
標籤:資料分析
資料網格原則與邏輯架構
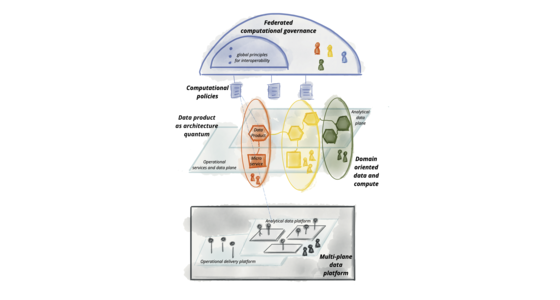
我們渴望利用資料提升和改善商業和生活的各個面向,這需要我們在管理大規模資料的方式上進行典範轉移。儘管過去十年的技術進步已解決了資料量和資料處理運算的規模問題,但它們未能解決其他面向的規模問題:資料環境的變化、資料來源的擴散、資料使用案例和使用者的多元性,以及對變化的反應速度。資料網格透過四項原則來解決這些面向:以網域為導向的分散式資料擁有權和架構、資料即產品、自助式資料基礎架構即平台,以及聯邦運算治理。每項原則都推動了技術架構和組織結構的新邏輯觀點。
如何從單一資料湖轉移到分散式資料網格
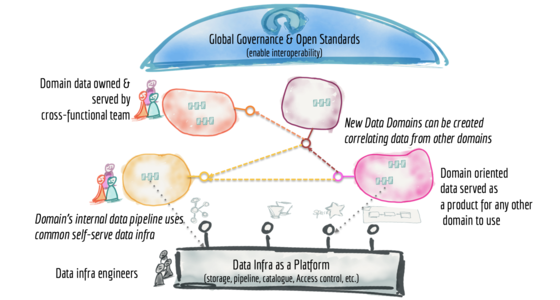
許多企業都在投資其下一代資料湖,希望大規模地民主化資料,以提供商業見解並最終做出自動化智能決策。基於資料湖架構的資料平台具有常見的失敗模式,導致無法大規模實現承諾。為了解決這些失敗模式,我們需要從湖的集中式典範或其前身資料倉庫轉移。我們需要轉移到從現代分散式架構中汲取的典範:將網域視為首要考量、應用平台思維來建立自助式資料基礎架構,並將資料視為產品。
不要比較平均值
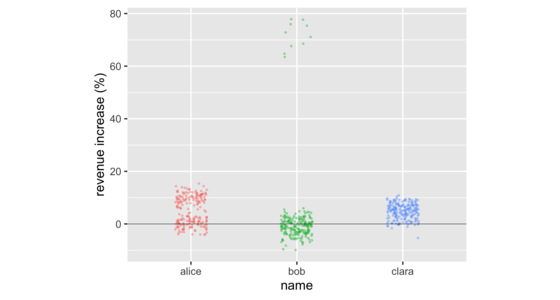
在商業會議中,通常會透過比較數字群組的平均值來比較群組。但這麼做通常會隱藏這些群組中數字分佈的重要資訊。有許多資料視覺化可以揭露這些資訊。這些視覺化包括條形圖、直方圖、密度圖、箱形圖和提琴圖。這些視覺化很容易使用免費軟體製作,適用於小至十幾個或大至數千個的群組。
隱私強化技術:技術人員簡介
隱私強化技術 (PET) 是為軟體和系統處理、儲存和/或收集其資料的人員提供更多隱私或機密的技術。有價值且可立即使用的三項 PET 為:差分隱私、分散式和聯邦分析與學習,以及加密運算。它們提供嚴格的隱私保證,因此越來越受歡迎,可以在最大程度減少侵犯私人資料的情況下提供資料。
機器學習的持續交付
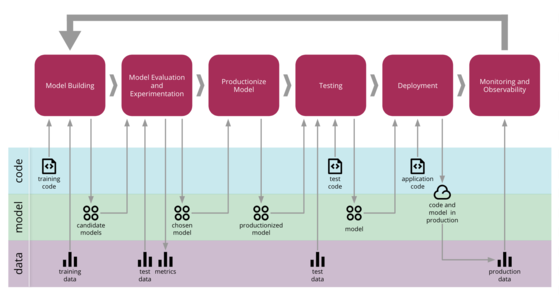
機器學習應用程式在我們的產業中越來越受歡迎,然而,與更傳統的軟體(例如網路服務或行動應用程式)相比,開發、部署和持續改進它們的流程更加複雜。它們會在三個軸線上發生變化:程式碼本身、模型和資料。它們的行為通常很複雜且難以預測,而且更難測試、解釋和改進。機器學習的持續交付 (CD4ML) 是將持續交付原則和實務引入機器學習應用程式的準則。
雙時態歷史
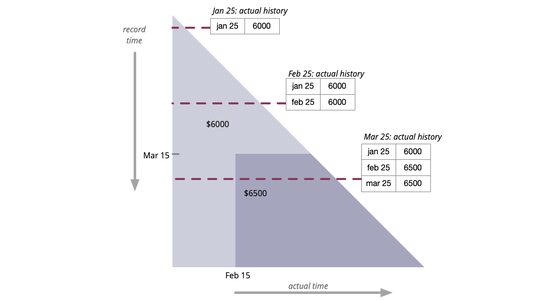
通常需要存取某些屬性的歷史值。但有時這個歷史記錄本身需要根據追溯更新進行修改。雙時態歷史將時間視為兩個面向:實際歷史記錄了在資訊傳輸完美的狀況下應該是什麼樣的歷史,而記錄歷史則記錄了我們對歷史的了解如何改變。
資料網格加速工作坊

加速意味著移動得更快、獲得速度。有效地處理資料是任何想要在現代世界中蓬勃發展的組織的關鍵,而資料網格正在向組織展示如何大規模地從其資料中實現價值。資料網格加速工作坊通過了解團隊和組織的當前狀態並探討下一步將如何進行,來幫助他們加速資料網格轉型。
別將資料科學筆記本應用於生產
