
機器學習的持續交付
自動化機器學習應用程式的端到端生命週期
機器學習應用程式在我們的產業中正變得越來越普及,然而,與更傳統的軟體(例如網路服務或行動應用程式)相比,開發、部署和持續改善它們的流程更加複雜。它們會受到三個軸向的變更影響:程式碼本身、模型和資料。它們的行為通常很複雜且難以預測,而且更難測試、解釋和改善。機器學習的持續交付 (CD4ML) 是將持續交付原則和實務帶入機器學習應用程式的學科。
2019 年 9 月 19 日

個人簡介
我是 Thoughtworks 的一名首席顧問,在架構和工程的許多領域擁有經驗:軟體、資料、基礎架構和機器學習。我是《實務中的 DevOps:可靠且自動化的軟體交付》的作者,也是 Thoughtworks 技術諮詢委員會和 Thoughtworks CTO 辦公室的成員。

個人簡介
我是 Thoughtworks Germany 的一名顧問,負責領導我們的資料和機器學習活動。我喜歡打造具有影響力的可擴充軟體,並建立打造此類軟體的團隊。我特別著迷於如何有效地建構機器學習應用程式,這需要資料科學家和開發人員(例如我)緊密合作。

個人簡介
我是 Thoughtworks 的首席顧問,也是 Intelligent Empowerment 的全球負責人。我協助我們的客戶和 Thoughtworks 利用人工智慧和機器學習的最新技術創造價值。在取得神經網路博士學位後,我在 IT 產業待了 20 多年。我是 Thoughtworks CTO 辦公室的成員。
簡介與定義
在 Sculley 等人在 2015 年發表的 著名的 Google 論文《機器學習系統中的隱藏技術負債》中,他們強調在實際的機器學習 (ML) 系統中,只有很小一部分是由實際的 ML 程式碼組成。有大量的周圍基礎設施和程序來支援它們的演進。他們還討論了此類系統中可能會累積的許多技術負債來源,其中一些與資料依賴性、模型複雜性、可複製性、測試、監控以及處理外部世界的變化有關。
傳統軟體系統中也存在許多相同的疑慮,而 持續傳遞一直是採用自動化、品質和紀律來建立可靠且可重複的程序,以將軟體釋出至生產環境的方法。
在他們的開創性著作《持續傳遞》中,Jez Humble 和 David Farley 指出
「持續傳遞是指以安全、快速且永續的方式將所有類型的變更(包括新功能、組態變更、錯誤修正和實驗)導入生產環境或交到使用者手中。」
除了程式碼之外,用於訓練 ML 模型的模型和資料變更也是另一種需要管理並納入軟體傳遞程序的變更類型(圖 1)。
{kind=link}

圖 1:機器學習應用程式中變更的 3 個軸向(資料、模型和程式碼)以及它們變更的一些原因
考量到這一點,我們可以擴充持續傳遞定義,以納入實際機器學習系統中存在的新元素和挑戰,我們將這種方法稱為「機器學習持續傳遞 (CD4ML)」。
機器學習持續傳遞 (CD4ML) 是一種軟體工程方法,其中跨職能團隊根據程式碼、資料和模型,以小而安全的增量製作機器學習應用程式,這些增量可以在短暫的適應週期中隨時複製和可靠地釋出。
此定義包含所有基本原則
軟體工程方法:它使團隊能夠有效率地製作高品質的軟體。
跨職能團隊:具備不同技能組和工作流程的專家,橫跨資料工程、資料科學、機器學習工程、開發、營運和其他知識領域,以協作方式共同作業,強調每個團隊成員的技能和優勢。
根據程式碼、資料和機器學習模型製作軟體:ML 軟體製作程序的所有成品都需要不同的工具和工作流程,必須適當地進行版本控制和管理。
小而安全的增量:軟體成品的發布被分為小增量,這允許對其結果變異的層級進行可視化和控制,為此流程增加安全性。
可複製且可靠的軟體發布:儘管模型輸出可能是非決定性的且難以複製,但將 ML 軟體發布到生產環境的流程是可靠且可複製的,並盡可能利用自動化。
隨時發布軟體:ML 軟體隨時都能發布到生產環境中非常重要。即使組織不想要一直發布軟體,它也應該一直處於可發布的狀態。這使得關於何時發布的決策成為商業決策,而非技術決策。
短適應週期:短週期表示開發週期以天甚至小時為單位,而非週、月甚至年。內建品質的流程自動化是達成此目標的關鍵。這會建立一個回饋迴路,讓你能夠透過從其在生產環境中的行為中學習來調整模型。
在本文中,我們將描述在實作 CD4ML 時我們發現重要的技術元件,使用範例 ML 應用程式來解釋概念,並展示如何將不同的工具結合在一起來實作完整的端對端流程。在適當的地方,我們會強調我們選擇的工具的替代選擇。我們也會討論進一步的開發和研究領域,因為這個做法在我們的產業中逐漸成熟。
用於銷售預測的機器學習應用程式
我們從 2016 年開始思考如何將持續交付應用於機器學習系統,我們發布並展示一個我們與 AutoScout 合作的客戶專案案例研究,用來預測在其平台上發布的汽車價格。
