
聚合導向資料庫
2012 年 1 月 19 日

在我們處理 NoSQL 精華 時,首先想到的主題之一是 NoSQL 資料庫使用與關係模型不同的資料模型。我查閱過的大部分資料來源都至少提到四組資料模型:鍵值、文件、列族和圖形。檢視此清單,前三者之間有很大的相似性,它們都有一個基本的儲存單元,是一個緊密相關資料的豐富結構:對於鍵值儲存,它是值;對於文件儲存,它是文件;對於列族儲存,它是列族。在 DDD 術語中,這組資料是一個 DDD_Aggregate。
NoSQL 資料庫的興起主要是由於有效地在大型叢集上儲存資料的需求,例如 Google 和 Amazon 使用的設定。關係資料庫並非針對叢集而設計,這就是人們四處尋找替代方案的原因。將聚合儲存為基本單元對於在叢集上執行非常有意義。聚合會形成分片等分發策略的自然單元,因為您有一大塊資料,您預期它們會一起存取。
聚合對應用程式程式設計師來說也很有意義。如果您擷取一個螢幕的資訊並將其儲存在關係資料庫中,您必須在儲存之前將該資訊分解成列。
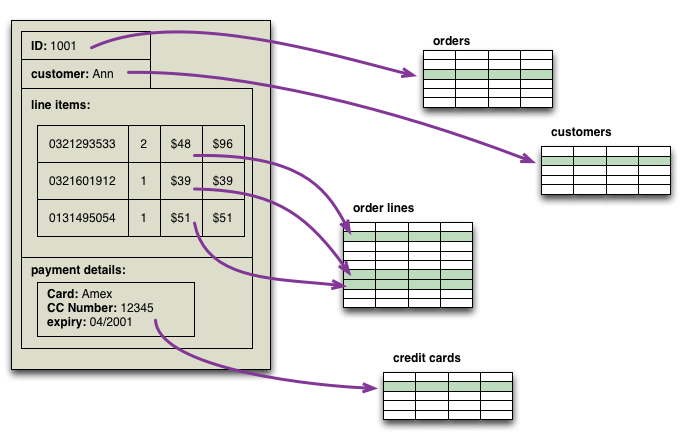
聚合會形成一個更簡單的對應,這就是許多 NoSQL 資料庫的早期採用者回報說它是一個更簡單的程式設計模型的原因。
程式設計模型和分發模型之間的這種協同作用非常有價值。它允許資料庫利用其對應用程式程式設計師如何將資料分群的知識,以協助提升叢集的效能。
有一個顯著的缺點 - 當資料存取與聚合對齊時,整個方法運作得很好,但如果你想用不同的方式檢視資料呢?訂單輸入自然將訂單儲存為聚合,但分析產品銷售會切斷聚合結構。在資料庫中不使用聚合結構的優點是,它允許你為不同的受眾以不同的方式切分和分類你的資料。
這就是為什麼面向聚合的儲存會如此重視 MapReduce - 這是非常適合在叢集上執行的程式設計模式。MapReduce 工作可以將資料重新組織成不同的群組,供不同的讀取器使用 - 許多人稱之為具現化檢視。但這樣做比使用關聯式模型需要更多的工作。
這是 PolyglotPersistence 論點的一部分 - 當你處理明確的聚合時使用面向聚合的資料庫(特別是如果你在叢集上執行),當你想要以不同的方式處理資料時使用關聯式資料庫(或圖形資料庫)。