我們遇過許多有興趣將資料科學家開發的運算筆記本直接放入生產應用程式程式碼庫的客戶。資料科學概念確實需要從筆記本轉移到生產,但嘗試將筆記本部署為程式碼成品會破壞許多良好的軟體實務。可以預見,這會導致許多已觀察到的痛點。這種行為是更深層問題的徵兆:資料科學家與軟體開發人員之間缺乏協作。
資料的演進全景
我們在 2012 年 QCon London 的主題演講中探討資料在我們生活中扮演的角色(而且它所做的不只是變得更大)。我們從探討資料世界如何改變開始:它正在成長、變得更分散且更緊密。接著我們轉移到產業的回應:NoSQL 的興起、轉向服務整合、事件來源的出現、雲端和具有更重要視覺化角色的新分析的影響。我們快速檢視資料現在如何被使用,特別強調 Rebecca 在開發中國家的資料。最後,我們考量所有這些對我們作為軟體專業人員的個人責任有何意義。
思考大數據
「大數據」已迅速躍升為我們產業中最受炒作的術語之一,但炒作不應讓人們忽略這是一個關於資料在世界中角色的真正重要轉變。資料來源的數量、速度和價值正在快速增加。資料管理必須在五個廣泛領域中改變:萃取來自更廣泛來源的資料、資料管理的後勤發生變化,採用新的資料庫和整合方法、在執行分析專案中使用敏捷原則、強調資料詮釋技術以區分訊號和雜訊,以及精心設計的視覺化的重要性,讓訊號更易於理解。總結來說,這表示我們不需要大型分析專案,而是希望新的資料思維滲透到我們的日常工作中。
BigQuery 的概念驗證
Google 的新 BigQuery 服務是否能讓客戶在不需要昂貴軟體或新基礎設施的情況下,擁有巨量資料分析能力?Thoughtworks 和 AutoTrader 使用龐大的資料集進行了一週的概念驗證測試。測試顯示,在 7.5 億列資料集上,查詢效能始終如一,範圍在 7-10 秒之間。我們使用 REST API 搭配 Java、JavaScript 和 Google Charts,建立一個具有查詢結果互動視覺效果的網頁前端。整個練習在五天內由三人完成。結論:BigQuery 表現良好,且能使預算較少的大數據組織受益,特別是沒有資料倉儲或資料倉儲使用受限的組織。
NoSQL 簡介
在 goto Aarhus,我們有一個關於 NoSQL 實際經驗的專題。我被要求做一場開場演講,說明 NoSQL 資料儲存的基本原則。我談到 NoSQL 的起源、NoSQL 資料模型的形式、許多 NoSQL 資料庫考量一致性的方式,以及多語持久性的重要性。
與 Dave Farley 的工程室對話
我以前的老同事 Dave Farley 一直經營一個越來越受歡迎的 YouTube 頻道,主題是軟體開發。這是很好的材料,非常符合我的觀點,畢竟他的經驗對我的想法有很大的影響。我們討論了關於軟體工程當前角色的各種主題,特別關注我目前支援的三個大型寫作專案:資料網格、分散式系統模式和舊系統取代模式。
資料在軟體開發中不斷演變的角色
由於無法前往澳洲參加 2020 年的 XConf,我改用 Zoom 與 Thoughtworks 澳洲技術主管 Scott Shaw 對話。我們談論了資料在現代應用程式開發中扮演的角色變化:應用程式開發人員和資料庫之間的鴻溝、由於大(且雜亂)資料出現而產生的變化、改善資料素養的必要性,以及大量收集推測資料對社會的影響。
資料不同
