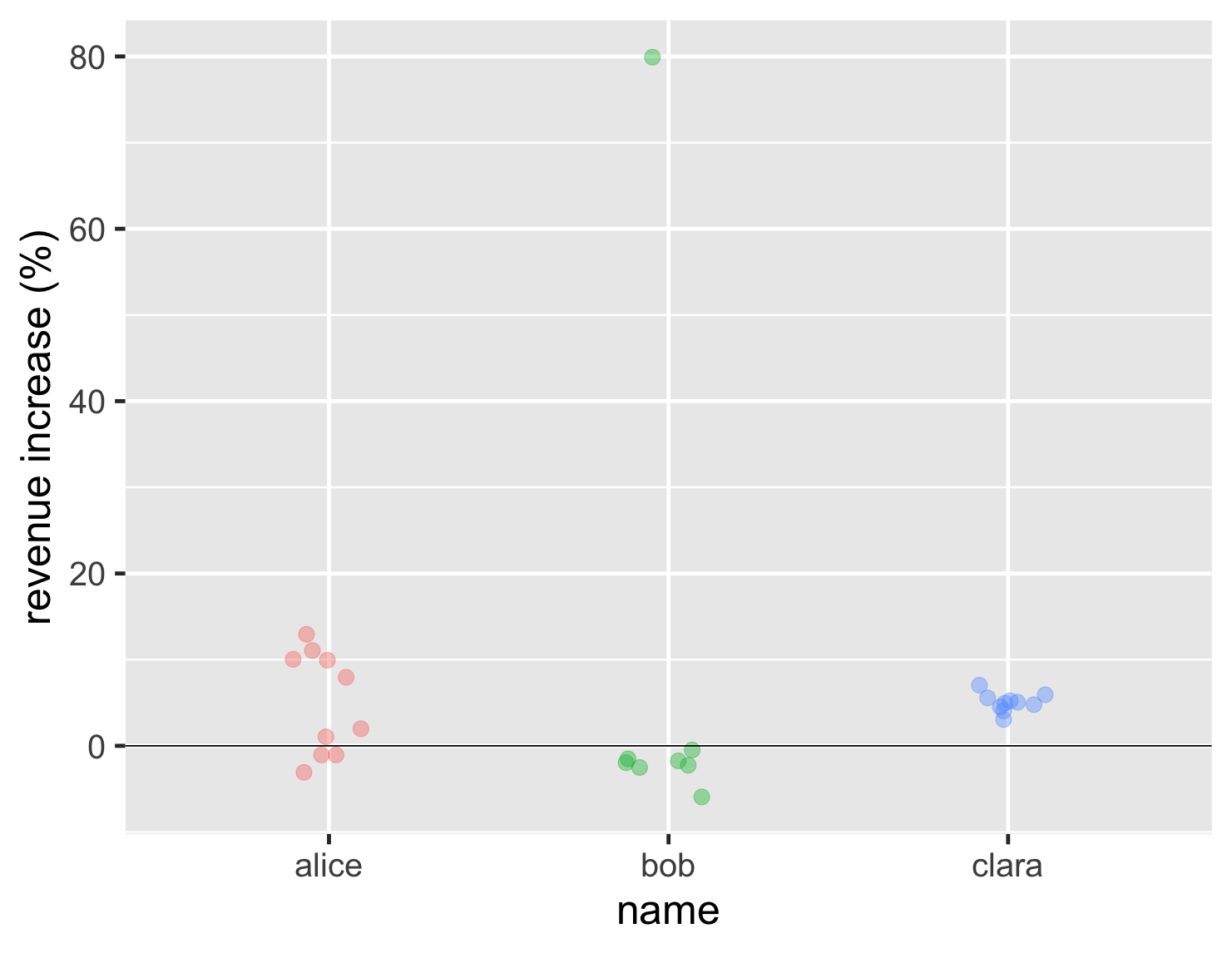
顯示程式碼
ggplot(sales, aes(name, d_revenue, color=name)) + geom_jitter(width=0.15, alpha = 0.4, size=5, show.legend=FALSE) + ylab(label = "revenue increase (%)") + geom_hline(yintercept = 0) + theme_grey(base_size=30)
有了這個圖表,我們現在可以清楚地看到 Bob 的孤獨高點,他的大多數結果與 Alice 最差的結果相似,並且 Clara 的表現更為一致。這告訴我們遠遠超過先前的長條圖,但實際上並不容易解讀。
您可能會問,如何繪製這種漂亮的條形圖?大多數想要繪製一些快速圖表的人會使用 Excel 或其他試算表。我不知道在一般試算表中繪製條形圖有多容易,因為我不是試算表的使用者。根據我在管理簡報中看到的,這可能是不可行的,因為我幾乎從未看過。對於我的繪圖,我使用 R,這是一個令人害怕的強大統計套件,由熟悉「Kendall 等級相關係數」和「Mann-Whitney U 檢定」等詞彙的人使用。然而,儘管有這些可怕的武器,但對於簡單的資料處理和圖形繪製來說,使用 R 系統相當容易。它是由學者開發的開源軟體,因此您可以下載並使用它,而不用擔心授權成本和採購流程。對於開源世界來說,它有優秀的文件和教學課程,可以學習如何使用它。(如果您是 Pythonista,還有一系列精良的 Python 函式庫可以執行所有這些事情,儘管我沒有深入研究過這個領域。)如果您對 R 感到好奇,我在附錄中有一個摘要,說明我如何學習我所知道的關於它的知識。
如果您有興趣了解我如何產生我在這裡展示的各種圖表,我在每個圖表後都包含了一個「顯示程式碼」揭露,其中顯示了繪製圖表的命令。所使用的銷售資料框有兩欄:名稱和 d_revenue。
如果我們有更多資料點需要考慮呢?想像一下,我們的三人組現在變得更重要了,每個人都處理數百個帳戶。然而,他們的分布仍然顯示出相同的基本特徵,我們可以從新的條形圖中看到這一點。