不過,我們決定建立一個基於公開問題和資料集的範例 ML 應用程式來說明 CD4ML 實作,因為我們無法使用實際客戶程式碼的範例。此應用程式解決許多零售商面臨的常見預測問題:嘗試根據歷史資料預測未來特定產品的銷售量。我們建立了一個Kaggle 問題的簡化解決方案,此問題是由大型厄瓜多爾連鎖超市 Corporación Favorita 發布的。針對我們的目的,我們已經結合並簡化了他們的資料集,因為我們的目標並非找出最佳預測(這項工作更適合由資料科學家處理),而是展示如何實作 CD4ML。
使用監督式學習演算法和熱門的 scikit-learn Python 函式庫,我們使用標籤輸入資料訓練預測模型,將該模型整合到一個簡單的網路應用程式中,然後部署到雲端的生產環境中。圖 2顯示了高階流程。
{kind=link}
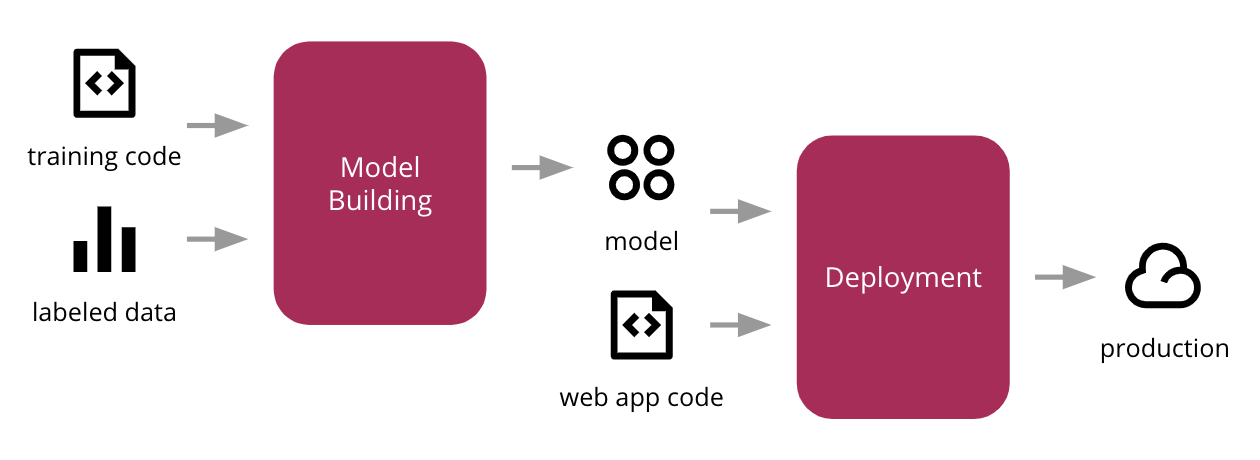
圖 2:訓練我們的 ML 模型、將其與網路應用程式整合,並部署到生產環境的初始流程
部署後,我們的網路應用程式(圖 3)允許使用者選擇產品和未來日期,而模型將輸出其對該產品在該天將售出多少單位的預測。
{kind=link}
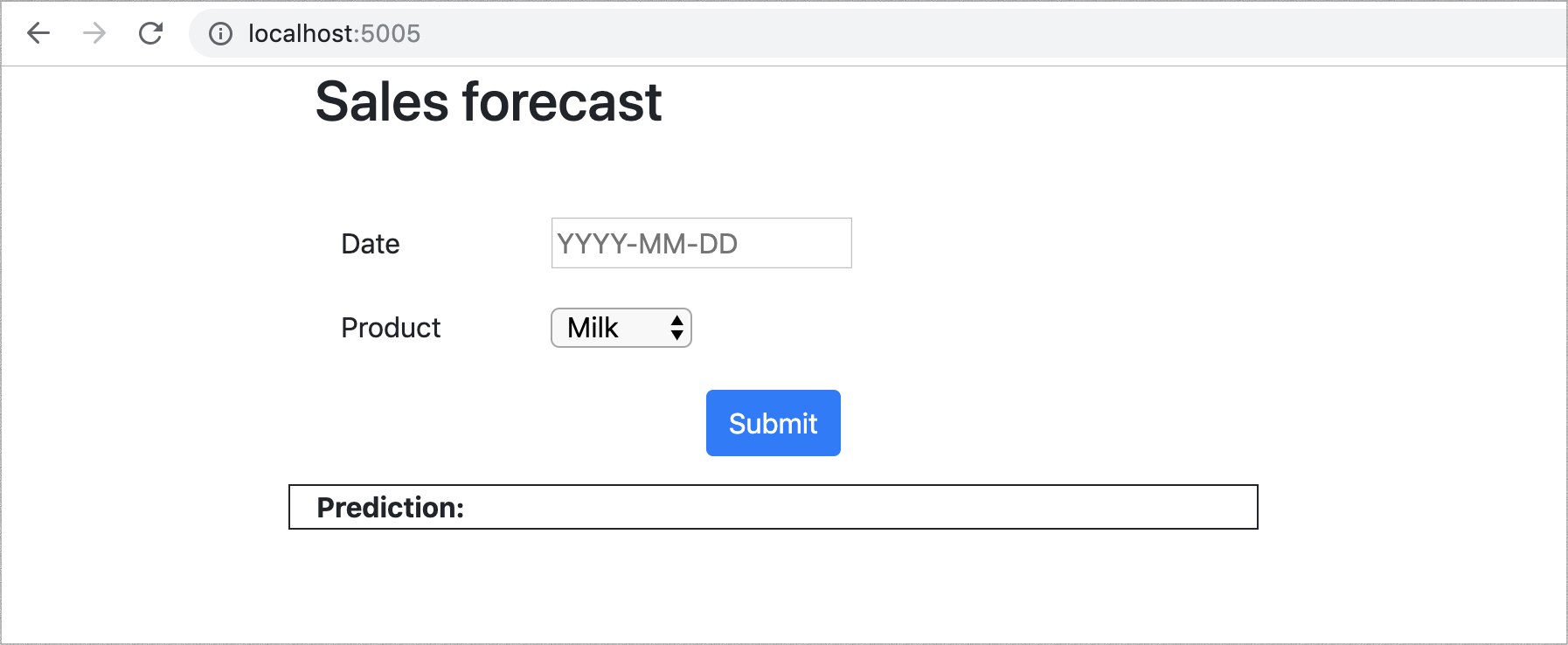
圖 3:網路 UI 展示我們的模型實際運作
常見挑戰
雖然這是我們討論的良好起點,但從頭到尾實作這個流程已經會出現兩個挑戰。第一個挑戰是組織架構:不同的團隊可能擁有流程的不同部分,而且會有交接 — 或通常是「丟過牆」— 而沒有明確的期望如何跨越這些界線(圖 4)。資料工程師可能會建立管道以使資料易於存取,而資料科學家則擔心建立和改善 ML 模型。然後,機器學習工程師或開發人員必須擔心如何整合該模型並將其發佈到生產環境。
{kind=link}
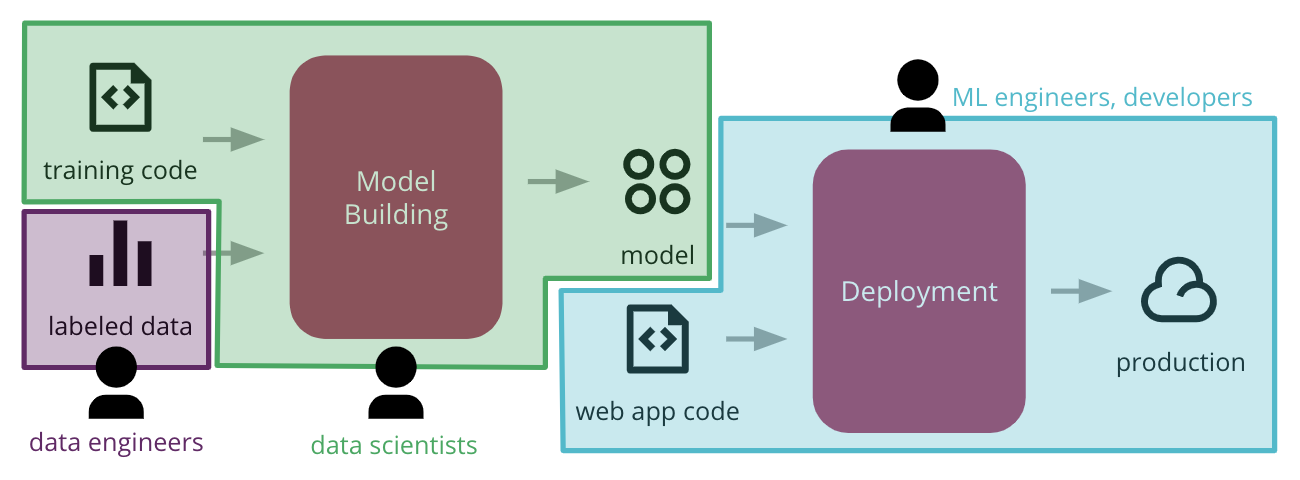
圖 4:大型組織中常見的功能性孤島會造成障礙,阻礙將 ML 應用程式部署到生產環境的端對端流程自動化的能力
這會導致延誤和摩擦。常見的症狀是只有在實驗室環境中運作且從未離開概念驗證階段的模型。或者,如果它們以手動臨時的方式進入生產環境,它們就會變得過時且難以更新。
第二個挑戰是技術性的:如何使流程可重製和可稽核。由於這些團隊使用不同的工具並遵循不同的工作流程,因此很難端對端自動化。除了程式碼之外,還有更多人工製品需要管理,而且對它們進行版本控制並不容易。其中一些人工製品可能非常龐大,需要更精密的工具才能有效率地儲存和擷取它們。
解決組織挑戰不在本文的範圍內,但我們可以從敏捷和 DevOps 中汲取教訓,並建立跨職能且以成果為導向的團隊,其中包括來自不同領域的專家,以提供端對端的 ML 系統。如果在您的組織中無法做到這一點,至少鼓勵打破這些障礙,並在整個過程中及早且經常與他們合作。
本文的其餘部分將探討我們為技術挑戰找到的解決方案。我們將深入探討每個技術元件,並逐步改善和擴充端對端流程,使其更強大。
CD4ML 的技術組成
當我們考慮如何使用機器學習解決預測問題時,第一步是了解資料集。在這種情況下,它是一組 CSV 檔案,其中包含有關
- 產品,例如其分類以及它們是否易腐
- 商店,例如它們的位置以及它們如何聚集在一起
- 特殊事件,例如公眾假期、季節性活動或 2016 年襲擊厄瓜多的 7.8 級地震
- 銷售交易,包括在給定產品、日期和地點銷售的單位數
在此階段,數據分析師和數據科學家通常會執行某種探索性數據分析 (EDA) 以了解數據的形狀,並找出廣泛的模式和異常值。例如,我們發現產品的銷售單位數為負數,我們將其解釋為退貨。由於我們只打算探索銷售,而不是退貨,因此我們將它們從我們的訓練資料集中移除。
在許多組織中,訓練有用的機器學習模型所需的數據可能不會完全按照數據科學家所需的方式進行結構化,因此它突出了第一個技術組成部分:可發現和可存取的數據。
可發現且可存取的資料
最常見的數據來源將是您的核心交易系統。然而,從組織外部引入其他數據來源也有價值。我們發現了一些收集和提供數據的常見模式,例如使用 資料湖 架構、更傳統的資料倉庫、實時數據串流集合,或者最近,我們正在嘗試使用分散的 數據網格 架構。
無論您擁有哪種類型的架構,重要的是數據易於發現和存取。數據科學家越難找到他們需要的數據,他們建立有用的模型所需的時間就越長。我們還應該考慮他們希望在輸入數據之上設計新的功能,這可能有助於提高其模型的效能。
在我們的範例中,在執行初始探索性資料分析後,我們決定將多個檔案非正規化成單一 CSV 檔案,並清除與模型無關或可能引入不必要雜訊的資料點(例如負銷售額)。然後,我們將輸出儲存在雲端儲存系統中,例如 Amazon S3、Google Cloud Storage 或 Azure Storage Account。
使用此檔案代表輸入訓練資料的快照,我們能夠根據資料夾結構和檔案命名慣例設計一個簡單的方法來為我們的資料集建立版本。資料版本控制是一個廣泛的主題,因為它可以在兩個不同的軸線上改變:結構變更至其架構,以及資料在時間上的實際抽樣。我們的資料科學家 Emily Gorcenski 在這篇部落格文章中更詳細地探討這個主題,但在文章後面的段落中,我們將討論隨著時間推移對資料集進行版本控制的其他方法。