我們的歐洲「資料女巫」Em Grasmeder 和我原本計畫在歐洲的 XConf 系列活動中發表主題演講。由於 2020 年的關係,我們改用 Zoom,並討論資料科學家的角色:角色的實際內容、他們需要取得的工具,以及他們與其他形式軟體開發的關係。
使用 R 的 ggplot2 繪製柔和的義大利麵線條圖
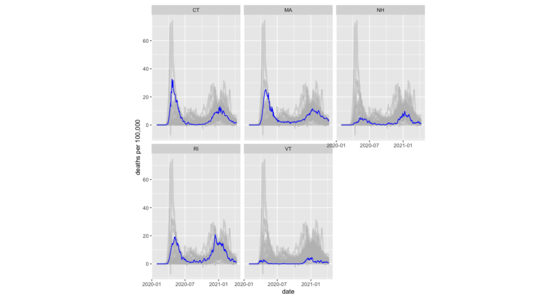
如何使用 R 繪製柔和的義大利麵線條圖,包括分面。
社群儀表板

隨著對資料分析和視覺化的興趣日益濃厚,我們看到更多人致力於製作有趣的視覺化,讓人們可以從組織中流動的資料中獲得見解。這些儀表板大多數都是針對個人使用,但越來越多人傾向於將它們用於更社群的目的。
運算筆記本
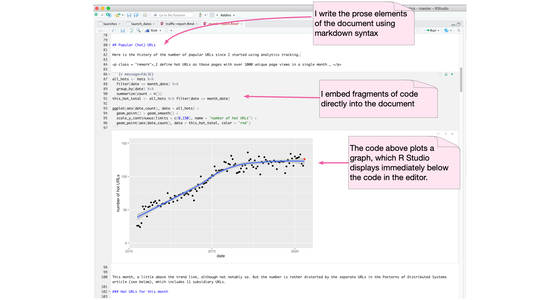
運算筆記本是一種用於撰寫散文文件,並允許作者嵌入程式碼的環境,這些程式碼可以輕鬆執行,並且結果也會納入文件中。這是一個特別適合資料科學工作的平台。此類環境包括 Jupyter Notebook、R Markdown、Mathematica 和 Emacs 的 org 模式。
資料湖
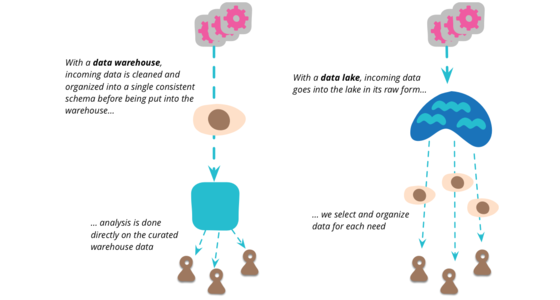
資料湖是本十年出現的一個術語,用於描述大資料世界中資料分析管線的重要組成部分。其理念是在組織中任何人都可能需要分析的所有原始資料中建立一個單一儲存庫。一般來說,人們使用 Hadoop 來處理資料湖中的資料,但這個概念比 Hadoop 更廣泛。
Datensparsamkeit
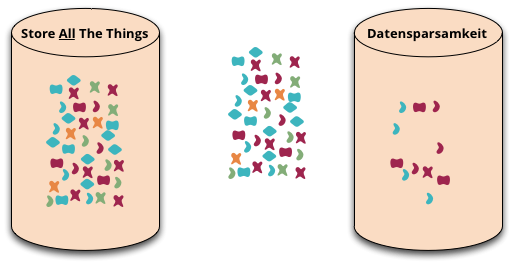
Datensparsamkeit 是一個德語單字,很難適當地翻譯成英文。這是一種我們擷取和儲存資料的態度,表示我們只應處理我們真正需要的資料。
機器驗證
我記得在青少年時期,有人告訴我人工智慧 (AI) 在未來幾年內會做哪些美妙的事情。現在過了數十年,其中一些事情似乎正在發生。最近的勝利是電腦透過彼此對弈來學習下圍棋,迅速變得比任何人都熟練,而且策略是人類專家難以理解的。自然會好奇接下來幾年會發生什麼事,電腦是否很快就會比人類更聰明?(考量到最近的選舉結果,這可能不是太難達成的目標。)
但當我聽到這些事情時,我回想起畢卡索在數十年前對電腦的評論:「電腦沒用。它們只能給你答案」。機器學習等技術能產生的推理在結果上確實令人印象深刻,而且對我們這些軟體使用者和開發人員來說會很有用。但是答案雖然有用,卻不總是全貌。我在求學初期就學到了這一點 - 只提供數學問題的答案只能得到幾分,要得到滿分,我必須展示如何得到答案。得到答案的推理比結果本身更有價值。這是自學圍棋 AI 的限制之一。雖然它們可以獲勝,但無法解釋自己的策略。
機率文盲
當我寫下這篇文章,美國總統大選接近尾聲,出現了一場關於 Nate Silver 所做預測的辯論。許多共和黨人聲稱他是民主黨的傀儡,他預測歐巴馬有 85% 的勝算根本是胡說八道。我有一部分希望認識更多不懂數字的共和黨人,這樣我就可以跟他們打賭。或許更好的願望是民意調查結果相反,因為我比較多民主黨傾向的朋友。實際上,無論哪一種方式,我都賺不了太多,因為我認識的大多數人都懂數字。遺憾的是,一般來說並非如此 - 這個插曲說明了大多數人對機率的文盲程度,這對整個社會,特別是軟體開發,都有一些重要的影響。