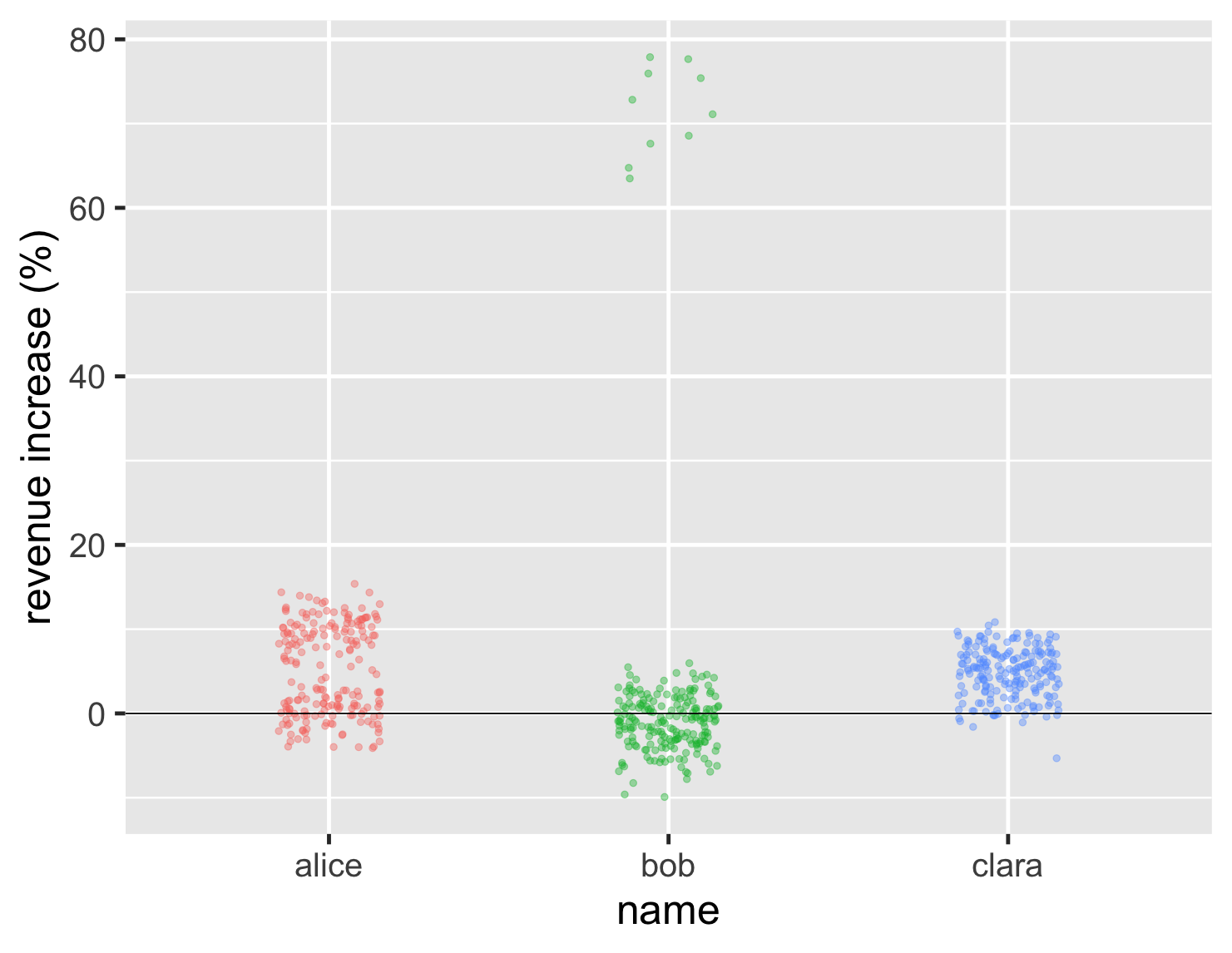
顯示程式碼
ggplot(large_sales, aes(name, value, color=name)) + geom_jitter(width=0.15, alpha = 0.4, size=2, show.legend=FALSE) + ylab(label = "revenue increase (%)") + geom_hline(yintercept = 0) + theme_grey(base_size=30)
然而,條形圖有一個問題,就是我們看不到平均值。因此,我們無法判斷 Bob 的高值是否足以彌補這些一般的低點。我可以透過在圖表上繪製平均點來解決這個問題,在本例中為黑色菱形。
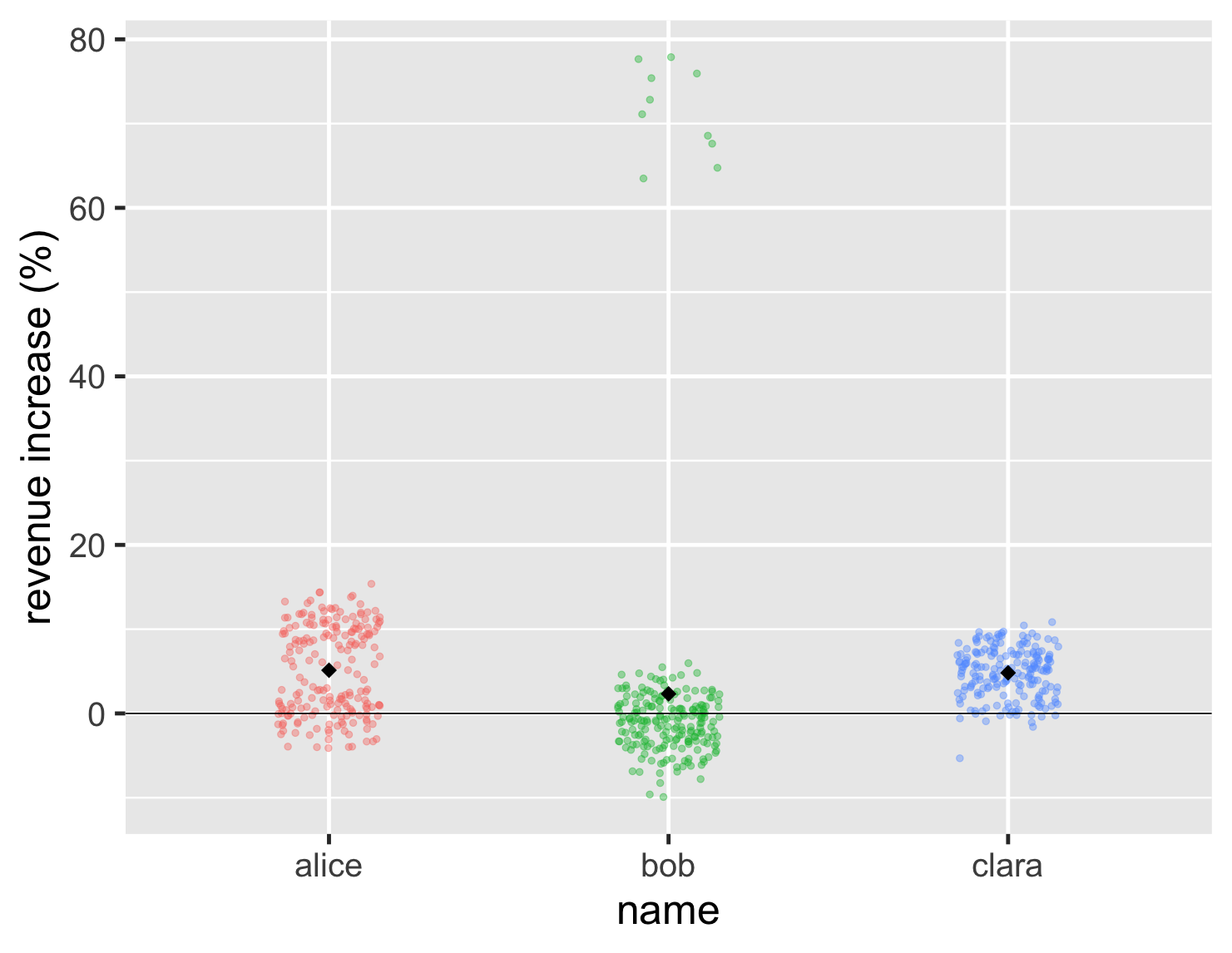
顯示程式碼
ggplot(large_sales, aes(name, value, color=name)) + geom_jitter(width=0.15, alpha = 0.4, size=2, show.legend=FALSE) + ylab(label = "revenue increase (%)") + geom_hline(yintercept = 0) + stat_summary(fun = "mean", size = 5, geom = "point", shape=18, color = 'black') + theme_grey(base_size=30)
因此,在這種情況下,Bob 的平均值比其他兩個低一點。
這表明,即使我常常貶低那些使用平均值來比較群組的人,但我並不認為平均值是無用的。我鄙視的是那些只使用平均值,或在不檢查整體分布的情況下使用平均值的人。某種平均值通常是比較的有用元素,但更常地,中位數實際上是更好的中心點,因為它能更好地應對像 Bob 這樣的巨大異常值。每當您看到「平均值」時,您都應該考慮哪個更好:中位數還是平均數?
