
資料湖
2015 年 2 月 5 日

資料湖是一個在本十年出現的術語,用來描述大數據世界中資料分析管線的重要組成部分。其概念是為組織中任何可能需要分析資料的人員建立一個所有原始資料的單一儲存庫。一般來說,人們會使用 Hadoop 來處理資料湖中的資料,但這個概念比 Hadoop 更廣泛。
當我聽到一個單一據點可以彙整組織想要分析的所有資料時,我馬上會想到資料倉儲(以及資料市集[1])的概念。但資料湖和資料倉儲之間有一個重要的區別。資料湖儲存原始資料,無論資料來源提供什麼格式的資料。資料的架構沒有任何假設,每個資料來源都可以使用它喜歡的任何架構。由該資料的使用者負責讓該資料對他們自己的目的有意義。
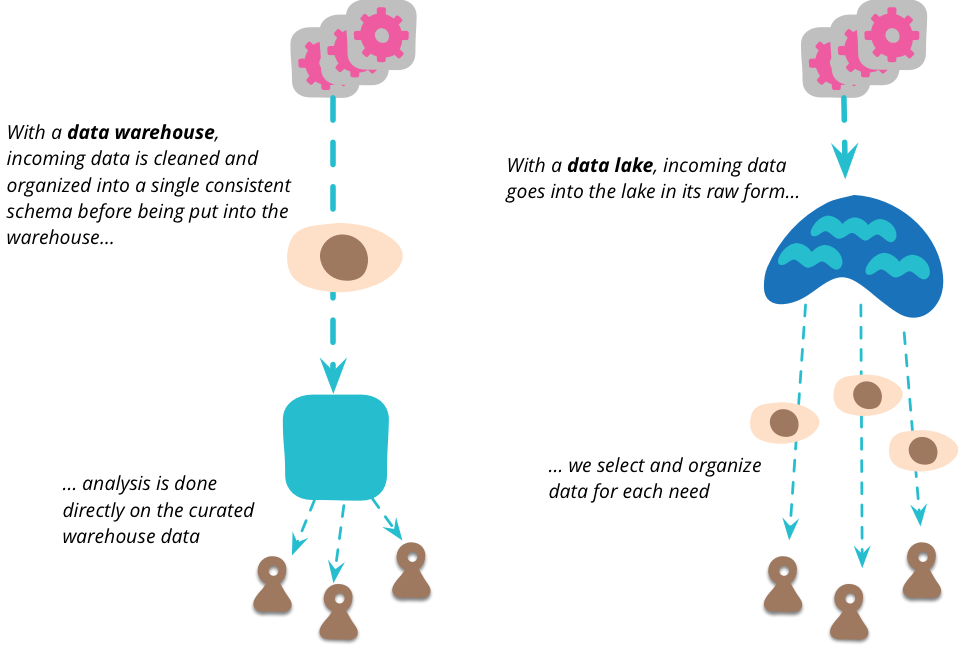
這是一個重要的步驟,許多資料倉儲計畫都因為架構問題而無法進展得很順利。資料倉儲傾向於採用單一架構的概念來滿足所有分析需求,但我認為單一的統一資料模型對於除了最小的組織之外的任何組織來說都是不切實際的。即使要對一個稍微複雜的網域建模,你也需要多個限界脈絡,每個限界脈絡都有自己的資料模型。就分析術語而言,你需要每個分析使用者使用一個對他們正在進行的分析有意義的模型。透過轉移到僅儲存原始資料,這堅定地將責任交給資料分析師。
資料倉儲計畫的另一個問題來源是確保資料品質。嘗試取得資料的權威單一來源需要大量分析資料是如何被不同的系統取得和使用的。系統 A 可能適合某些資料,而系統 B 則適合其他資料。你會遇到規則,例如系統 A 較適合較近期的訂單,但系統 B 較適合一個月或更早之前的訂單,除非涉及退貨。最重要的是,資料品質通常是一個主觀問題,不同的分析對資料品質問題有不同的容忍度,甚至對什麼是好品質有不同的概念。
這導致了對資料湖的常見批評,即它只是一個品質參差不齊的資料傾倒場,更恰當的名稱應該是資料沼澤。這種批評既正確又無關緊要。新分析的熱門職稱是「資料科學家」。儘管這是一個被濫用的職稱,但許多人確實擁有紮實的科學背景。而任何認真的科學家都知道資料品質問題。想想你可能認為很簡單的分析溫度讀數隨時間變化的問題。你必須考慮到有些氣象站會以可能微妙影響讀數的方式搬遷、設備問題導致的異常值,以及感測器無法運作時遺失的期間。