
簡報領域資料分層
2015 年 8 月 26 日

將資訊豐富的程式模組化的最常見方法之一,就是將其分為三個廣泛的層級:簡報 (UI)、領域邏輯 (又稱商業邏輯) 和資料存取。因此,您經常會看到網頁應用程式分為知道如何處理 HTTP 要求和呈現 HTML 的網頁層級、包含驗證和計算的商業邏輯層級,以及整理如何管理資料庫或遠端服務中持續性資料的資料存取層級。
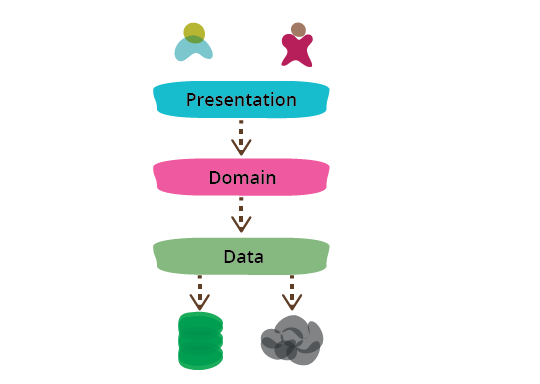
總的來說,我發現這是一種對許多應用程式而言有效的模組化形式,而且是我經常使用和鼓勵的。對我而言,它最大的優點是,它允許我縮小注意範圍,讓我能夠相對獨立地思考這三個主題。當我處理領域邏輯程式碼時,我可以大多數忽略 UI,並將與資料來源的任何互動視為一組抽象函數,這些函數提供我需要的資料,並依我的意願更新資料。當我處理資料存取層級時,我專注於將資料整理成介面所需的格式的細節。當我處理簡報時,我可以專注於 UI 行為,將任何要顯示或更新的資料視為透過函數呼叫神奇出現的。透過區分這些元素,我縮小了每個部分的思考範圍,這讓我更容易遵循我需要執行的動作。
縮小範圍並不表示對其進行程式設計有任何順序 - 我通常發現我需要在各層級之間反覆執行。我可能會根據我對 UX 的初步了解來建構資料和領域層級,但當精進 UX 時,我需要變更領域,這需要變更資料層級。但即使有這種跨層級反覆執行的動作,我發現當我進行變更時,專注於一次一個層級會比較容易。這類似於您在重構的兩頂帽子中獲得的思考模式轉換。
模組化的另一個原因是允許我替換模組的不同實作。這種分離允許我在相同的網域邏輯上建立多個簡報,而不用重複它。多個簡報可以是網路應用程式中的個別網頁,擁有網路應用程式加上行動原生應用程式、用於指令碼目的 API,甚至是老式的命令列介面。模組化資料來源允許我優雅地應對資料庫技術的變更,或支援可能在短時間內變更的持久性服務。不過我必須提到,儘管我經常聽說資料存取替換是分離資料來源層的驅動力,但我很少聽說有人實際這麼做。
模組化也支援可測試性,這自然吸引了我這個SelfTestingCode的忠實粉絲。模組邊界會公開非常適合測試的接縫。UI 程式碼通常很難測試,因此最好將儘可能多的邏輯放入網域層中,該層可以輕鬆測試,而無需透過 UI 來存取程式而進行體操[1]。資料存取通常很慢且很尷尬,因此在資料層周圍使用TestDoubles通常可以讓網域邏輯測試更容易且更具回應性。
儘管可替換性和可測試性當然是這種分層的好處,但我必須強調,即使沒有這些原因,我仍然會像這樣分層。注意力範圍縮小的原因本身就足夠了。
在討論這個問題時,我們可以將其視為一種模式(簡報-網域-資料),或將其分成兩種模式(簡報-網域和網域-資料)。這兩種觀點都很有用 - 我認為簡報-網域-資料是簡報-網域和網域-資料的複合體。
我認為這些層級是一種模組形式,這是我用來描述我們如何將軟體分組成相對獨立部分的通用詞彙。這如何對應到程式碼取決於我們所處的程式設計環境。通常,最低層級是某種形式的子常式或函式。物件導向語言將有類別的概念,用來收集函式和資料結構。大多數語言都有一些較高層級的形式,稱為套件或命名空間,通常可以形成階層結構。模組可能對應到可獨立部署的單元:函式庫或服務,但它們不必如此。
分層可以在這些層級中的任何一個層級發生。一個小型程式可能只是將不同層級的函式放入不同的檔案中。一個較大的系統可能具有對應到命名空間的層級,其中每個命名空間包含許多類別。