值得注意的是,在現實世界中,你可能會有更複雜的資料管道,將資料從多個來源移至資料科學家可以存取和使用的地方。
可重製的模型訓練
資料可用後,我們進入模型建構的迭代資料科學工作流程。這通常涉及將資料分割成訓練集和驗證集,嘗試不同的演算法組合,並調整其參數和超參數。這會產生一個模型,可以根據驗證集進行評估,以評估其預測的品質。此模型訓練程序的逐步流程成為機器學習管道。
在圖 5中,我們展示了我們如何為我們的銷售預測問題建構 ML 管道,重點說明不同的原始碼、資料和模型元件。輸入資料、中間訓練和驗證資料集,以及輸出模型可能都是大型檔案,我們不希望將它們儲存在原始碼控制儲存庫中。此外,管道的階段通常會持續變更,這使得在資料科學家本地環境之外複製它們變得困難。
{kind=link}
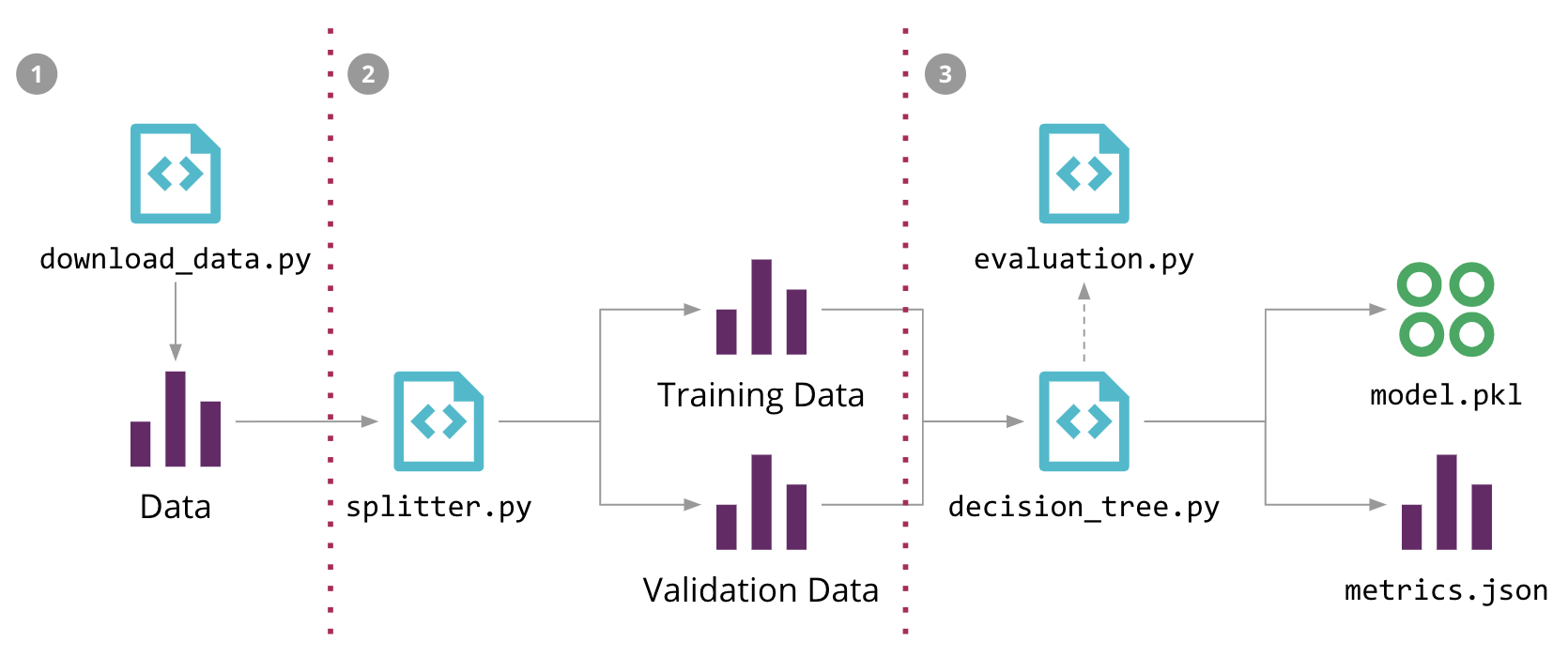
圖 5:我們的銷售預測問題的機器學習管道,以及使用 DVC 自動化它的 3 個步驟
為了在程式碼中將模型訓練流程正規化,我們使用了稱為 DVC(資料科學版本控制)的開源工具。它提供與 Git 類似的語意,但也能解決一些特定於 ML 的問題
- 它有許多後端外掛程式,可以在源控制儲存庫外部的外部儲存空間中擷取和儲存大型檔案;
- 它可以追蹤這些檔案的版本,讓我們在資料變更時重新訓練我們的模型;
- 它追蹤用於執行 ML 管道的依存關係圖和指令,讓這個流程可以在其他環境中重製;
- 它可以與 Git 分支整合,讓多個實驗並存;
例如,我們可以在 圖 5 中使用三個 dvc run 指令來設定我們的初始 ML 管道(-d 指定依存關係,-o 指定輸出,-f 是要記錄該步驟的檔案名稱,而 -M 是產生的指標)
dvc run -f input.dvc \ ➊ -d src/download_data.py -o data/raw/store47-2016.csv python src/download_data.py dvc run -f split.dvc \ ➋ -d data/raw/store47-2016.csv -d src/splitter.py \ -o data/splitter/train.csv -o data/splitter/validation.csv python src/splitter.py dvc run ➌ -d data/splitter/train.csv -d data/splitter/validation.csv -d src/decision_tree.py \ -o data/decision_tree/model.pkl -M results/metrics.json python src/decision_tree.py
每個執行都會建立一個對應的檔案,這個檔案可以提交到版本控制中,而且讓其他人可以透過執行 dvc repro 指令來重製整個 ML 管道。
一旦我們找到一個合適的模型,我們會將它視為一個需要進行版本控制和部署到生產環境的成品。使用 DVC,我們可以使用 dvc push 和 dvc pull 指令來發佈和從外部儲存空間中擷取它。
還有其他開源工具可以解決這些問題:Pachyderm 使用容器來執行管道的不同步驟,而且也透過追蹤資料提交和根據它來最佳化管道執行,來解決資料版本控制和資料來源問題。MLflow Projects 定義了一個檔案格式來指定環境和管道的步驟,而且提供了一個 API 和一個 CLI 工具來在本地或遠端執行專案。我們選擇 DVC,是因為它是一個簡單的 CLI 工具,可以很好地解決這個問題的一部分。
模型服務
一旦找到一個合適的模型,我們需要決定它將如何在生產環境中提供服務和使用。我們已經看到一些模式可以達成這個目標
- 嵌入式模型:這是較為簡單的方法,您將模型成品視為一個依存關係,在使用應用程式內部建置和封裝。從這個點開始,您可以將應用程式成品和版本視為應用程式程式碼和所選模型的組合。
- 模型部署為一個獨立的服務:在這種方法中,模型會包裝在一個服務中,可以獨立於使用應用程式部署。這允許模型更新可以獨立發佈,但它也可能在推論時間引入延遲,因為每個預測都需要某種形式的遠端呼叫。
- 模型發布為資料:在此方法中,模型也獨立處理並發布,但使用應用程式會在執行期間將其作為資料擷取。我們已看到這用於串流/即時場景,其中應用程式可以訂閱在每次發布新模型版本時發布的事件,並在繼續使用前一版本進行預測時將其擷取到記憶體中。軟體發布模式,例如 藍綠部署 或 金絲雀發布 也可用於此場景。
在我們的範例中,我們決定使用較簡單的嵌入模型方法,因為我們的使用應用程式也是用 Python 編寫的。我們的模型會匯出為序列化物件(pickle 檔案),並由 DVC 推送到儲存空間。在建置我們的應用程式時,我們會將其拉取並嵌入到同一個 Docker 容器中。從那時起,Docker 映像會成為我們的應用程式+模型人工製品,並會進行版本控管並部署到製作環境。