中位數之所以成為一個使用不足的函式,通常是因為我們的工具不鼓勵我們使用它。SQL,主要的資料庫查詢語言,附帶了一個內建的 AVG 函式,用於計算平均值。然而,如果您想要中位數,您通常會註定要搜尋一些相當醜陋的演算法,除非您的資料庫有載入擴充函式的功能。[1] 如果有一天我成為最高領導人,我將規定,除非平台也提供中位數,否則不能有平均值函式。
使用直方圖查看分佈形狀
雖然使用條形圖是立即了解資料樣貌的好方法,但其他圖表可以幫助我們以不同方式比較資料。我注意到的一件事是,許多人想使用單一圖表來顯示特定資料集。但每種圖表都會說明資料集的不同特徵,明智的做法是使用多個圖表來了解資料可能在告訴我們什麼。在我探索資料時,這當然是正確的,試著了解資料在告訴我什麼。但即使在傳達資料時,我也會使用多個圖表,以便我的讀者可以看到資料所傳達的不同面向。
直方圖是檢視分布的經典方式。以下是大型資料集的直方圖。
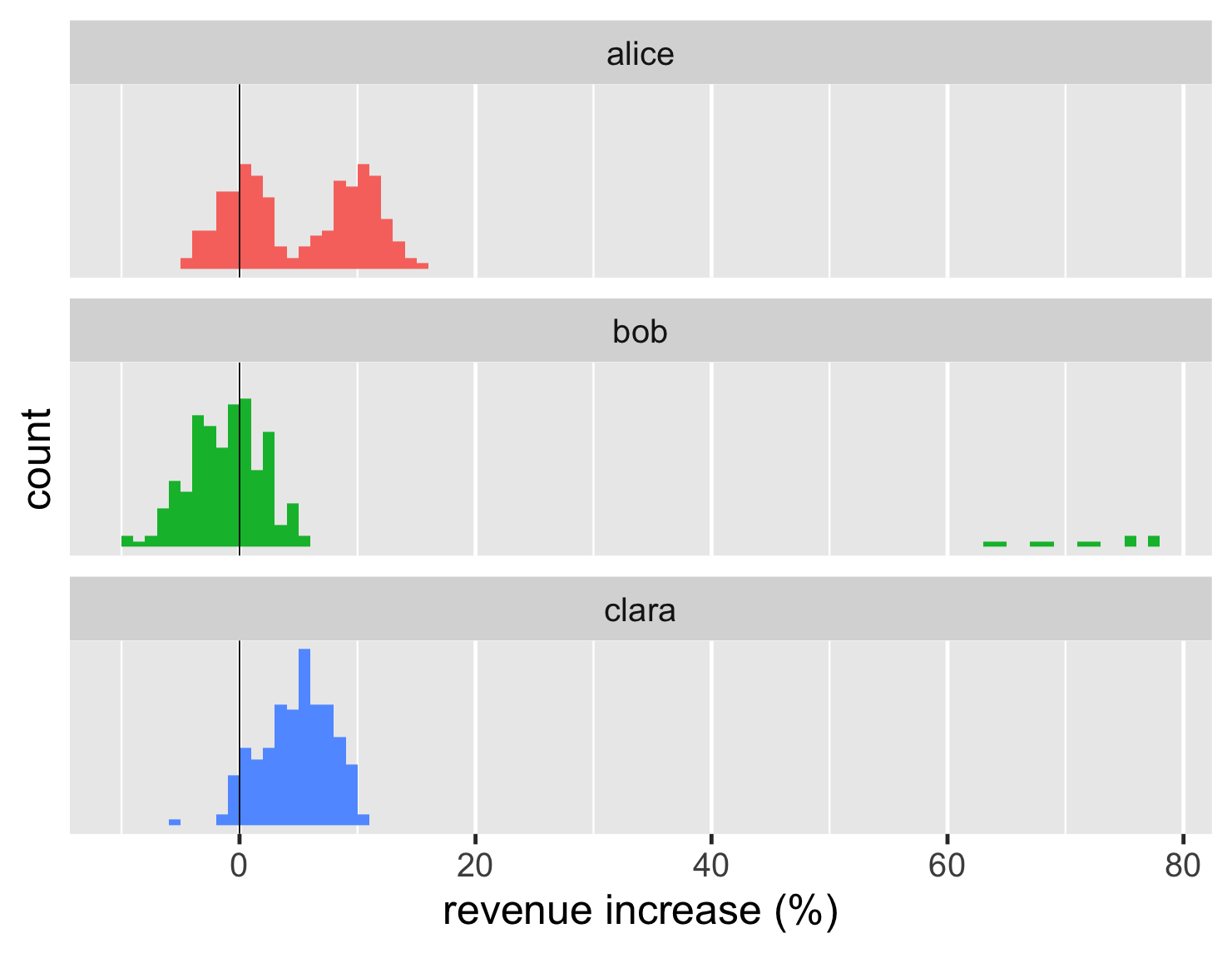
顯示程式碼
ggplot(large_sales, aes(value, fill=name)) + geom_histogram(binwidth = 1, boundary=0, show.legend=FALSE) + xlab(label = "revenue increase (%)") + scale_y_continuous(breaks = c(50,100)) + geom_vline(xintercept = 0) + theme_grey(base_size=30) + facet_wrap(~ name,ncol=1)
直方圖非常適合顯示單一分布的形狀。因此,很容易看出愛麗絲的交易分為兩個不同的區塊,而克拉拉的交易只有一個區塊。從條形圖中也可以很容易地看到這些形狀,但直方圖可以更清楚地說明形狀。
直方圖只顯示一個群組,但我在這裡顯示了幾個群組以進行比較。R 有此特殊功能,稱為分面圖。這種「小倍數」(由愛德華·塔夫特創造的術語)對於比較非常方便。幸運的是,R 使得繪製它們變得容易。
視覺化分布形狀的另一種方式是密度圖,我認為它是直方圖的平滑曲線。
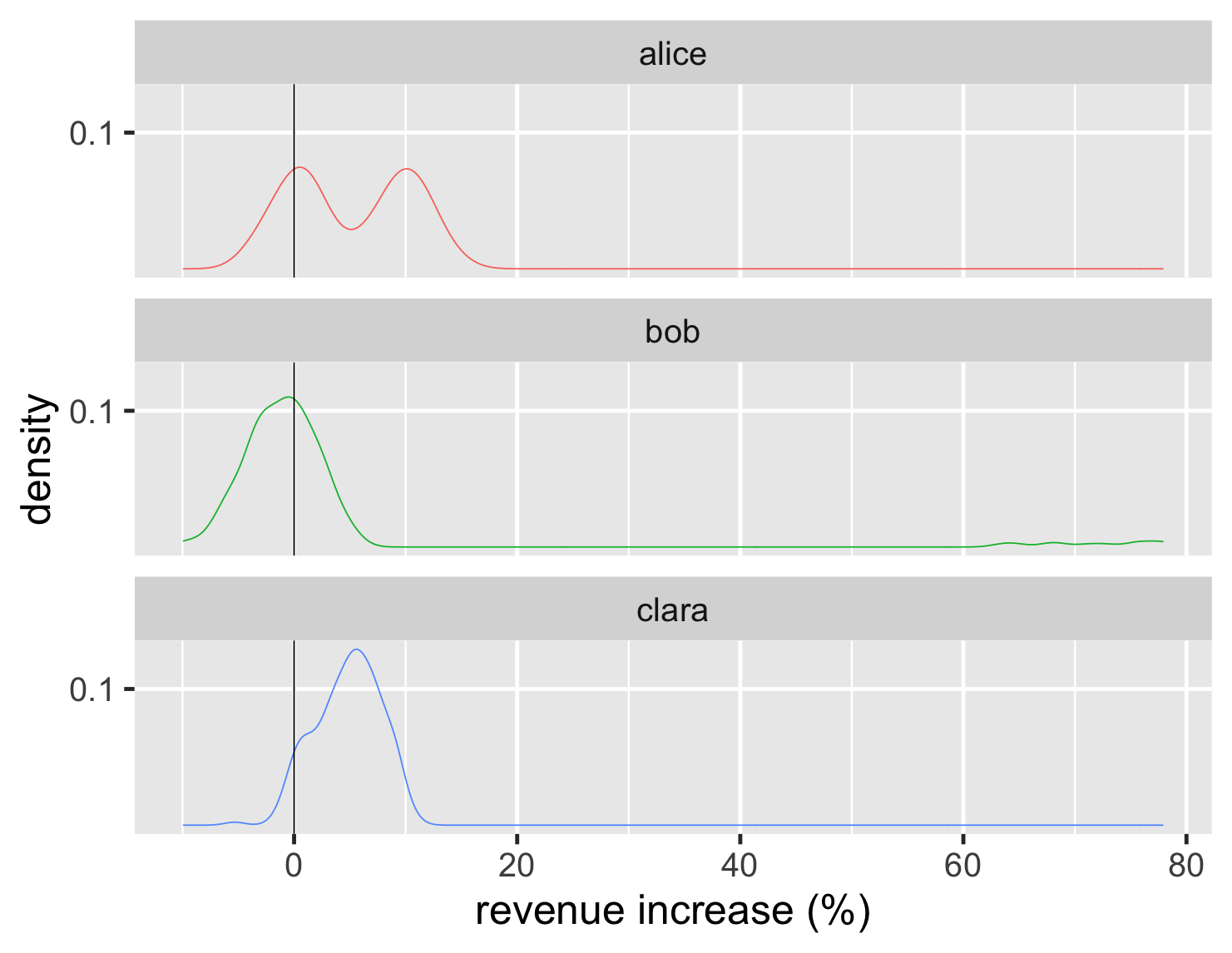
顯示程式碼
ggplot(large_sales, aes(value, color=name)) + geom_density(show.legend=FALSE) + geom_vline(xintercept = 0) + xlab(label = "revenue increase (%)") + scale_y_continuous(breaks = c(0.1)) + theme_grey(base_size=30) + facet_wrap(~ name,ncol=1)