許多精密的統計技術都是為了解決資料品質問題而建立的。科學家總是對資料品質抱持懷疑態度,並且習慣處理有問題的資料。因此,對他們來說,資料湖很重要,因為他們可以處理原始資料,並可以慎重地應用技術來理解它,而不是使用一些不透明的資料清理機制,這種機制可能弊大於利。
資料倉儲通常不僅會清理資料,還會將資料彙總成更容易分析的形式。但科學家也傾向於反對這一點,因為彙總意味著捨棄資料。資料湖應該包含所有資料,因為你不知道人們會在今天或幾年後發現什麼有價值。
我的其中一位同事用一個最近的例子說明了這種想法:「我們試著比較我們的自動預測模型與公司合約經理手動預測的結果。為此,我們決定使用一年前的資料訓練我們的模型,並將我們的預測與當時經理所做的預測進行比較。由於我們現在知道正確的結果,這應該是一個公平的準確性測試。當我們開始這麼做時,經理的預測似乎很糟糕,甚至我們在短短兩週內建立的簡單模型都比它們好。我們懷疑這種表現好得令人難以置信。經過大量的測試和挖掘,我們發現與那些經理預測相關的時間戳記不正確。它們會被一些月底處理報告修改。簡而言之,資料倉儲中的這些值毫無用處;我們擔心我們無法執行此比較。經過進一步挖掘,我們發現這些報告已被儲存,因此我們可以提取當時做出的實際預測。(我們再次擊敗它們,但花了好幾個月才達成目標)。
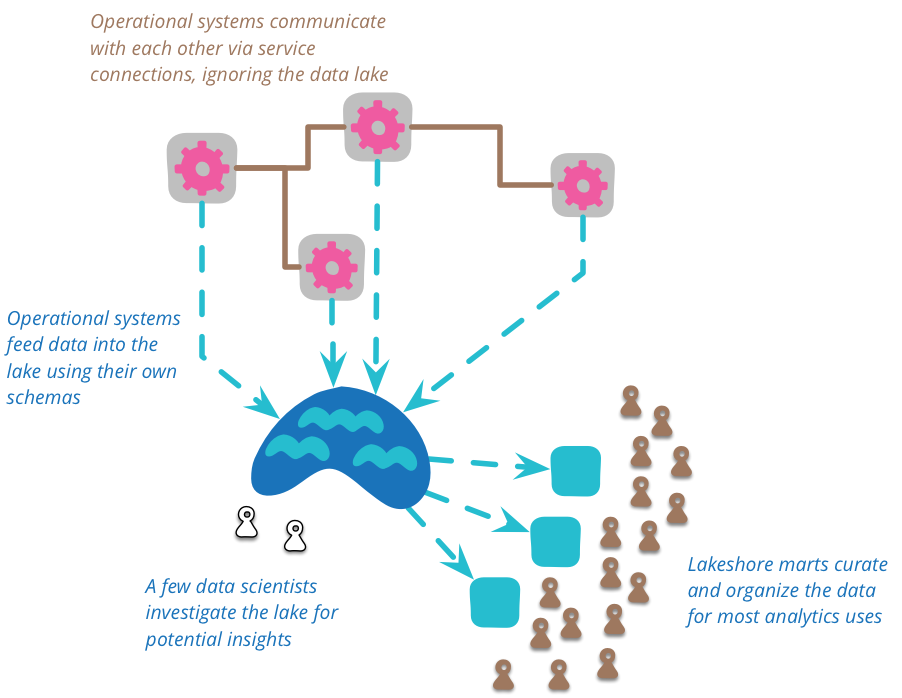
此原始資料的複雜性表示有空間可以將資料策展成更易於管理的結構(以及減少大量的資料)。不應直接存取資料湖泊。由於資料是原始的,因此您需要很多技能才能理解它。在資料湖泊中工作的人員相對較少,因為他們會發現資料湖泊中普遍有用的資料檢視,他們可以建立多個資料市集,每個資料市集都有一個特定模型,用於單一有界脈絡。然後,大量的下游使用者可以將這些湖岸市集視為該脈絡的權威來源。
到目前為止,我已將資料湖泊描述為整合企業中資料的單一據點,但我應該提到這並非其最初的用意。這個詞彙是由詹姆斯·迪克森於 2010 年創造的,當時他打算將資料湖泊用於單一資料來源,多個資料來源將形成「水園」。儘管有其原始表述,但現在普遍的用法是將資料湖泊視為結合許多來源。[2]