除了使用 pickle 序列化模型物件之外,還有其他工具選項可實作嵌入模型模式。MLeap 提供一個共用序列化格式,用於匯出/匯入 Spark、scikit-learn 和 Tensorflow 模型。還有一些與語言無關的交換格式可供分享模型,例如 PMML、PFA 和 ONNX。其中一些序列化選項也適用於實作「模型作為資料」模式。
另一種方法是使用 H2O 等工具,將模型匯出為 JAR Java 函式庫中的 POJO,然後您可以將其新增為應用程式中的相依性。此方法的好處是,您可以使用資料科學家熟悉的語言(例如 Python 或 R)訓練模型,並將模型匯出為在不同目標環境 (JVM) 中執行的已編譯二進位檔,這可以在推論時間加快速度。
為了實作「模型作為服務」模式,許多雲端供應商都有工具和 SDK,可包裝您的模型以部署到他們的 MLaaS(機器學習即服務)平台,例如 Azure Machine Learning、AWS Sagemaker 或 Google AI Platform。另一種選擇是使用 Kubeflow 等工具,這是一個專門設計用於在 Kubernetes 上部署機器學習工作流程的專案,儘管它試圖解決的不只是模型服務的部分問題。
MLflow 模型 嘗試提供一種標準方法來封裝不同風味的模型,供不同的下游工具使用,有些使用「模型作為服務」,有些使用「嵌入模型」模式。簡而言之,這是一個當前的開發領域,各種工具和供應商正努力簡化這項任務。但這表示還沒有明確的標準(開放或專有)可以被視為明確的贏家,因此您需要評估適合您需求的正確選項。
值得注意的是,無論您決定使用哪種模式,模型與其使用者之間始終存在隱含的合約。模型通常會預期輸入資料具有某種形狀,如果資料科學家變更合約以要求新的輸入或新增新功能,您可能會造成整合問題並中斷使用它的應用程式。這將引導我們討論測試的主題。
機器學習中的測試和品質
在 ML 工作流程中可以引入不同類型的測試。雖然某些方面本質上是不確定的且難以自動化,但有許多類型的自動化測試可以增加價值並改善 ML 系統的整體品質
- 驗證資料:我們可以新增測試來驗證輸入資料是否符合預期的架構,或驗證我們對其有效值的假設,例如它們落在預期的範圍內,或不為空值。對於設計的功能,我們可以撰寫單元測試來檢查它們是否計算正確,例如數值功能已縮放或正規化,獨熱編碼向量包含所有零和單一 1,或適當地替換遺失值。
- 驗證元件整合:我們可以使用類似的方法來測試不同服務之間的整合,使用 合約測試 來驗證預期的模型介面是否與使用應用程式相容。當您的模型以不同的格式製成時,另一種類型的測試是相關的,以確保匯出的模型仍產生相同的結果。這可以透過針對相同的驗證資料集執行原始模型和製成模型,並比較結果是否相同來達成。
- 驗證模型品質:雖然 ML 模型效能是不確定的,但資料科學家通常會收集和監控許多指標來評估模型的效能,例如錯誤率、準確度、AUC、ROC、混淆矩陣、精確度、召回率等。它們在參數和超參數最佳化期間也很有用。作為一個簡單的品質閘門,我們可以使用這些指標在我們的管線中引入 閾值測試 或 棘輪,以確保新模型不會針對已知的效能基準線而降低。
- 驗證模型偏差和公平性:雖然我們可能在整體測試和驗證資料集上獲得良好的效能,但檢查模型針對特定資料切片的基準線的效能也很重要。例如,您可能在訓練資料中具有固有的偏差,其中與實際世界中的實際分佈相比,某個特徵值(例如種族、性別或地區)的資料點多得多,因此檢查不同資料切片的效能非常重要。像 Facets 這樣的工具可以幫助您視覺化這些切片和資料集中特徵中值的分布。
在我們的範例應用程式中,Favorita 定義的 評估指標 是正規化的錯誤率。我們撰寫了一個簡單的 PyUnit 閾值測試,如果錯誤率超過 80%,則會中斷,這個測試可以在發布新模型版本之前執行,以展示我們如何防止不良模型被推廣。
雖然這些是較容易自動化的測試範例,但更全面地評估模型品質較為困難。隨著時間推移,如果我們總是針對相同的資料集計算指標,我們可能會開始過度擬合。當您有其他模型已經上線時,您需要確保新模型版本不會對未見過的資料造成損害。因此,管理和整理測試資料變得更加重要[2]。
當模型被分發或匯出供不同應用程式使用時,您也可以發現訓練和服務時間之間以不同方式計算工程化特徵的問題。一種有助於找出此類問題的方法是,將後備資料集與模型人工製品一起分發,並允許使用應用程式團隊在整合後重新評估模型針對後備資料集的效能。這將等同於傳統軟體開發中的廣泛整合測試。
也可以考慮其他類型的測試,但我們認為在部署管道中加入一些手動階段也很重要,以顯示有關模型的資訊,並允許人類決定是否應推廣這些模型。這允許您建構機器學習治理程序,並引入模型偏差、模型公平性的檢查,或收集可解釋性資訊,供人類瞭解模型的行為方式。