y 軸上的密度比例對我來說沒有什麼意義,所以我傾向於從圖表中移除該比例 - 畢竟,這些圖表的關鍵元素是分布的形狀。此外,由於密度圖很容易呈現為線條,因此我可以在單一圖形上繪製所有密度圖。
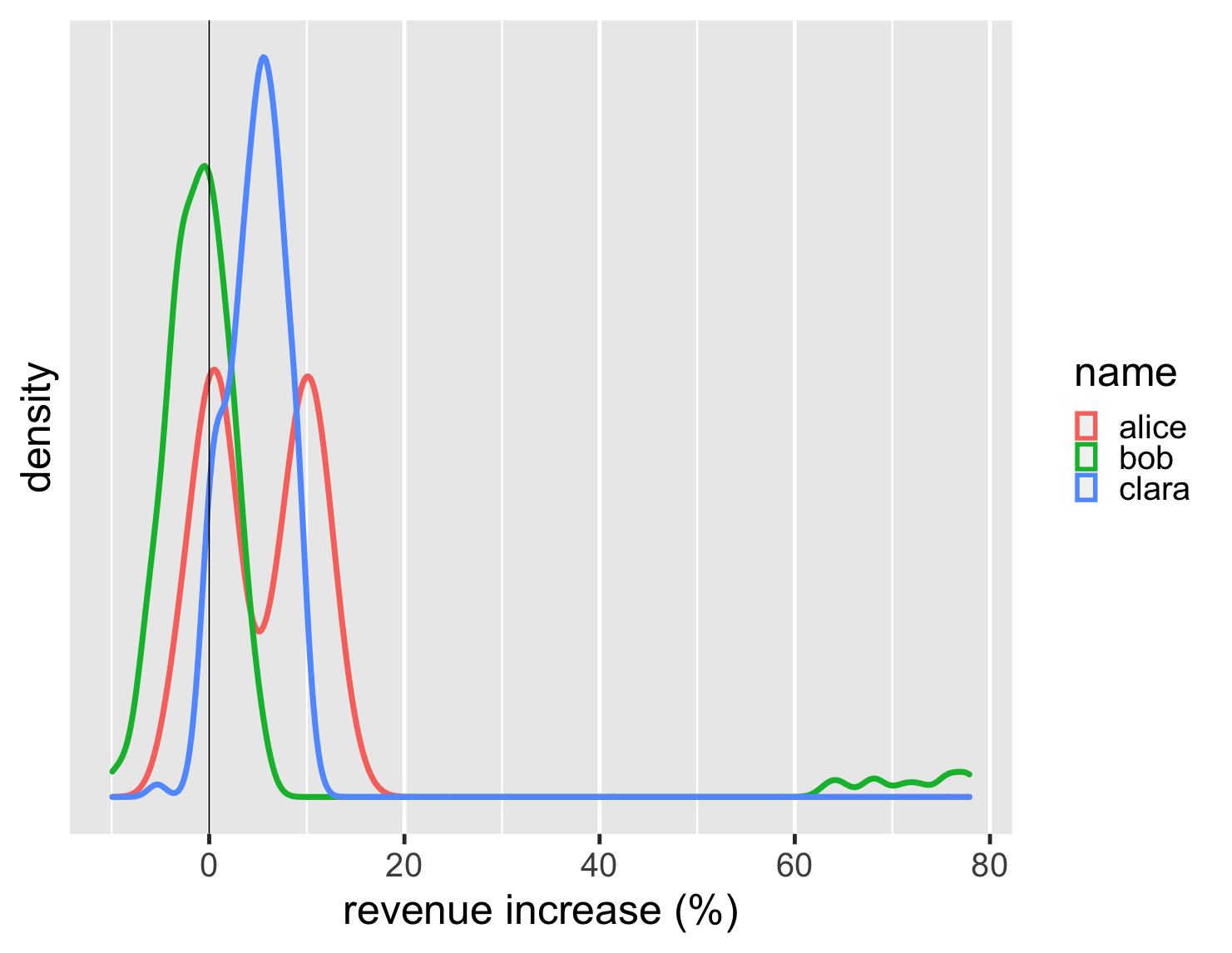
顯示程式碼
ggplot(large_sales, aes(value, color=name)) + geom_density(size=2) + scale_y_continuous(breaks = NULL) + xlab(label = "revenue increase (%)") + geom_vline(xintercept = 0) + theme_grey(base_size=30)
當資料點較多時,直方圖和密度圖會更有效,當資料點只有少數幾個時,它們就不太有幫助(例如第一個範例)。當只有少數幾個值時,計數條形圖很有用,例如評論網站上的 5 星評分。幾年前,亞馬遜為其評論新增了此類圖表,除了平均分數外,還顯示了分布。
盒狀圖適用於許多比較
直方圖和密度圖是比較不同分布形狀的好方法,但一旦我超過少數幾個圖形,它們就變得難以比較。了解分布中常見的範圍和位置也很有用。這正是箱形圖派上用場的地方。
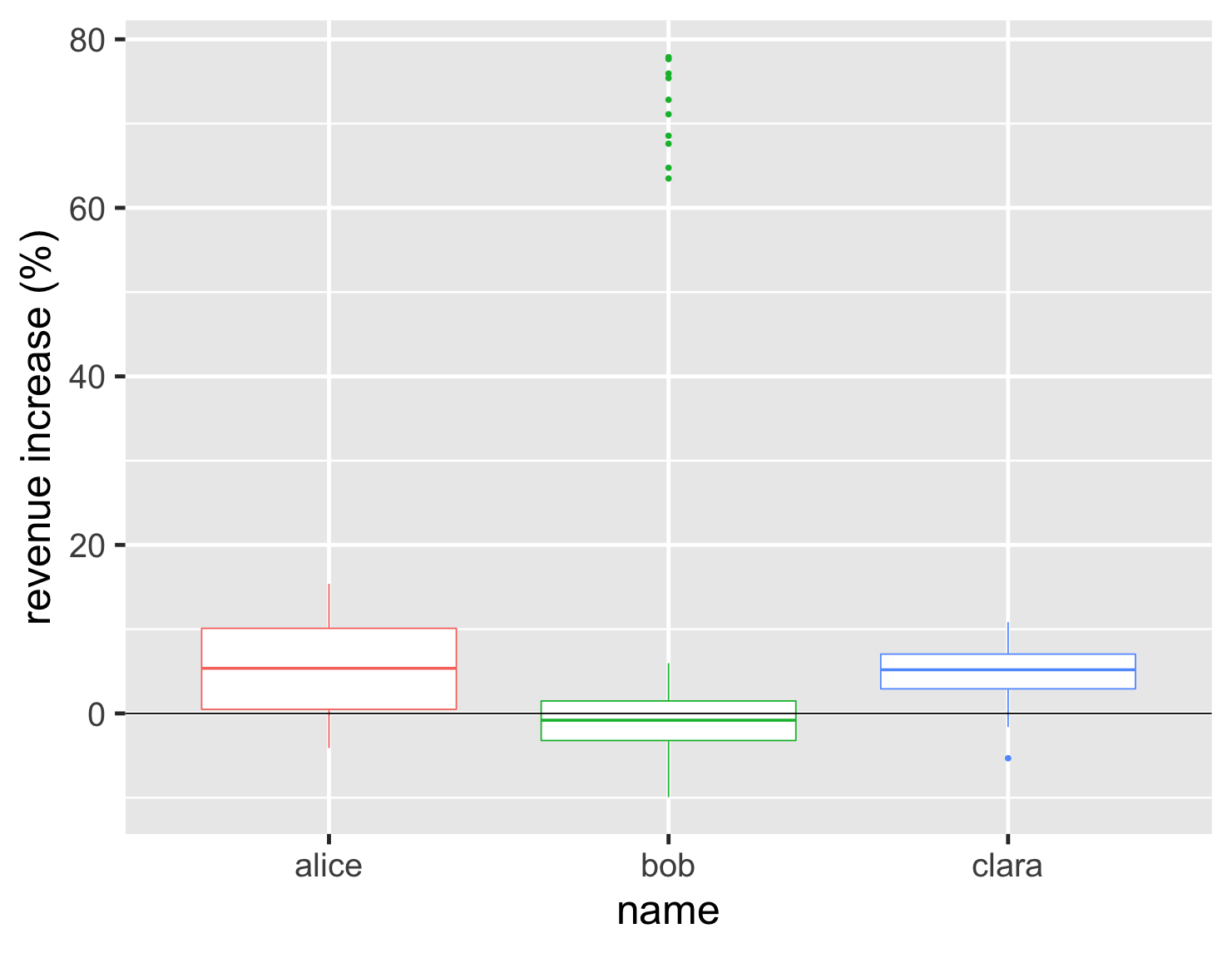
顯示程式碼
ggplot(large_sales, aes(name, value, color=name)) + geom_boxplot(show.legend=FALSE) + ylab(label = "revenue increase (%)") + geom_hline(yintercept = 0) + theme_grey(base_size=30)
箱型圖將我們的注意力集中在資料的中間範圍,因此一半的資料點都在方塊中。從圖表中,我們可以看到 Bob 的一半以上帳戶都縮水了,而他的上四分位數低於 Clara 的下四分位數。我們還看到他在圖表上端的一群熱門帳戶。
箱型圖非常適合用來比較幾十個項目,提供基礎資料的良好摘要。以下是一個範例。我在 1983 年搬到倫敦,十年後搬到波士頓。身為英國人,我自然會思考這兩個城市的氣候比較。因此,這裡有一個圖表,比較自 1983 年以來每個月的高溫。