您應將資料湖泊用於分析目的,而非用於作業系統之間的協作。當作業系統協作時,它們應透過專為此目的而設計的服務來執行此操作,例如 RESTful HTTP 呼叫或非同步訊息傳遞。湖泊太複雜,無法進行作業通訊的拖網。湖泊的分析可能會導致新的作業通訊路線,但這些路線應直接建置,而非透過湖泊。
重要的是,放入湖泊中的所有資料都應有明確的來源和時間。每個資料項目都應有明確的追蹤,以了解其來自哪個系統以及資料產生的時間。因此,資料湖泊包含歷史記錄。這可能是來自將網域事件輸入湖泊,與事件來源系統自然契合。但它也可能來自系統將目前的狀態定期傾倒到湖泊中 - 當來源系統沒有任何時間功能,但您想要對其資料進行時間分析時,這種方法很有價值。這會導致放入湖泊中的資料是不可變的,一旦陳述觀察結果,就無法移除(儘管稍後可能會被駁回),您也應預期矛盾的觀察結果。
資料湖泊沒有架構,由來源系統決定要使用哪種架構,而使用者則必須找出如何處理產生的混亂。此外,來源系統可以自由變更其流入資料架構,而使用者也必須應付。顯然我們希望此類變更的破壞性盡可能降到最低,但科學家寧可選擇雜亂的資料,也不要遺失資料。
資料湖泊將會非常龐大,而且大部分儲存都以大型非結構架構的概念為導向,這就是 Hadoop 和 HDFS 通常是人們用於資料湖泊的技術的原因。湖畔市集的重要任務之一就是減少您需要處理的資料量,讓大數據分析不必處理大量資料。
資料湖泊對原始資料的大量需求引發了關於隱私和安全的棘手問題。Datensparsamkeit 的原則與資料科學家現在想要擷取所有資料的渴望有很大的衝突。資料湖泊對駭客來說是一個誘人的目標,他們可能很樂意將精選的片段抽取到公海中。限制直接存取湖泊的權限給予一小群資料科學家可能會降低這個威脅,但並未避免該群組如何對其航行的資料隱私負責的問題。
備註
1: 通常的區別是資料市集是針對組織中的單一部門,而資料倉儲則整合所有部門。對於資料倉儲應該是所有資料市集的聯集,還是資料市集是資料倉儲中資料的邏輯子集(檢視),意見不一。
2: 在後續的部落格文章中,Dixon 強調了湖泊與水景花園的區別,但(在評論中)表示這是一個微小的變更。對我來說,重點是湖泊以其自然狀態儲存大量資料,饋入串流的數量並不是什麼大問題。