隨著更多類型的測試,它將使您重新思考測試金字塔的形狀:您可以考慮為每種類型的人工製品(程式碼、模型和資料)建立獨立的金字塔,但也可以考慮如何將它們結合起來,如圖 6所示。總體而言,ML 系統的測試和品質較為複雜,應成為另一篇深入的獨立文章的主題。
{kind=link}
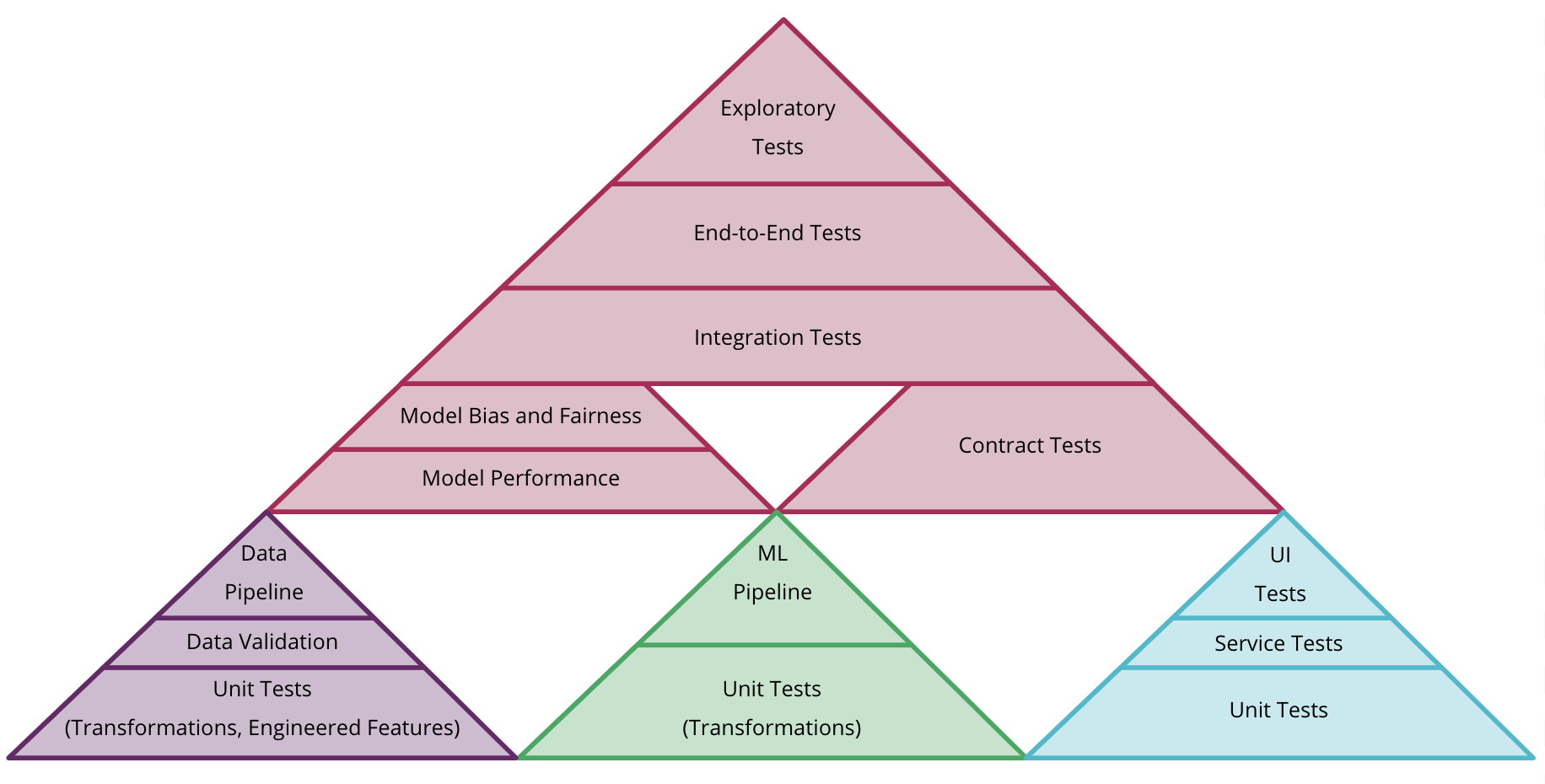
圖 6:在 CD4ML 中結合資料、模型和程式碼的不同測試金字塔的範例
實驗追蹤
為了支援此治理程序,擷取和顯示資訊非常重要,這些資訊將允許人類決定是否應將哪個模型推廣到生產環境。由於資料科學程序非常以研究為中心,因此您通常會同時嘗試多項實驗,其中許多實驗可能永遠無法投入生產。
研究階段中的這種實驗方法不同於較為傳統的軟體開發流程,因為我們預期許多這些實驗的程式碼將會被丟棄,而只有少數幾項會被認為值得導入生產環境。因此,我們需要定義一種追蹤它們的方法。
在我們的案例中,我們決定採用 DVC 建議的方法,使用不同的 Git 分支來追蹤原始碼控制中的不同實驗。即使這與我們在單一主幹上實作 持續整合 的偏好相違背。DVC 可以擷取並顯示在不同分支或標籤中執行的實驗指標,讓在它們之間導覽變得容易。
在傳統軟體開發中,使用 功能分支 進行開發的一些缺點是,如果分支存在時間過長,可能會造成合併困難,它可能會阻止團隊更積極地進行重構,因為變更可能會影響程式碼庫的更廣泛區域,而且它會阻礙 持續整合 (CI) 的實作,因為它會強迫您為每個分支設定多個工作,而且適當的整合會延遲到程式碼合併回主線為止。
對於 ML 實驗,我們預期大多數分支永遠不會被整合,而且實驗之間的程式碼差異通常並不明顯。從 CI 自動化的角度來看,我們實際上確實希望為每個實驗訓練多個模型,並收集指標,這些指標將告訴我們哪個模型可以移至部署管線的下一階段。
除了 DVC 之外,我們用來協助實驗追蹤的另一個工具是 MLflow 追蹤。它可以部署為託管服務,並提供 API 和網路介面來視覺化多個實驗執行,以及它們的參數和效能指標,如 圖 7 所示。
{kind=link}
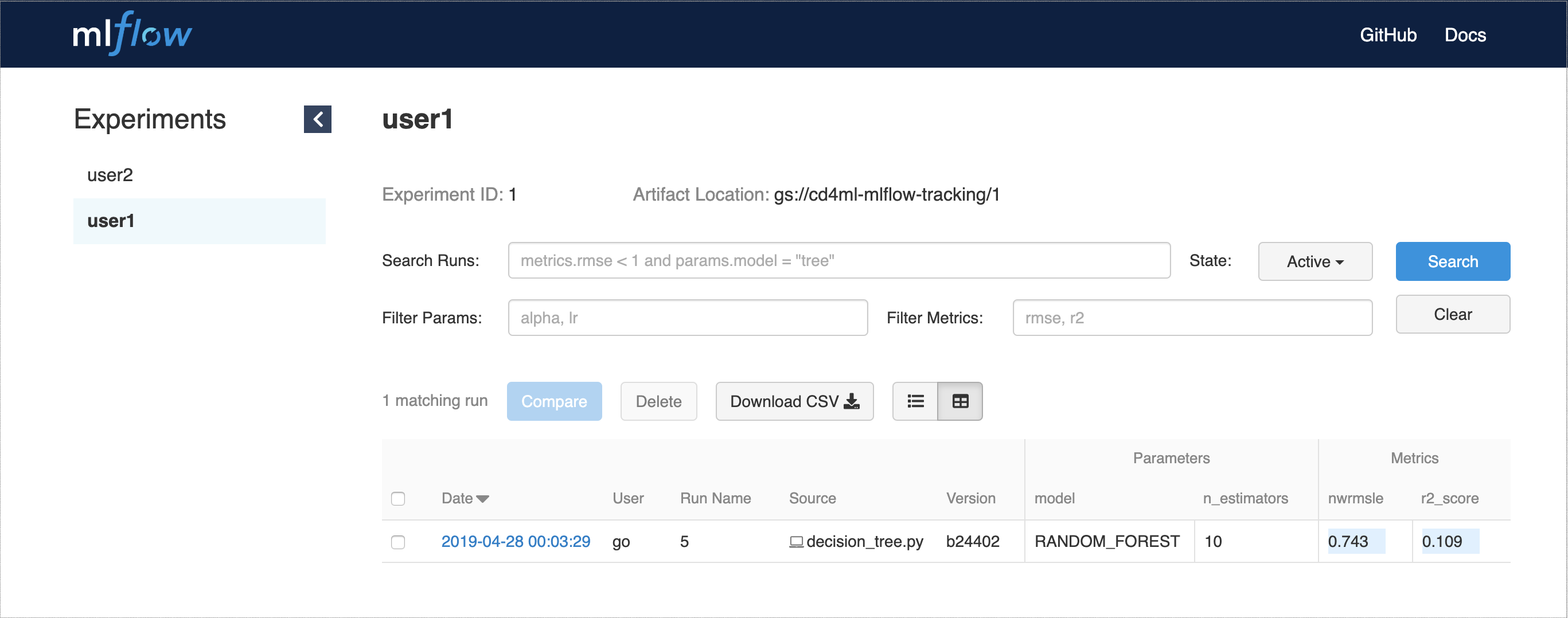
圖 7:MLflow 追蹤網路 UI,用於顯示實驗執行、參數和指標
為了支援這個實驗流程,強調擁有彈性基礎架構的好處也很重要,因為您可能需要多個環境可用,而且有時需要專用硬體來進行訓練。基於雲端的基礎架構非常適合這一點,而且許多公有雲端供應商正在建置服務和解決方案來支援這個流程的各個方面。
模型部署
在我們的簡單範例中,我們僅實驗建立單一模型,將其嵌入並與應用程式一起部署。在實際情況中,部署可能會構成更複雜的場景
- 多個模型:有時您可能有多個模型執行相同的任務。例如,我們可以訓練模型來預測每個產品的需求。在這種情況下,將模型部署為單獨的服務可能更適合使用應用程式來透過單一 API 呼叫取得預測。稍後,您可以演進在該已發佈介面背後需要多少模型。
- 影子模型:在考慮替換生產中的模型時,此模式很有用。您可以將新模型與目前的模型並排部署,作為影子模型,並傳送相同的生產流量來收集資料,了解影子模型在推廣之前執行的情況。
- 競爭模型:較為複雜的場景是當您在生產中嘗試模型的多個版本(例如 A/B 測試)以找出哪一個較佳。此處新增的複雜性來自於確保流量被重新導向至正確模型所需的基本架構和路由規則,而且您需要收集足夠的資料才能做出具有統計意義的決策,這可能需要一些時間。評估多個競爭模型的另一種熱門方法是多重拉霸機,這也要求您定義一種方式來計算和監控與使用每個模型相關的獎勵。將這套用於機器學習是一個積極的研究領域,我們開始看到一些工具和服務出現,例如Seldon core和Azure Personalizer 。
- 線上學習模型:與我們迄今討論的模型(在離線訓練並在線上用於提供預測)不同,線上學習模型使用演算法和技術,可以隨著新資料的出現持續改善其效能。它們在生產中持續學習。這會造成額外的複雜性,因為將模型版本化為靜態人工製品如果沒有提供相同的資料,將不會產生相同的結果。您不僅需要對訓練資料進行版本控制,還需要對會影響模型效能的生產資料進行版本控制。
再次強調,為了支援更複雜的部署場景,您將受益於使用彈性基礎架構。除了讓這些多個模型可以在生產中執行之外,它還允許您在需要時啟動更多基礎架構來改善系統的可靠性和可擴充性。
持續交付編排
在所有主要建構區塊就位後,需要將所有內容串聯在一起,而這正是我們的持續交付編排工具發揮作用的地方。此領域中有許多工具選項,其中大多數提供配置和執行 部署管道 的方法,以建置和釋出軟體至生產環境。在 CD4ML 中,我們有額外的編排需求:提供基礎設施和執行機器學習管道以訓練和擷取多個模型實驗的指標;我們的資料管道的建置、測試和部署流程;決定要推廣哪些模型的不同類型測試和驗證;提供基礎設施和將我們的模型部署到生產環境。