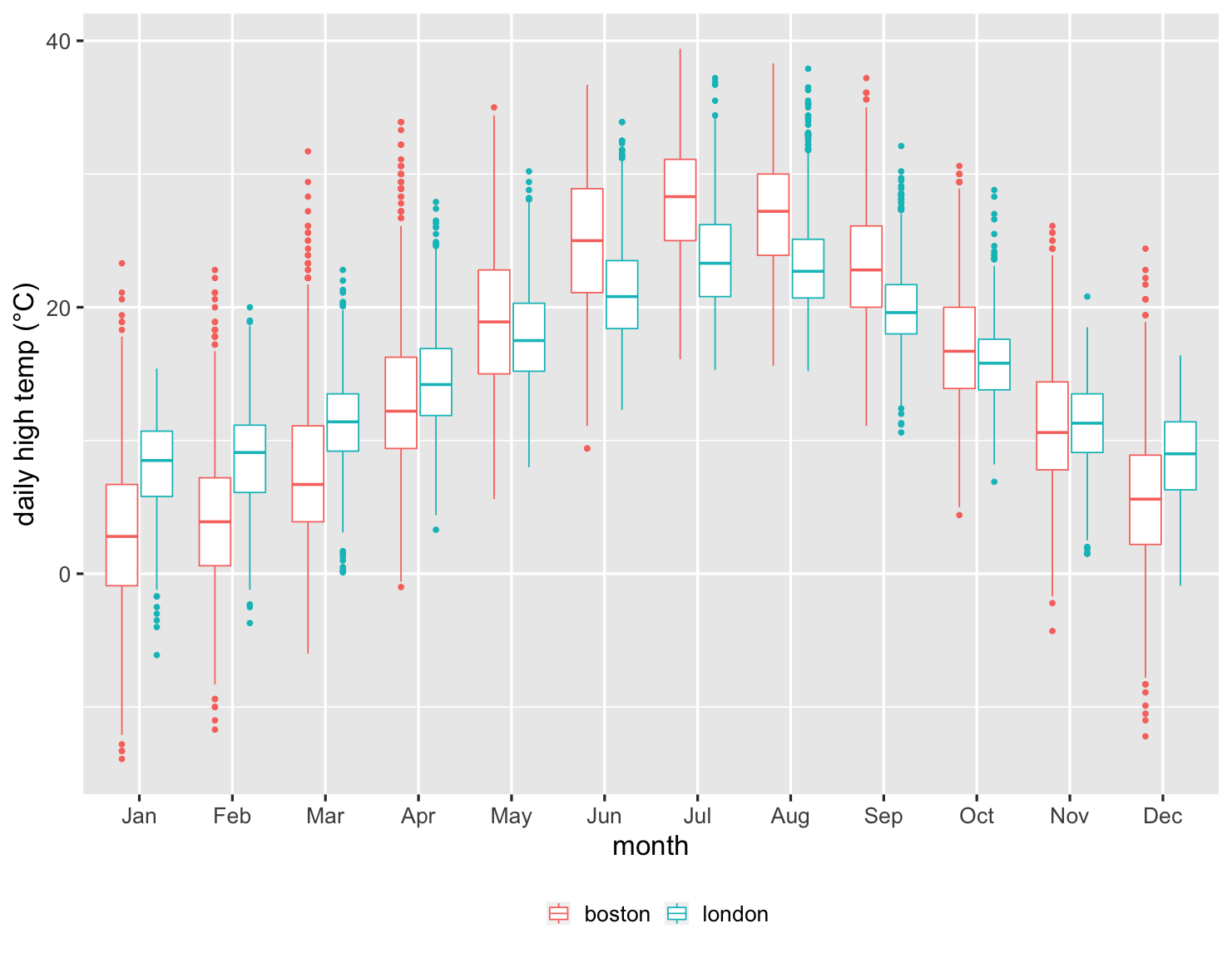
顯示程式碼
ggplot(temps, aes(month, high_temp, color=factor(city))) + ylab(label = "daily high temp (°C)") + theme_grey(base_size=20) + scale_x_discrete(labels=month.abb) + labs(color = NULL) + theme(legend.position = "bottom") + geom_boxplot()
這是一個令人印象深刻的圖表,因為它總結了超過 27,000 個資料點。我可以看到倫敦冬季的中位數溫度較溫暖,但夏季較涼爽。但我也可以看到每個月的變化比較。我可以看到,超過四分之一的時間,波士頓在 1 月份不會超過冰點。波士頓的上四分位數僅略高於倫敦的下四分位數,清楚地顯示出我的新家有多冷。但我也可以看到,有時波士頓在 1 月份會比倫敦在那個冬季月份更溫暖。
然而,箱型圖有一個缺點,在於我們無法看到資料的確切形狀,只能看到常見的匯總點。在比較 Alice 和 Clara 時,這可能是一個問題,因為我們沒有像在直方圖和密度圖中那樣看到 Alice 分布中的雙峰。
有幾種方法可以解決這個問題。一種方法是,我可以輕鬆地將箱型圖與條形圖結合起來。
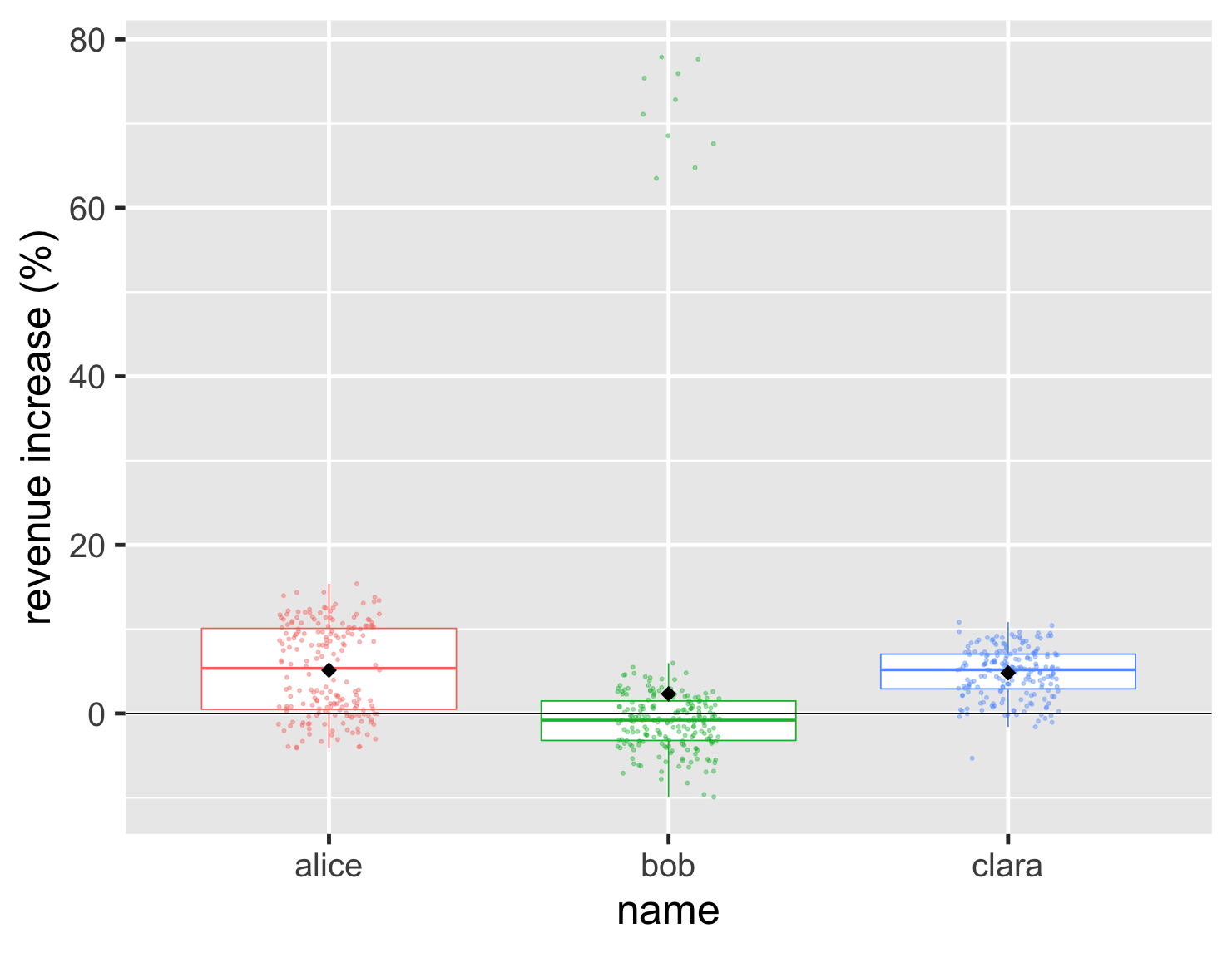
顯示程式碼
ggplot(large_sales, aes(name, value, color=name)) + geom_boxplot(show.legend=FALSE, outlier.shape = NA) + geom_jitter(width=0.15, alpha = 0.4, size=1, show.legend=FALSE) + ylab(label = "revenue increase (%)") + stat_summary(fun = "mean", size = 5, geom = "point", shape=18, color = 'black') + geom_hline(yintercept = 0) + theme_grey(base_size=30)
這使我能夠同時顯示基礎資料和重要的匯總值。在此圖中,我也包含了之前用來顯示平均值位置的黑鑽石。這是一個突顯像 Bob 這樣平均值和中位數差異很大的案例的好方法。
另一種方法是小提琴圖,它會在方塊的側面繪製密度圖。
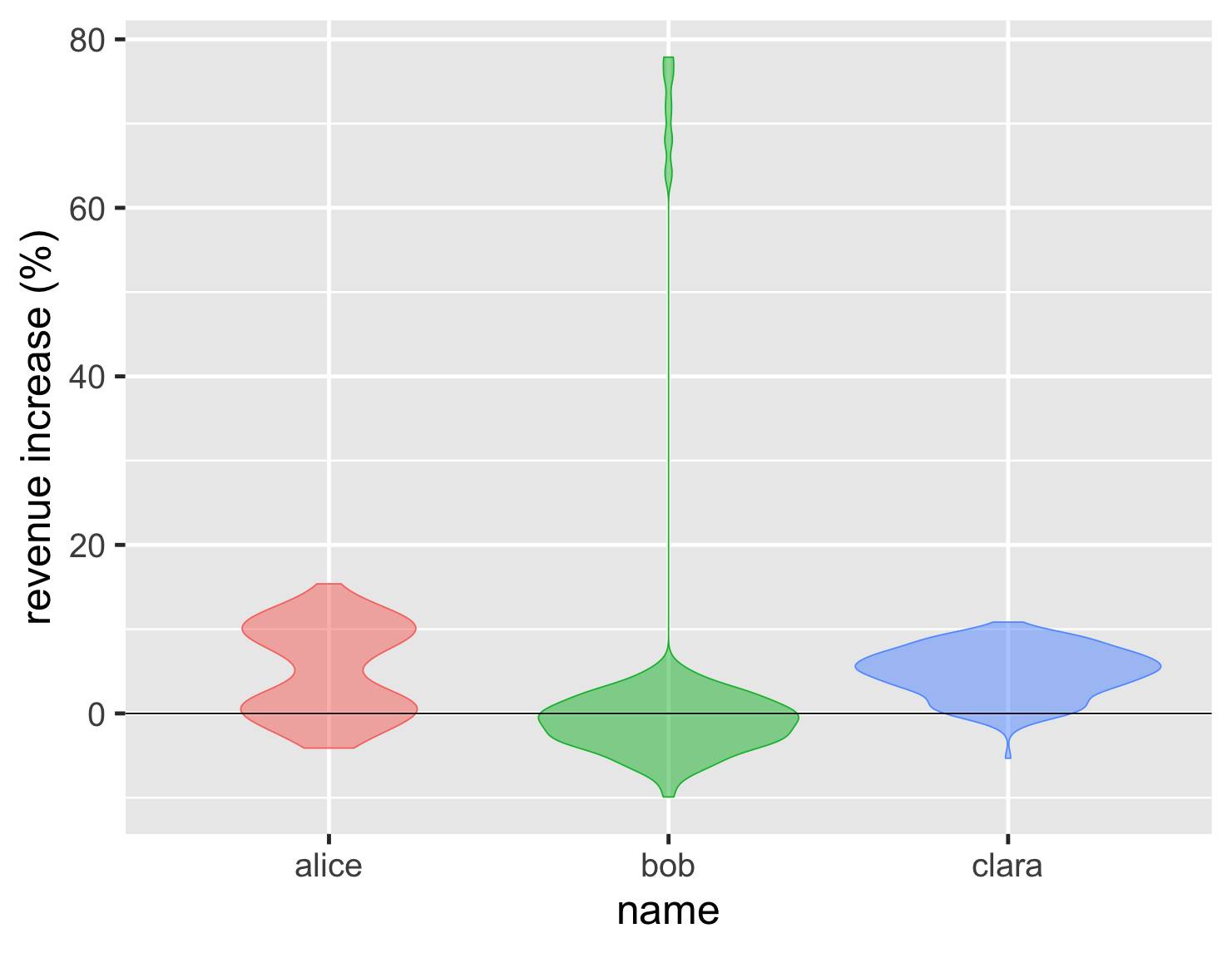