我在這裡提到了三個層級,但看到具有三個以上層級的架構是很常見的。一個常見的變體是在網域和簡報之間放置一個服務層級,或將簡報層級拆分為不同的層級,例如 簡報模型。我認為更多層級並不會破壞基本模式,因為核心分離仍然存在。
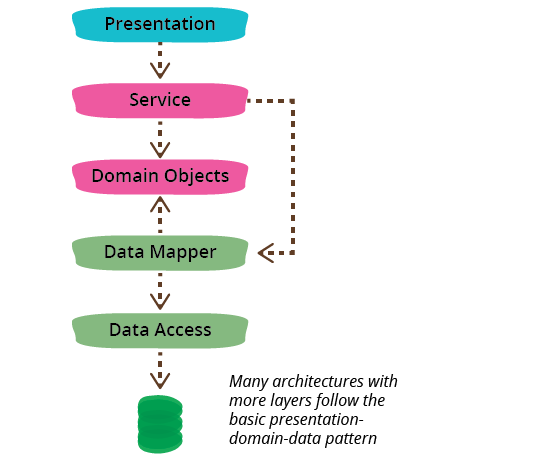
相依性通常從層級堆疊的頂端到底部:簡報依賴於網域,而網域依賴於資料來源。一個常見的變體是安排事物,使網域不依賴於其資料來源,方法是在網域和資料來源層級之間引入一個 對應器。這種方法通常稱為 六角形架構。
這些層級是邏輯層級,不是實體層級。我可以在我的筆記型電腦上執行所有三個層級,我可以在桌面上執行簡報和網域模型,資料庫則在伺服器上,我可以將簡報拆分為瀏覽器中的豐富用戶端和伺服器上的 後端到前端。在這種情況下,我將後端到前端視為簡報層級,因為它專注於支援特定的簡報選項。
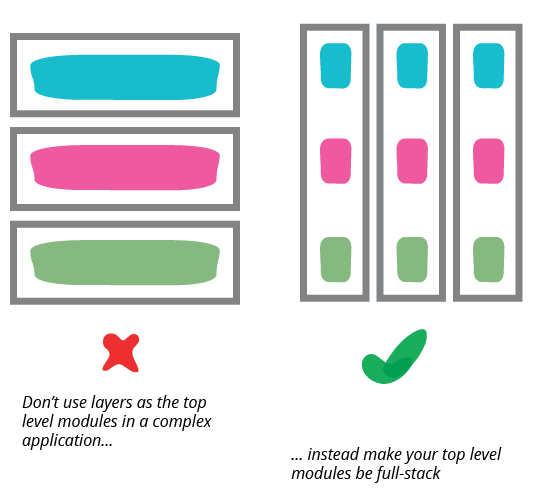
儘管簡報-網域-資料分離是一種常見的方法,但它應該只應用於相對較小的粒度。隨著應用程式的成長,每個層級都可能變得足夠複雜,以至於你需要進一步模組化。當發生這種情況時,通常最好不要使用簡報-網域-資料作為較高層級的模組。架構通常會鼓勵你將類似檢視-模型-資料的東西作為頂層命名空間;這對於較小的系統來說是可以的,但一旦這些層級中的任何一個變得太大,你應該將頂層拆分為內部分層的網域導向模組。
開發人員不必是全端開發人員,但團隊應該是。
我見過這種分層方式導致組織誤入歧途的一種常見方式是,根據這些層級來將開發團隊分開的反模式。這種方式看起來很吸引人,因為前端和後端開發需要不同的框架(甚至語言),這使得開發人員很容易專精於其中一項。將具有相同技能的人員放在一起,有助於技能共享,並允許組織將團隊視為單一、界定良好的工作類型提供者。同樣地,將所有資料庫專家放在一起,符合資料庫和架構的常見集中化。但是,這些層級之間的豐富交互作用需要在它們之間頻繁切換。當您擁有可以在團隊中輕鬆合作的專家時,這並不困難,但團隊界線會增加相當大的摩擦,並降低個人培養跨層級系統理解的重要性的動機。更糟的是,將層級分為團隊會增加開發人員和使用者之間的距離。開發人員不必是全端(儘管這是值得讚揚的),但團隊應該是全端的。
進一步閱讀
我在其他地方從許多不同的角度寫過這種分離。這種分層驅動了P of EAA的結構,而該書的第一章更詳細地討論了這種分層。我沒有在該書中將這種分層作為一個模式,但已經使用Separated Presentation和PresentationDomainSeparation來探索該領域。
有關為何簡報-網域-資料不應該是較大型系統中最高層級模組的更多資訊,請參閱Simon Brown的著作和演講。我也同意他的觀點,即軟體架構應該嵌入在程式碼中。
我與我的同事 Badri Janakiraman 進行了一場關於六角形架構性質的精彩討論。背景主要是圍繞使用 Ruby on Rails 的應用程式,但許多思考適用於您可能考慮此方法的其他情況。
致謝
James Lewis、Jeroen Soeters、Marcos Brizeno、Rouan Wilsenach 和 Sean Newham 與我討論了這篇文章的草稿。備註
1: PageObject也是一種重要的工具,有助於測試 UI。