我們選擇使用 GoCD 作為我們的持續交付工具,因為它是以管道概念作為首要考量而建置的。不僅如此,它還允許我們透過結合不同的管道、其觸發器,以及定義管道階段之間的手動或自動推廣步驟,來配置複雜的工作流程和依賴關係。
在我們的簡化範例中,我們尚未建置任何複雜的資料管道或基礎設施提供,但我們展示如何結合兩個 GoCD 管道,如 圖 8 所示
{kind=link}
- 機器學習管道:在 GoCD 代理中執行模型訓練和評估,以及執行基本閾值測試以決定是否可以推廣模型。如果模型良好,我們執行
dvc push命令將其發布為成品。 - 應用程式部署管道:建置和測試應用程式程式碼,使用
dvc pull從上游管道擷取已推廣的模型,封裝一個新的結合成品,其中包含模型和應用程式作為 Docker 映像,並將其部署到 Kubernetes 生產叢集。
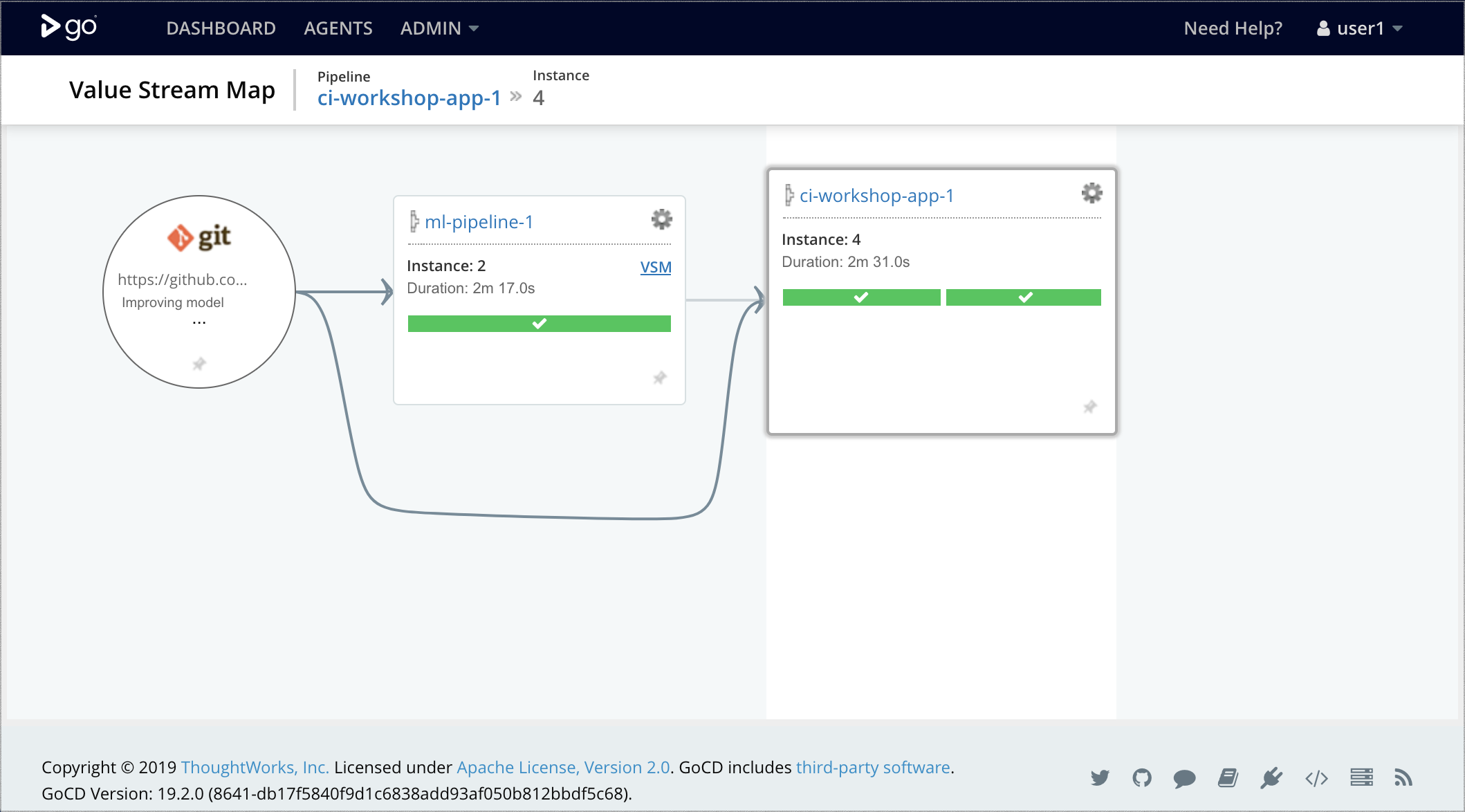
圖 8:在 GoCD 中結合機器學習管道和應用程式部署管道
隨著時間推移,ML 管道可以擴充為並行執行多個實驗(GoCD 的扇出/扇入模型支援的功能),並定義模型治理程序,以檢查偏差、公平性、正確性和其他類型的閘門,以做出明智的決策,決定將哪個模型推廣並部署到生產環境。
最後,持續交付編排的另一個面向是定義回滾程序,以防部署的模型在生產環境中執行不佳或不正確。這會在整體程序中增加另一個安全網。
模型監控和可觀察性
現在模型已上線,我們需要了解它在生產環境中的執行狀況,並封閉資料回饋迴路。在此,我們可以重複使用所有監控和可觀察性基礎架構,這些基礎架構可能已就緒,可用於您的應用程式和服務。
日誌聚合和指標收集工具通常用於擷取來自商業 KPI、軟體可靠性和效能指標、疑難排解除錯資訊等即時系統的資料,以及在發生異常情況時觸發警示的其他指標。我們也可以利用這些相同工具來擷取資料,以了解模型的行為方式,例如
- 模型輸入:提供給模型的資料為何,讓您能了解任何訓練與服務偏差。模型輸出:模型根據這些輸入做出哪些預測和建議,以了解模型如何使用實際資料執行。
- 模型可解釋性輸出:指標,例如模型係數、ELI5 或 LIME 輸出,允許進一步調查,以了解模型如何做出預測,以找出訓練期間未發現的潛在過度擬合或偏差。
- 模型輸出和決策:我們的模型根據生產輸入資料做出的預測為何,以及根據這些預測做出的決策為何。有時,應用程式可能會選擇忽略模型,並根據預先定義的規則做出決策(或避免未來的偏差)。
- 使用者動作和獎勵:根據進一步的使用者動作,我們可以擷取獎勵指標,以了解模型是否產生預期的效果。例如,如果我們顯示產品建議,我們可以追蹤使用者決定購買建議產品作為獎勵的時間。
- 模型公平性:分析輸入資料和輸出預測,並針對可能造成偏差的已知特徵,例如種族、性別、年齡、收入群組等。
在我們的範例中,我們使用 EFK 堆疊進行監控和可觀察性,它由三個主要工具組成
- Elasticsearch:一個開源搜尋引擎。
- FluentD:一個開源資料收集器,用於統一的記錄層。
- Kibana:一個開放原始碼的網路使用者介面,讓探索和視覺化 Elasticsearch 編製索引的資料變得容易。
我們可以為我們的應用程式碼進行工具化,將模型輸入和預測記錄為 FluentD 中的事件
predict_with_logging.py…
df = pd.DataFrame(data=data, index=['row1'])
df = decision_tree.encode_categorical_columns(df)
pred = model.predict(df)
logger = sender.FluentSender(TENANT, host=FLUENTD_HOST, port=int(FLUENTD_PORT))
log_payload = {'prediction': pred[0], **data}
logger.emit('prediction', log_payload)
然後這個事件會被轉發並編製索引於 ElasticSearch,而我們可以使用 Kibana 透過網路介面查詢和分析它,如 圖 9 所示。
{kind=link}

圖 9:在 Kibana 中分析我們模型的預測與真實輸入資料
還有其他熱門的監控和可觀察性工具,例如 ELK 堆疊(一種使用 Logstash 而非 FluentD 來進行記錄擷取和轉發的變體)、Splunk 等。
當您在製作環境中部署多個模型時,收集監控和可觀察性資料變得更為重要。例如,您可能有一個影子模型來評估,您可能正在執行分割測試,或執行具有多個模型的多臂老虎機實驗。
如果您正在邊緣訓練或執行聯合模型(例如在使用者的行動裝置上),或者如果您正在部署 線上學習模型,隨著它們從製作環境中的新資料中學習而隨著時間推移而產生差異,這也與您相關。