顯示程式碼
ggplot(large_sales, aes(name, value, color=name, fill=name)) + geom_violin(show.legend=FALSE, alpha = 0.5) + ylab(label = "revenue increase (%)") + geom_hline(yintercept = 0) + theme_grey(base_size=30)
這具有清楚顯示分佈形狀的優點,因此 Alice 的表現雙峰非常突出。與密度圖一樣,它們只有在有更多點的情況下才會有效。對於銷售範例,我想我寧願看到方塊中的點,但如果我們有 27,000 個溫度測量值,權衡就會改變。
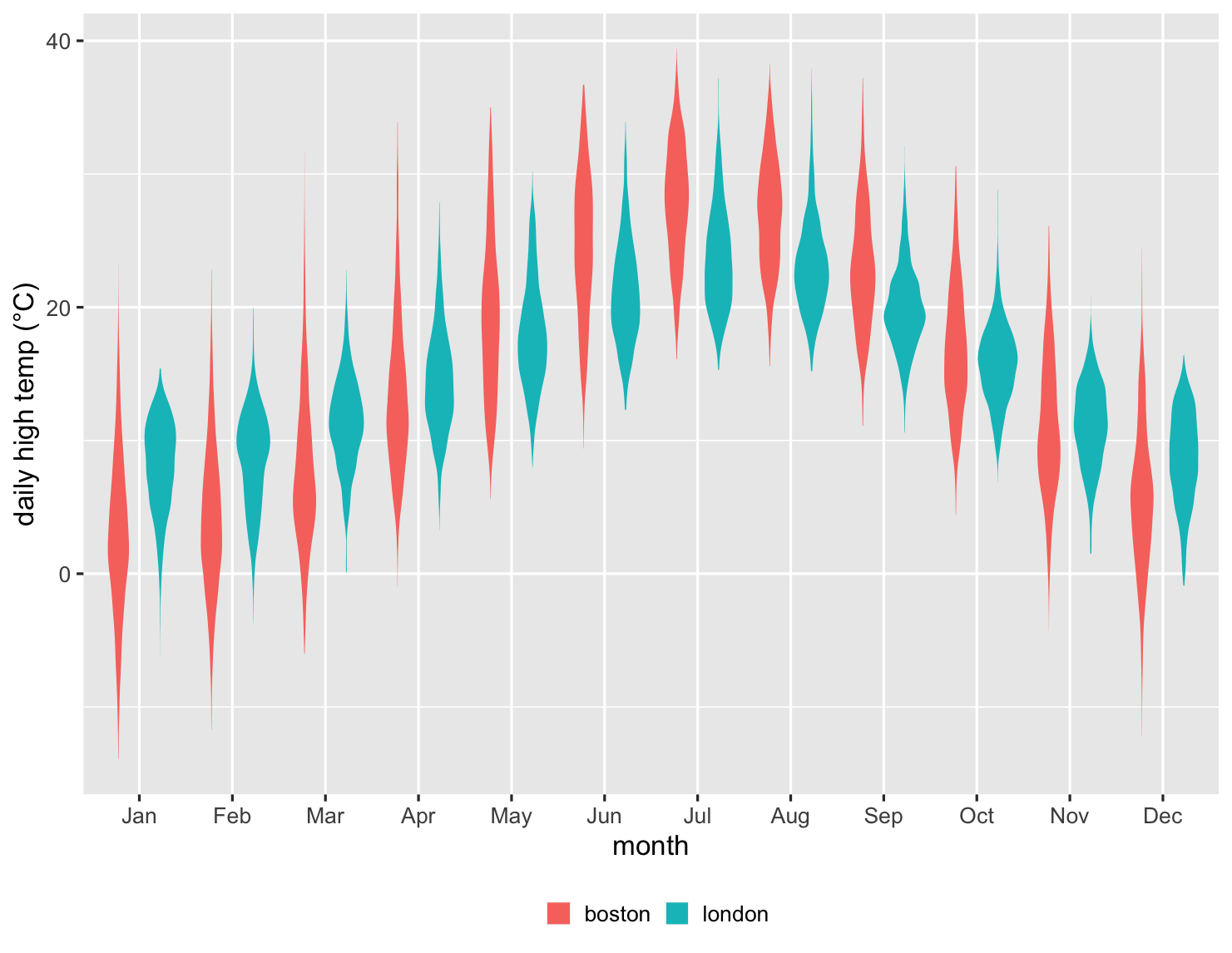
顯示程式碼
ggplot(temps, aes(month, high_temp, fill=factor(city))) + ylab(label = "daily high temp (°C)") + theme_grey(base_size=20) + labs(fill = NULL) + scale_x_discrete(labels=month.abb) + theme(legend.position = "bottom") + geom_violin(color = NA)
在這裡,我們可以看到小提琴非常適合顯示每個月的資料形狀。但總體而言,我發現此資料的箱型圖更有用。通常透過使用資料中的重要標誌(例如中位數和四分位數)來比較會更容易。這是多個圖形發揮作用的另一個案例,至少在探索資料時如此。箱型圖通常最有幫助,但至少值得快速瀏覽一下小提琴圖,看看是否會顯示出一些古怪的形狀。
總結
- 除非您了解基礎分佈,否則不要僅使用平均值來比較群組。
- 如果有人僅向您顯示平均值資料,請詢問:「分佈看起來如何?」
- 如果您要探討群組之間的比較,請使用多個不同的圖表來探討其形狀以及最佳比較方式。
- 如果要求提供「平均值」,請檢查平均數或中位數哪個較佳。
- 在呈現群組之間的差異時,請考慮至少使用我這裡顯示的圖表,不要害怕使用多個圖表,並選擇最能說明重要特徵的圖表。
- 最重要的是:繪製分佈圖!
致謝
Adriano Domeniconi、David Colls、David Johnston、James Gregory、John Kordyback、Julie Woods-Moss、Kevin Yeung、Mackenzie Kordyback、Marco Valtas、Ned Letcher、Pat Sarnacke、Saravanakumar Saminathan、Tiago Griffo 和 Xiao Guo 在內部郵件清單上對本文草稿提出評論。
