
急讀派生
2009 年 2 月 10 日

我在 QCon San Francisco 參加的其中一場有趣的演講,是由 Greg Young 所發表的,關於他在最近一個系統中使用的一種特殊架構。Greg 是 領域驅動設計 的忠實愛好者,在這個案例中,它必須用於一個必須處理高交易率並提供資料給許多使用者的系統。我發現他的設計有很多有趣的地方,特別是他使用 事件溯源 的方式,但這篇文章中我只想探討一個面向,也就是我所謂的急讀派生。
當我們使用領域模型時,我們使用它,是因為它包含了複雜的領域邏輯。將這個領域邏輯分類成下列幾種會很有幫助:
- 驗證:檢查輸入是否有意義,以及物件是否適合作為進一步動作。
- 後果:啟動一些動作,將會改變世界的狀態。
- 派生:根據我們已有的資訊,找出一些資訊。
這些類型的領域邏輯,對更新和讀取的適用方式不同。讓我們想像我們有一個家譜系統。我們收到一筆更新,是一份出生證明。
name: Bilbo Baggins
father: Bungo Baggins
mother: Belladonna Took
當我們提交這個資料時,我們的領域模型會進行一些驗證(父親與母親不同)。它可能會產生一些後果(班戈有一個未償還的遺贈,比爾博有權利獲得)。它也可能會進行一些派生,但通常只用於支援驗證或後果(我們需要比爾博祖先的清單,來驗證我們的家譜中沒有循環)。
當我們讀取資料時,通常只有派生邏輯會派上用場。假設我們有一個要求,要顯示比爾博的父系祖父。這需要一些領域邏輯,也就是知道父系祖父是父親的父親。在大多數系統中,我們在收到讀取要求時,會執行這個讀取派生邏輯。基本上,我們收到讀取要求,呼叫資料庫取出原始資料,執行任何需要的派生邏輯,然後傳回結果(雖然快取可能會派上用場,以減少這個動作)。
急讀派生執行的方式完全不同。這裡的讀取完全不會觸及主資料庫。相反地,我們有一個或多個 報表資料庫,其結構與我們的讀取要求相同。任何讀取要求都會直接傳送至報表資料庫,而報表資料庫會直接讀取資料並將其傳送出來,過程中不會涉及任何領域邏輯。
讓我再用出生證明範例和這個圖表來說明一次。
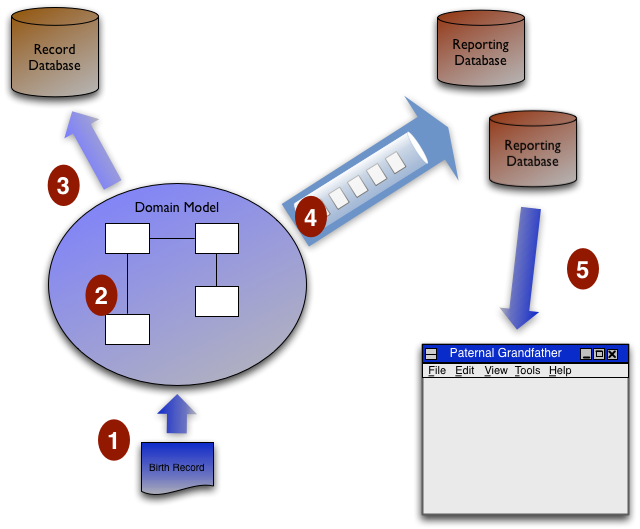
- 我們從使用者介面收到一份出生證明。
- 網域模型執行所有驗證和後果邏輯。
- 網域模型更新核心資訊至記錄資料庫。
- 網域模型執行所有讀取(包括每個 UI 顯示)所需的衍生邏輯,並將更新訊息置於訊息佇列中以填入報告資料庫。每個報告資料庫從這些訊息中選擇其需要資料來更新其資料。
- 讀取請求來自於父系祖父 UI,並透過從報告資料庫中的父系祖父表格直接讀取來滿足。
在 Greg 的案例中,所有這些都是透過非同步訊息完成的,所有輸入都擷取為事件(事件來源),網域模型處理輸入佇列中的訊息,並將輸出事件張貼至輸出佇列以載入報告資料庫。非同步執行所有這些有助於整體效能和可擴充性。這表示有一個不一致的視窗,您可以在其中執行更新,立即執行讀取,但看不到更新結果,因為您按下的速度比訊息處理速度快。這個非同步架構最終會一致,但不是強烈一致。但這是事物的本質:在分散式系統中,您可以獲得一致性或可用性,但不能同時獲得兩者。
現在,您可以在非分散式、強烈一致的方式中執行急切讀取衍生。我無法隨口說出我曾看過它的案例。我想急切讀取衍生大多在您處理高需求分散式案例時變得有吸引力。
執行急切評估並非那麼新穎。這項技術比我老(甚至可能比 Ron Jeffries 老),而且大多數高流量網站都會持續使用衍生資料填入資料庫。但這不是我認為應該考慮的技術,而且我喜歡 Greg 在其設計中使用它的積極方式。