透過擷取這些資料,您可以關閉資料回饋迴路。這是透過收集更多真實資料(例如在定價引擎或推薦系統中)來達成,或者透過在迴路中加入人為因素來分析從製作環境中擷取的新資料,並策劃它以建立新的訓練資料集,用於新的和改良的模型。關閉這個回饋迴路是 CD4ML 的主要優點之一,因為它允許我們根據從真實製作資料中獲得的學習來調整我們的模型,建立一個持續改善的流程。
端到端的 CD4ML 流程
透過逐步解決每個技術挑戰,並使用各種工具和技術,我們設法建立了 圖 10 中所示的端對端流程,它管理跨所有三個軸(程式碼、模型和資料)的成品推廣。
{kind=link}
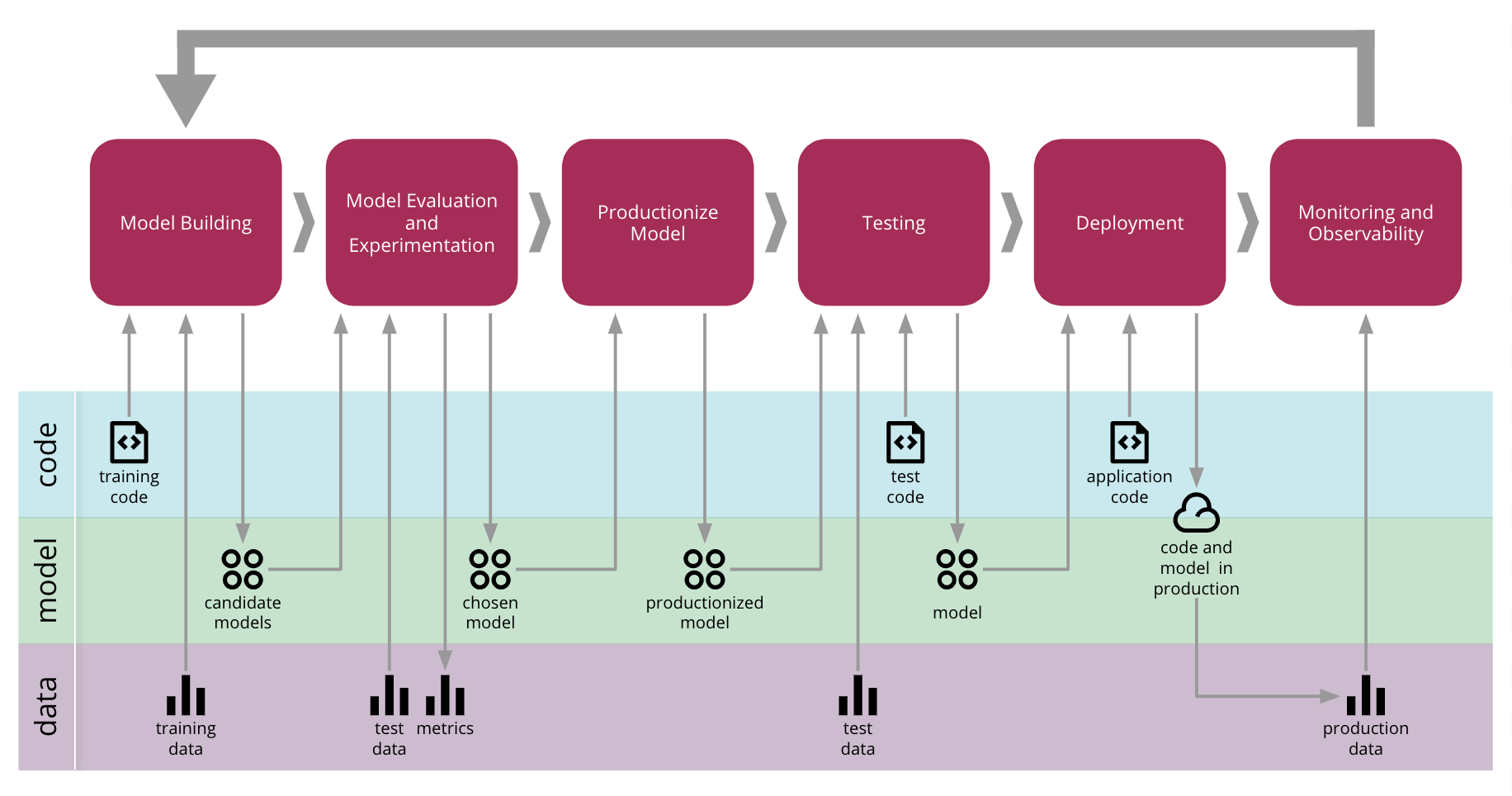
圖 10:機器學習端對端流程的持續傳遞
在基礎上,我們需要一個簡單的方法來管理、發現、存取和建立我們資料的版本。然後我們自動化模型建構和訓練流程,使其可重製。這讓我們能夠實驗和訓練多個模型,這帶來了衡量和追蹤這些實驗的需求。一旦我們找到一個合適的模型,我們就可以決定如何將它製成產品和提供服務。由於模型會演進,我們必須確保它不會與其使用者中斷任何合約,因此我們需要在部署到製作環境之前測試它。一旦在製作環境中,我們可以使用監控和可觀察性基礎架構來收集新的資料,這些資料可以被分析並用於建立新的訓練資料集,關閉持續改善的回饋迴路。
持續傳遞編排工具協調端對端的 CD4ML 程序,依需求提供所需的基礎設施,並管理模型和應用程式如何部署到生產環境。
接下來的步驟是什麼?
我們在本文中使用的範例應用程式和程式碼可在我們的 Github 儲存庫 中取得,並作為我們在各種會議和客戶處展示的半日工作坊的基礎。我們持續發展關於如何實作 CD4ML 的想法。在本節中,我們最後強調一些工作坊材料中未反映出的改進領域,以及一些需要進一步探討的開放領域。
資料版本控制
在持續傳遞中,我們將每個程式碼提交視為候選版本,它會觸發部署管線的新執行。假設提交通過所有管線階段,就可以部署到生產環境。在討論 CD4ML 時,我們收到的常見問題之一是「資料變更時,我如何觸發管線?」
在我們的範例中,圖 5 中的機器學習管線從 download_data.py 檔案開始,此檔案負責從共用位置下載訓練資料集。如果我們變更共用位置中資料集的內容,它不會立即觸發管線,因為程式碼沒有變更,DVC 也無法偵測到它。要對資料進行版本控制,我們必須建立新檔案或變更檔名,而這反過來又要求我們使用新路徑更新 download_data.py 指令碼,因此建立新的程式碼提交。
對此方法的改進將是允許 DVC 追蹤我們的檔案內容,方法是用以下內容取代我們手寫的下載指令碼
dvc add data/raw/store47-2016.csv ➊
這會稍微變更機器學習管線的第一個步驟,如 圖 11 所示。
{kind=link}
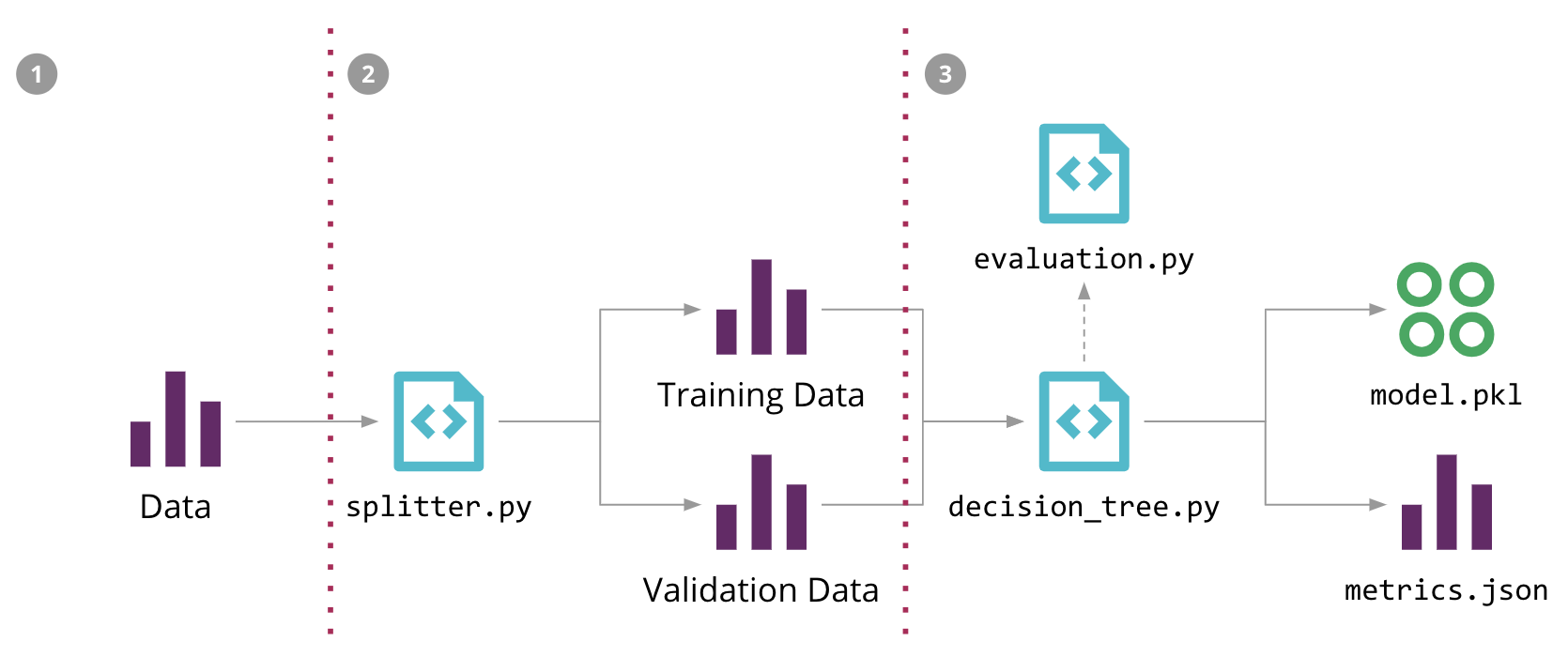
圖 11:更新第一步以允許 DVC 追蹤資料版本並簡化機器學習管線
這會建立一個追蹤檔案內容雜湊值的元資料檔案,我們可以將其提交到 Git。現在,當檔案內容變更時,雜湊值會變更,DVC 會更新該元資料檔案,這將是我們觸發管線執行的提交。
雖然這允許我們在資料變更時重新訓練模型,但並未說明資料版本控制的完整故事。一個面向是資料歷程記錄:理想情況下,您會希望保留所有資料變更的完整歷程記錄,但這並非總是可行,具體取決於資料變更的頻率。另一個面向是資料來源:了解哪個處理步驟導致資料變更,以及它如何在不同的資料集間傳播。還有一個問題是隨著時間推移追蹤和發展資料架構,以及這些變更是否向前和向後相容。
如果您處於串流世界,那麼這些資料版本控制的面向將變得更難以推論,因此這是我們預期更多實務、工具和技術演進的領域。
資料管線
另一個我們尚未涵蓋的面向是如何對資料管道本身進行版本控制、測試、部署和監控。在現實世界中,某些工具選項優於其他選項,以啟用 CD4ML。例如,許多需要您透過 GUI 定義轉換和處理步驟的 ETL 工具,通常不容易進行版本控制、測試或部署到混合式環境。其中一些工具可以產生您可以視為人工製品的程式碼,並透過部署管道執行。
我們傾向偏好開放原始碼工具,這些工具允許我們在程式碼中定義資料管道,這更容易進行版本控制、測試和部署。例如,如果您使用 Spark,您的資料管道可能會以 Scala 編寫,您可以使用 ScalaTest 或 spark-testing-base 進行測試,您可以將工作打包成 JAR 人工製品,該人工製品可以在 GoCD 中的部署管道中進行版本控制和部署。
由於資料管道通常以批次作業或長時間執行的串流應用程式執行,因此我們未將它們包含在 圖 10 中的端對端 CD4ML 流程圖中,但如果它們變更您的模型或應用程式預期的輸出,它們也是另一個潛在的整合問題來源。因此,我們努力將整合和資料 合約測試 納入我們的部署管道中,以找出這些錯誤。
與資料管道相關的另一種測試類型是資料品質檢查,但這可能會成為另一個廣泛的討論主題,而且可能比較適合在單獨的文章中涵蓋。
平台思維