延伸閱讀
Cédric Scherer 介紹了 雨雲圖 的方法,該方法結合了箱形圖、小提琴圖和帶狀圖的特點,並使用簡潔的符號表示。他的教學課程是根據 Allen 等人 的論文編寫的
我學習 R 的經驗
大約 15 年前,我第一次接觸 R,當時我與一位同事在一個統計問題上做了一些工作。儘管我在學校學了很多數學,但我避開了統計學。雖然我對它提供的見解非常感興趣,但它所需的計算量讓我卻步。我有一個奇怪的特點,就是我擅長數學但不擅長算術。
我喜歡 R,特別是因為它支援其他地方幾乎沒有的圖表(而且我從來不太喜歡使用試算表)。但 R 是個平台,有些地方危險到讓 JavaScript 看起來很安全。然而,近年來,由於 Hadley Whickham(R 的奧斯曼男爵)的工作,使用 R 變得容易多了。他領導了「tidyverse」的開發:一系列讓 R 非常容易使用的函式庫。本文中的所有圖表都使用他的 ggplot2 函式庫。
近年來,我越來越常使用 R 來建立任何使用量化資料的報告,R 既可進行計算,也可繪製圖表。這裡的 tidyverse dplyr 函式庫扮演了重要的角色。它基本上允許我在表格資料上形成運算管線。在某個層面上,它是一個表格列上的收集管線,具有對列進行對應和篩選的函數。然後,它進一步支援表格導向的運算,例如連接和樞紐。
如果撰寫如此出色的軟體還不夠,他還共同撰寫了一本優秀的書籍,教授如何使用 R:R for Data Science。我發現這是一個關於資料分析的絕佳教學課程、tidyverse 的簡介,以及一個頻繁的參考。如果您對處理和視覺化資料感興趣,並喜歡親自使用一個嚴肅的工具來完成這項工作,那麼這本書是一個很好的方式。R 社群在這本書和其他有助於解釋資料科學概念和工具的書籍上做得很好。tidyverse 社群還建立了一個名為R Studio的一流開源編輯和開發環境。我只能說,在使用 R 時,我通常使用它而不是 Emacs。
R 當然並不完美。作為一種程式語言,它出奇地古怪,我不敢偏離簡單的 dplyr/ggplot2 管線的林蔭大道。如果我想在資料豐富的環境中進行嚴肅的程式設計,我會認真考慮轉用 Python。但對於我所做的資料工作類型,R 的 tidyverse 已被證明是一個出色的工具。
製作好的長條圖的訣竅