您可能已經注意到,我們使用各種工具和技術來實作 CD4ML。如果您有多個團隊嘗試執行此操作,他們可能會重新發明事物或重複工作。這正是平台思維發揮作用的地方。不是將所有工作集中在一個團隊中,使其成為瓶頸,而是將平台工程工作重點放在建構與領域無關的工具上,以隱藏基礎複雜性並加快團隊採用它的速度。我們的同事 Zhamak Dehghani 在她的 資料網格 文章中更詳細地涵蓋了這一點。
將平台思維應用於 CD4ML 是我們看到對機器學習平台和其他產品興趣日益濃厚的原因,這些產品試圖提供單一解決方案來管理端對端的機器學習生命週期。許多主要的科技巨頭都開發了自己的內部工具,但我們相信這是一個積極的研究和開發領域,並預期會有新的工具和供應商出現,提供可以更廣泛採用的解決方案。
在沒有偏見的情況下開發智慧系統
當您的第一個機器學習系統部署到生產環境後,它將開始進行預測並用於處理未見過的資料。它甚至可能取代您之前建立的基於規則的系統。重要的是要了解,您所執行的訓練資料和模型驗證是基於歷史資料,其中可能包含基於先前系統行為的固有偏差。此外,您的 ML 系統對使用者未來的任何影響也將影響您未來的訓練資料。
讓我們考慮兩個範例來了解影響。首先,讓我們考慮我們在本文中探討的需求預測解決方案。假設有一個應用程式會採用預測需求來決定要訂購和提供給客戶的產品確切數量。如果預測需求低於實際需求,您將沒有足夠的商品可供銷售,因此該產品的交易量會減少。如果您只使用這些新的交易作為訓練資料來改善您的模型,隨著時間的推移,您的需求預測將會下降。
對於第二個範例,想像一下您正在建立一個異常偵測模型,以判斷客戶的信用卡交易是否為詐騙。如果您的應用程式採用模型決策來封鎖他們,隨著時間的推移,您將僅對模型允許的交易擁有「真實標籤」,而較少的詐騙交易可供訓練。模型的效能也會下降,因為訓練資料會偏向「良好」交易。
這個問題沒有簡單的解決方案。在我們的第一個範例中,零售商也會考慮缺貨情況,並訂購比預測更多的商品以彌補潛在的短缺。對於詐騙偵測場景,我們可以有時忽略或覆寫模型的分類,使用一些機率分佈。同樣重要的是要了解,許多資料集都是時間性的,也就是說它們的分布會隨著時間而改變。許多執行資料隨機分割的驗證方法假設它們是 i.i.d.(獨立同分布),但一旦您考慮時間的影響,這就不成立了。
因此,重要的是不僅要擷取模型的輸入/輸出,還要擷取使用應用程式採取的最終決策,以使用或覆寫模型的輸出。這允許您註解資料以避免在未來的訓練回合中出現這種偏差。管理訓練資料並建立允許人類管理訓練資料的系統是您在面對這些問題時需要的另一個關鍵組成部分。
隨著時間的推移,開發出一個智慧系統來選擇和改善 ML 模型也可以視為元學習問題。此領域的許多最先進研究都專注於這些類型的問題。例如,使用強化學習技術,例如多臂老虎機或線上學習在生產環境中。我們預計我們在如何最佳建立、部署和監控這些類型的 ML 系統方面的經驗和知識將持續發展。
結論
隨著機器學習技術持續發展並執行更複雜的任務,我們對如何管理和提供此類應用程式到生產環境的知識也在不斷發展。透過導入和擴充持續交付的原則和實務,我們可以更好地管理以安全可靠的方式釋出變更到機器學習應用程式的風險。
使用範例銷售預測應用程式,我們在本文中展示了 CD4ML 的技術元件,並討論了我們如何實作它們的一些方法。我們相信此技術將持續演進,新工具會出現並消失,但持續交付的核心原則仍然相關,且是您應為自己的機器學習應用程式考慮的重點。
致謝
首先,感謝 Martin Fowler 協助我們重新定義本文的敘述和結構,並提供主辦。
特別感謝許多現任和前任 ThoughtWorkers,他們透過我們的研討會和客戶工作協助我們建立和提煉本文中的構想,包括 Arun Manivannan、Danni Yu、David Tan、Emily Gorcenski、Emma Grasmeder、Jin Yang、Jonathan Heng 和 Juan López。
另外感謝以下早期審閱者,他們針對本文的第一個草稿提供了寶貴的回饋:Chris Ford、Fabio Kung、Fernando Meyer、Guilherme Silveira、Kyle Hodgson 和 Rodrigo Kumpera。
註腳
1: AutoML 致力於建立方法和工具,以自動化機器學習開發流程中的許多步驟。
2: ease.ml/ci 和 ease.ml/meter 等工具和系統的積極研究,有助於管理和了解何時需要新的測試資料,或何時模型過度擬合。
重大修訂
2019 年 9 月 19 日:發布最終分期
2019 年 9 月 18 日:發布資料版本控制和資料管線分期
2019 年 9 月 11 日:發布編排和可觀察性分期。
2019 年 9 月 09 日:發布實驗追蹤和模型部署分期。
2019 年 9 月 06 日:發布模型服務和測試分期
2019 年 9 月 04 日:發布可發現資料和可重製訓練分期
2019 年 9 月 03 日:發布第一個分期:簡介和挑戰