當我使用長條圖時,我經常會使用一些有用的技巧。通常,您會得到具有相似甚至相同值的資料點。如果我天真地繪製它們,我最終會得到像這樣的長條圖。
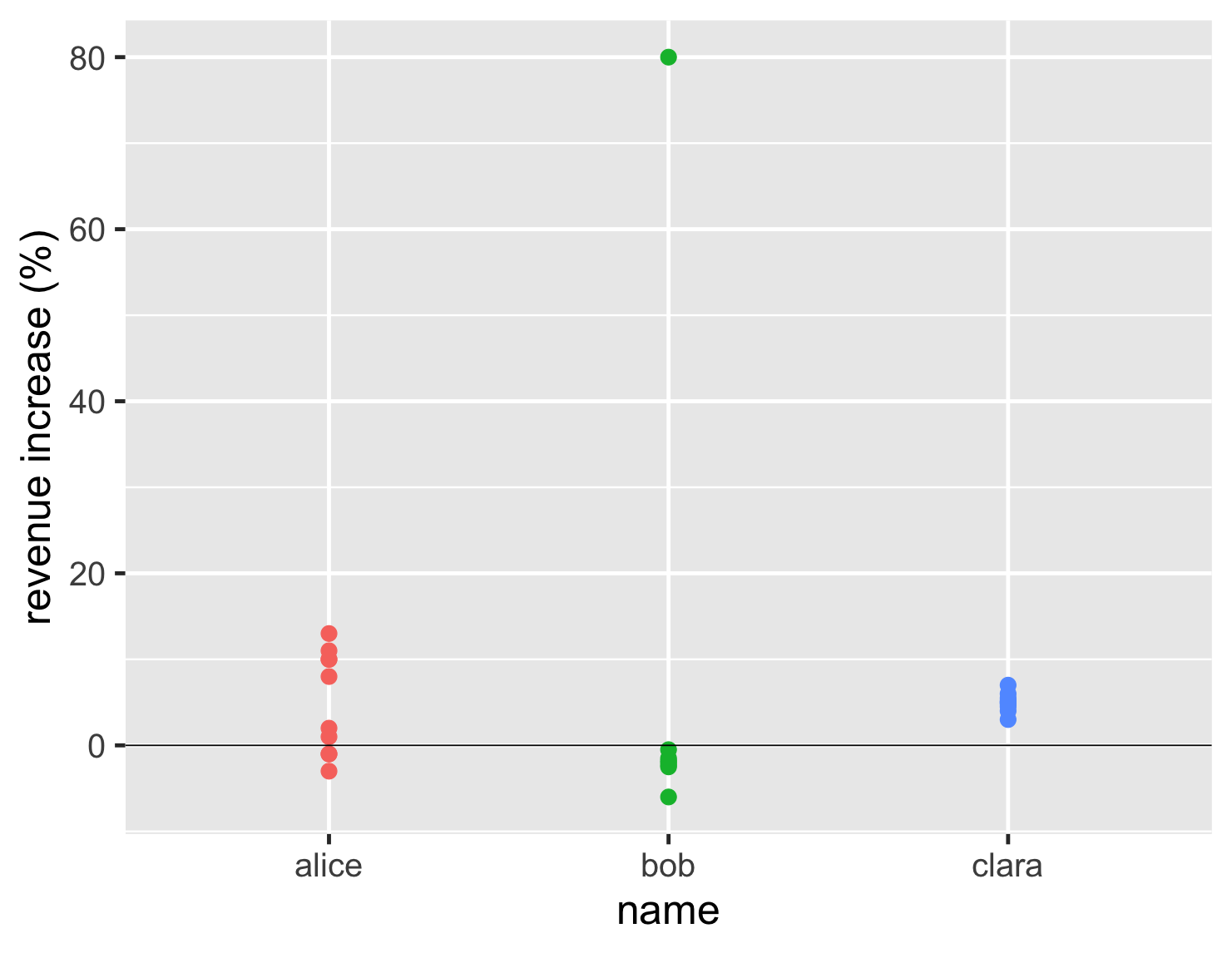
顯示程式碼
ggplot(sales, aes(name, d_revenue, color=name)) + geom_point(size=5, show.legend=FALSE) + ylab(label = "revenue increase (%)") + geom_hline(yintercept = 0) + theme_gray(base_size=30)
這個圖表仍然比第一個長條圖好,因為它清楚地表明了鮑伯的異常值與他通常的表現有何不同。但是由於克拉拉有這麼多相似的值,它們都堆疊在一起,所以您無法看出有多少個。
我使用的第一個技巧是增加一些抖動。這會為長條圖的點增加一些隨機的水平移動,讓它們可以散開並加以區分。我的第二個技巧是讓點部分透明,這樣我們就可以看到它們何時疊加在一起。有了這兩個技巧,我們可以適當地了解資料點的數量和位置。
探索直方圖的組距
直方圖透過將資料放入組中來運作。因此,如果我的組距為 1%,則所有收入增加在 0% 到 1% 之間的帳戶都會放入同一個組中,而圖表會繪製出每個組中有多少個。因此,組的寬度(或數量)對我們所看到的內容有很大的影響。如果我為這個資料集建立更大的組,我將得到這個圖表。
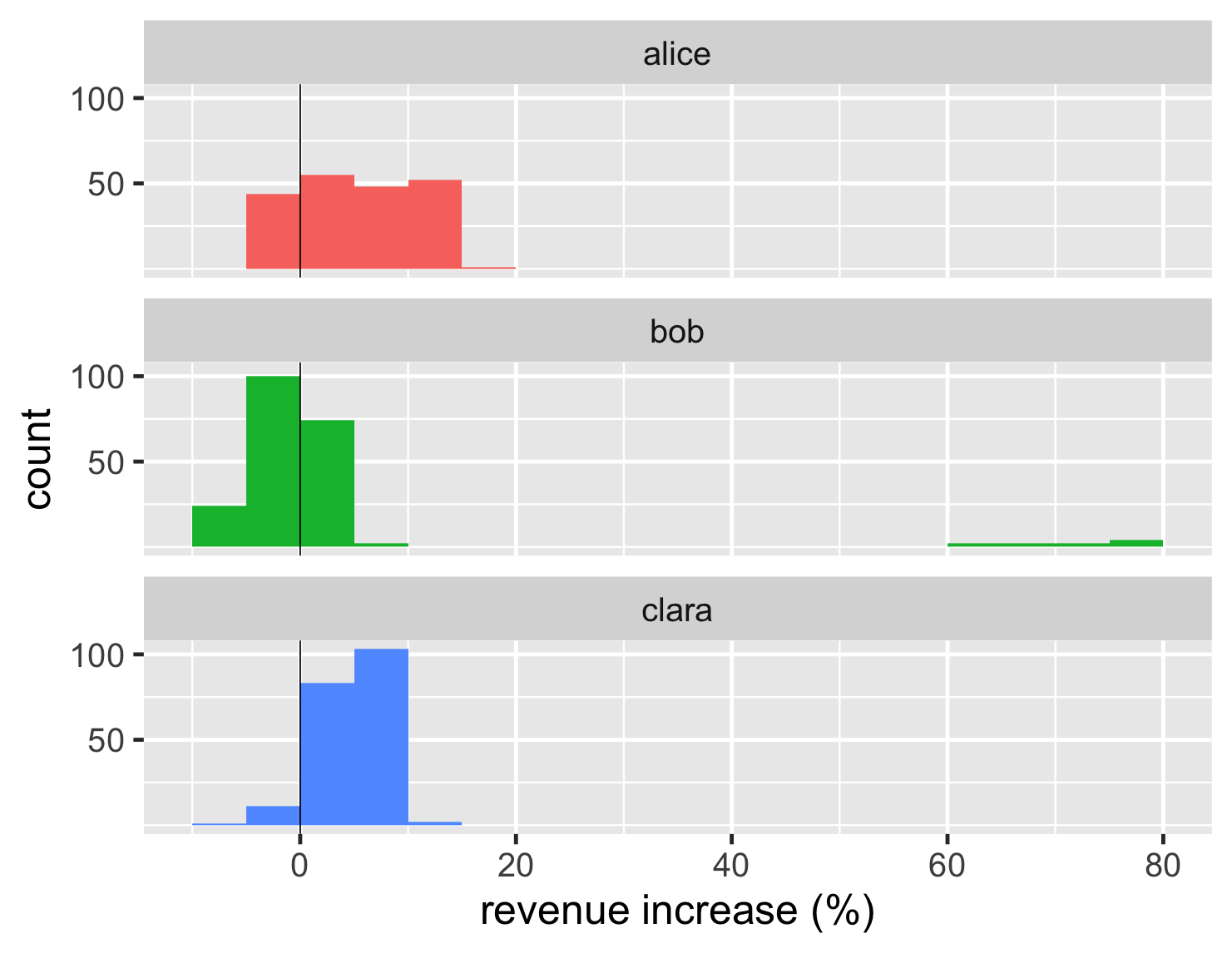
顯示程式碼
ggplot(large_sales, aes(value, fill=name)) + geom_histogram(binwidth = 5, boundary=0,show.legend=FALSE) + scale_y_continuous(breaks = c(50,100)) + xlab(label = "revenue increase (%)") + geom_vline(xintercept = 0) + theme_grey(base_size=30) + facet_wrap(~ name,ncol=1)
此處的區間太寬,以至於我們無法看到愛麗絲分佈的兩個峰值。
相反的問題是,如果區間太窄,則繪圖會變得雜亂。因此,當我繪製直方圖時,我會嘗試使用區間寬度,嘗試不同的值,看看哪些值有助於揭示資料的有趣特徵。
腳註
1: 我善用了 SQLite 的 延伸函數 貢獻檔案,其中包含許多有用的函數,包括中位數。
重大修訂
2020 年 9 月 24 日:發布
2020 年 9 月 18 日:開始起草